補足 ソフトウェアを準備する**#
本書では統計分析用ソフトの「statsmodels」、数値解析用ソフトの「SciPy」、機械学習用のソフトの「scikit-learn」をしばしば活用します。この節では「statsmodels」の使い方とサンプルデータについて簡単にまとめておきます。SciPy,scikit-learnについては特にまとめていませんがサンプルコードのなかで適宜使い方についてコメントを入れるようにします。
オープンソースソフトウェアを使うことについて#
statsmodelsは修正 BSD License(3 条項 BSD ライセンス)に従うオープンソースソフトウェアです(statsmodelsのライセンス条項)。
オープンソースの利用は私的・商用問わずメリットだけでなくデメリットも理解したうえで利用することが必要でしょう。以下に参考としてstatsmodelsが従う修正 BSD Licenseの特徴と注意点を整理しておきます。
特徴:
-
再配布の自由: ソフトウェアを再配布する自由を保障する。
-
商用利用可: 商用利用は許可される。つまりこのライセンスの下で開発したソフトウェアを商業的なプロダクトに組み込むことができる。
-
修正可: ソフトウェアを修正し、派生作品を作成することが許可される。派生作品も同じライセンスの下で再配布できる。
-
著作権表示: ソフトウェアのコピーには、元の著作権表示とライセンス条件が含まれている必要がある。
-
無保証: ソフトウェアは無保証である。ソフトウェアの使用に関連するリスクは利用者が自己負担する必要がある。
注意点:
-
再配布に制約がないが故にソフトウェアが不正確であったり、他のソフトウェアと競合する可能性がある場合でも、再配布ができる。このため、派生作品がソフトウェアの品質を損なう可能性がある。
-
特許関連の制約なし: 特許関連の保護や制約が含まれていないため、特許侵害に対する保護が提供されない。これは特に特許関連の法的問題に対処する必要がある場合に問題となる可能性がある。
-
変更の追跡不要: 派生作品を元のプロジェクトに戻す必要がないため、変更の追跡が不要である。これにより、派生プロジェクトがソフトウェアを変更しても、元のプロジェクトに変更を報告する必要がない。
ソフトウェアのインストール#
サポート対象のPythonのバージョンはWebサイトを参照してください。
Anaconda環境でのインストール
conda install -c conda-forge statsmodels
pipでのインストール
python -m pip install statsmodels
次に本稿でしばしば使われる有用なデータについて説明します。
カリフォルニア住宅データ(California Housing Dataset)は、機械学習やデータ分析の教育や実践に広く使用されているデータセットです。これはカリフォルニア州の住宅価格に関連する様々な統計情報から構成されたデータであり、以下のような使い方に好適です。
-
回帰分析の実験: 住宅価格の予測に使用できる典型的な回帰分析のデータセットである。これを用いて、住宅価格を他の特徴(部屋数、人口、所得など)に基づいて予測するモデルを構築し、回帰分析の手法を試すことができる。
-
特徴量エンジニアリング: データセットには住宅価格以外にもさまざまな特徴が含まれている。これらの特徴を活用して特徴量エンジニアリングを試すことができる。例えば、新しい特徴を作成し、カテゴリカルデータをエンコードする方法をトライするなど。
-
