第6章 非効率だから機会もある#
数理的手法の大きな目標は、現実の事象を再現できる数学的モデルを作成することです。金融領域でいえば、株価を数学的モデルとして表現することの妥当性や有用性は、研究者や実務専門家の間で昔から議論されているところです。例えば、「株価はランダムウォークの性質を有するのか?」よく話題になるテーマです。
本章のテーマである「ペアトレーディング」は、株価がランダムウォークの性質を有することをベースとして構築される株取引手法です。以下では、ペアトレーディングの基礎となる理論面の説明を 第 1 節と 第 2 節で行います。そして第 3 節ではペアトレーディングのための重要機能の実装例を紹介します。
1. 株価をシミュレートする#
数理的手法の大きな目標は、現実の事象を再現できる数学的モデルを作成することです。株価を数学的モデルとして表現することの妥当性や有用性は、研究者や実務専門家の間で昔から議論されているところです。ここで株価の動きをシミュレートするコードを紹介しておきます。
1.1. 株価定義の考え方#
株価の動きを近似する時系列を以下二種類の考え方で定義します。
考え方1. 値動きを加法的に累積した量を株価とする
次の時点の株価 は、現時点株価とは独立したランダムな値動き(=収益) と長期トレンドを発生させるドリフト項 を現時点株価 に加算することで決まる、とする考え方です。言い換えると、ある時点の株価は起点となる時点の株価に対して毎時点の値動きを累積加算することで与えられます。これは確率過程の用語で単純ランダムウォークと呼ばれています。また、これは第 4 章で解説しました自己回帰型モデル AR(1) 自己回帰係数が 1 の場合として扱うこともできます。
この考え方では株価を AR(1) として扱うので、時系列分析の適用が容易になるメリットがあります。しかし平均が時間 t に比例し発散していくことと、変動にマイナスを許しているためそれが累積した場合、株価がいつかマイナスになる可能性があります。このためある時間範囲のなかで実際の株価の動きをうまく模擬できたとしても大域的な適用には注意が必要です。
考え方2. 値動きを連続複利計算に基づき乗法的に累積した量を株価とする
年 n 回利払いが行われる複利計算では、元本 と年利率 に対して、時点 の資産の価値 は以下のように計算されます。
株式のように保有しているだけで、時々刻々資産価格が変動する資産は、上記の複利計算の回数 n が無限回行われる金融資産と考えるモデル化ができます。そして実際にそのようにモデル化することで現実の金融資産の価値推移を再現できることが知られています。
nを無限大にした極限の複利計算を連続複利計算とよび、以下の式で資産価格を表すことができます。指数関数の展開式 から、
この定義は考え方1とは違い株価がマイナスになる問題はありません。
1.2. 連続時間でのモデル化#
本稿ではこれまで離散時間の時系列を対象に解説を進めてきました。現実には、日足の株価や月次の金融・経済指標等を分析する応用では、離散時間モデルが適しているという意見がある一方で、分足の株価や為替、先物などほぼ連続的に変動するデータに対しては連続時間モデルが広く活用されています。
連続時間のモデルは数理的に興味深く自然科学の世界では一般的です。そこでこの項では、株価を近似する手段として連続時間のモデルを紹介しようと思います。
株価を算術的ブラウン運動によるモデル化する
前項の考え方1では株価を離散時間の AR(1) モデルの特殊なケース(自己回帰係数 )として定義しました。AR(1) モデルは一般論として、時間ステップを微小化した極限の連続時間では オルンシュタイン-ウーレンベック(Ornstein-Uhlenbeck)過程 と呼ばれる確率過程に収束することが知られています。オルンシュタイン-ウーレンベック過程(以下簡単にOU過程と略すことがあります)は確率微分という概念を使い、以下のように表現されます。数学的な定義は専門的であるため確率過程論の教科書を参照ください。ここでは通常の微積分の記号を使って直観的に記述することにします。
ここで、
: 時刻 における株価
: 平均値
: 平均回帰速度
: 分散
: 標準ブラウン運動(Wiener過程ともいう)
標準ブラウン運動にドリフト項を加えて構成した オルンシュタイン-ウーレンベック過程のことを算術的ブラウン運動と呼びます。
と置くと、方程式は次のように簡略化されます。
積分因子 を掛けると、
左辺は時間微分の形で書くことができます。
これを積分すると、
元の変数に戻すこと解を積分形式で表現することができます。
以下に、OU 過程の定義式 (1.2.1) に基づいて、解をプロットするコードを紹介します。コードは株価をシミュレートするために、OU 過程としてはトリビアルな例になっていて、theta ゼロとしています(シンプルランダムウォークそのもの)。ゼロ以外