データ可視化: データセットには地理情報が含まれており、地図上で住宅価格の分布を可視化することができる。データ可視化の手法を試すことができる。
-
機械学習アルゴリズムの比較: カリフォルニア住宅データを使用して、異なる機械学習アルゴリズム(線形回帰、決定木、ランダムフォレストなど)の性能を比較できる。ハイパーパラメータの調整やモデルの評価にも役立つ。
-
実世界データの扱い: 次世界のデータセットであるため、欠損値の処理、外れ値の検出、データクリーニングなど、実際のデータに対処する手法を試すことができる。
データの取得
StatLibのwebサイトにアクセスして「Houses.zip」ダウンロードします。
これを展開して出力されるcadata.txtをテキストエディタを使って開き、冒頭数行の説明書きをすべて削除し数値データのみとし保存します。
csvファイルの準備
以下のコードを実行するとヘッダ付きのcsv形式のファイルが作成されます。
# ref_housetocsv.py
# convert original text data to csv
# ダウンロードしたzipファイルを展開してできるcadata.txtで
# 数値データより上のコメントを全て削除した後で実行する
import pandas as pd
# テキストファイルを読み取り、データをDataFrameに変換
data = []
# delimiterがひとつ以上の空白のため正規表現('\s+')を使う
df = pd.read_csv('cadata.txt',delimiter=r'\s+',header=None,
names=['median_house_value', 'median_income', 'housing_median_age',
'total_rooms', 'total_bedrooms', 'population', 'households',
'latitude', 'longitude'])
# データ型を数値に変換
df = df.apply(pd.to_numeric, errors='coerce')
print(df)
# CSVファイルに保存
df.to_csv('cadata.csv', index=False)
回帰予測を実行する
入手したCalifornia Housingデータセットを用いて回帰予測によるパラメータ推定を行ってみましょう。なお回帰や帰無仮説など統計学の技法については別の章で扱うためここでは説明は省略します。
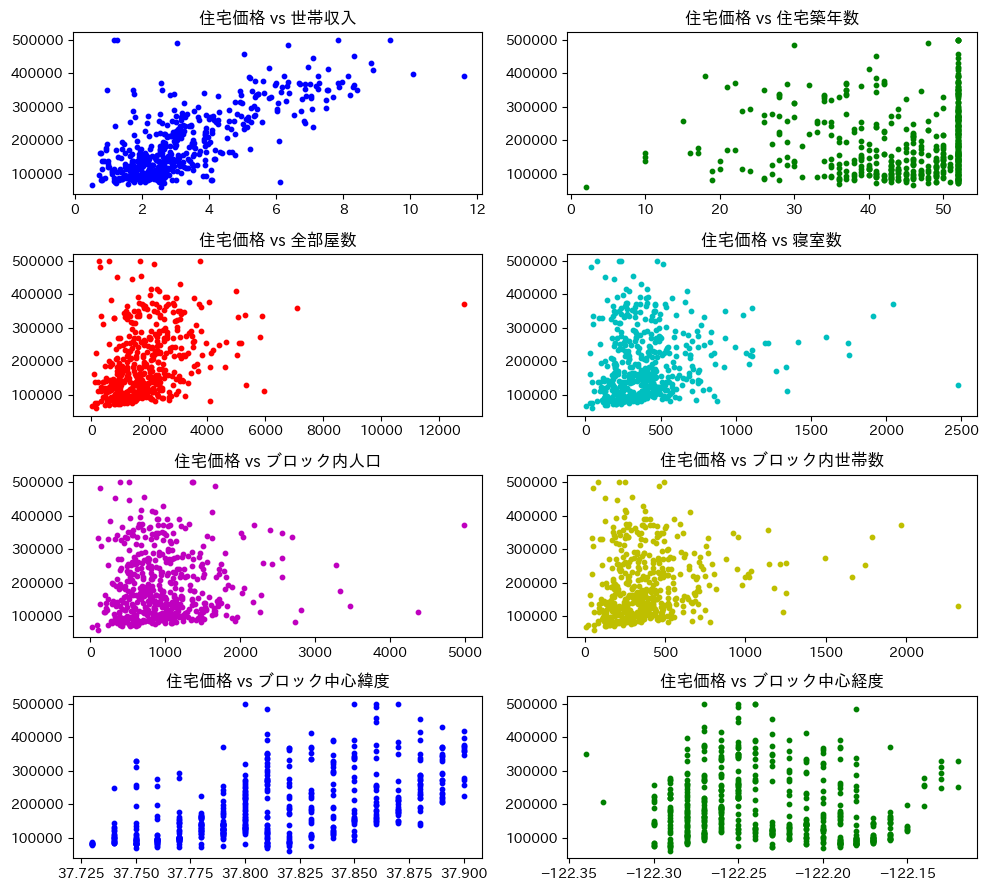
以下のコードではサンプルデータの「median_house_value」列を目的変数、そのほかの列を説明変数として重回帰予測を行いレポートを出力するとともにデータの散布図を表示します。
# resf_sm_ols.py
# 最小二乗法を用いた重回帰推定
#
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
import japanize_matplotlib
import pandas as pd
# サンプルデータ生成
df = pd.read_csv("cadata.csv")
df = df.dropna()
column_header = ["median_income", "housing_median_age", "total_rooms",
"total_bedrooms", "population", "households", "latitude",
"longitude"]
# データ数が大きいので最初の500件のみ使用する
df = df.iloc[0:500, ]
df_X = df.loc[:, column_header].astype(float)
X = df_X.values
df_y = df.loc[:, "median_house_value"].astype(float)
y = df_y.values
X = sm.add_constant(X) # 切片を含むために説明変数に定数項を追加
# 最小二乗法推定による線形回帰モデルを使い、住宅価格の予測式へのあてはめを行う
model = sm.OLS(y, X).fit()
# パラメータ推定結果の表示
print(model.summary())
print("Parameters: ", model.params)
# プロット
fig = plt.figure(figsize=(10, 9))
column_header_jp = ["世帯収入", "住宅築年数", "全部屋数",
"寝室数", "ブロック内人口", "ブロック内世帯数", "ブロック中心緯度",
"ブロック中心経度"]
title_jp = "住宅価格 vs "
clrs = ['b', 'g', 'r', 'c', 'm', 'y', 'b', 'g', 'r', 'c', 'm', 'y']
# 4行2列のサブプロットに散布図scatter()で描画
# marker: "o","+","x",etc
# s:マーカーのサイズ
for i in range(8):
pos = 421 + i
ax = fig.add_subplot(pos)
x = X[:, i + 1]
ax.scatter(x, y, color=clrs[i], marker='o', s=10)
ax.set_title(title_jp + column_header_jp[i])
plt.tight_layout()
plt.show()
実行すると以下のように各目的変数と各説明変数との相関を示す散布図が表示されます。
処理結果レポートの見方#
上記のサンプルコードを実行したときの処理結果レポート
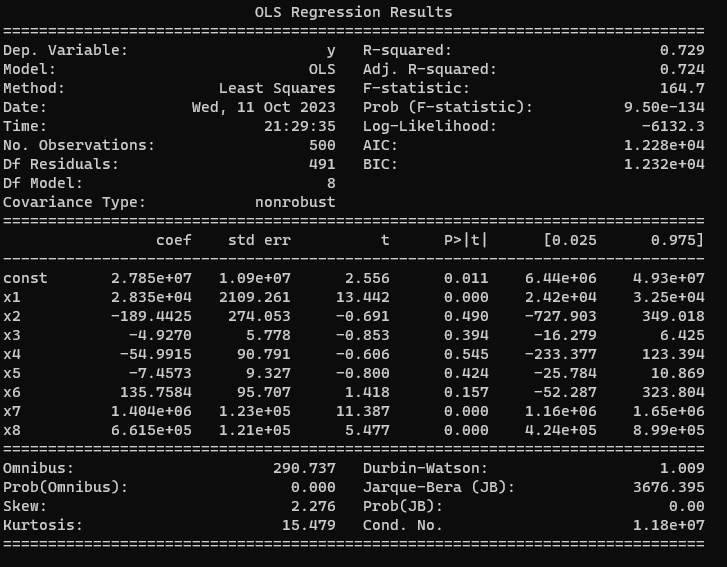
レポートの各項目の説明 results.summary()で出力される情報は、statsmodelsを使用して推定した統計モデルの詳細な統計情報を提供しています。この情報には、回帰モデルの適合度、係数の推定値、仮説検定の結果、モデルの性能評価などが含まれます。以下に、表示される結果の各セクションを説明します。
-
Dep. Variable(従属変数):
モデルで設定した従属変数(目的変数)の名前。 -
Model(モデル):
使用された統計モデルの名前や仕様。 -
Method(方法):
使用された推定方法(最尤法、最小二乗法など)。 -
Date(日付):
モデルを実行した日付。 -
Time(時間):
モデルの実行にかかった時間。 -
No. Observations(観測数):
モデルに使用された観測データの総数。 -
Df Residuals(残差の自由度):
残差の自由度(残差の数から推定されるパラメータの数を差し引いたもの)。 -
Df Model(モデルの自由度):
モデルの自由度(推定されたパラメータの数)。 -
Covariance Type(共分散の種類):
共分散行列のタイプ(Homoscedastic(等分散)、Heteroscedastic(非等分散)。 -
R-squared(決定係数):
決定係数(R-squared)は、モデルがデータをどれだけよく説明しているかを示す指標で、0から1の値を取る。1に近いほどモデルの適合度が高いことを示しています。 -
Adj. R-squared(調整決定係数):
調整決定係数(Adj. R-squared)は、説明変数の数を考慮した決定係数で、過剰適合(オーバーフィッティング)を考慮した指標。 -
F-statistic(F統計量):
F統計量(F-statistic)は、回帰分析において、回帰モデル全体の統計的有意性を評価するための統計量です。統計的有意性は帰無仮説の検証によって判定されます。 帰無仮説 H0(null hypothesis) : 全ての説明変数(独立変数)を含まない、つまり単純な平均値モデルであり、帰無仮説モデルの下では、説明変数が目的変数に対して影響を持たないと仮定します。 対立仮説 H1(Alternative hypothesis): 対立仮説モデルの下では、少なくとも一つ以上の説明変数が目的変数に対して影響を持つと仮定します。 F統計量が大きい場合、帰無仮説モデルと対立仮説モデルとの間に統計的に有意な違いがあることを示し、説明変数が目的変数に対して有意な影響を持っている可能性が高いことを示唆します。一般的に、F統計量の値が一定の有意水準を超える場合、帰無仮説を棄却し、回帰モデル全体が有意であると結論できます。 -
Prob (F-statistic)(F統計量の確率値):
F統計量の確率値は、F分布の下でのモデルの有意性を示します。小さい値ほどモデルが有用であることを示しています。 -
AIC(赤池情報量基準)および BIC(ベイズ情報量基準):
AICとBICは、モデルの適合度とモデルの複雑さをトレードオフで考慮する情報量基準。モデルの選択に役立ちます。 -
coef(係数):
各説明変数の係数(回帰係数)の推定値。
以下15.から19.までの予測式のパラメータ推定値と評価値が1行ごとに表示されます。 -
std err(標準誤差):
係数の推定値の標準誤差。 -
t(t値):
各係数のt値が表示される。通常、t値が絶対値が2以上で、p値(t分布の下での帰無仮説を棄却する確率)が0.05より小さい場合、係数は統計的に有意であるとみなされます。この数値の絶対値が大きいほど目的変数の予測への貢献が大きいと考えられます。 -
P>|t|(p値):
この値が有意水準以下であれば検定で設定された帰無仮説は棄却されます。 -
[0.025 0.975](信頼区間):
各係数の95%信頼区間が表示されます。信頼区間は、推定値の信頼性を示します。 -
Omnibus(オムニバス検定)および Prob(Omnibus)(オムニバス検定のp値):
オムニバス検定は、モデル全体の適合度を評価する統計検定です。 -
Durbin-Watson(ダービン・ワトソン統計量):
ダービン・ワトソン統計量は、残差の自己相関を評価する指標で、時系列データの場合に特に重要 -
Jarque-Bera (JB):
ジャーク・ベラ統計量(正規性の検定)。 -
Prob(JB):
JB統計量のp値。データが正規分布に従うかどうかを評価します。 -
Skew:
歪度(スキュー)はデータの分布が左右対称からどれだけずれているかを示しています。 -
Kurtosis:
尖度(カートーシス)はデータの尖度を評価し、正規分布と比較します。
下部には残差の統計情報や回帰診断統計量が表示されることがあります。これらの情報は、モデルの適合度や残差の性質を評価するために役立ちます。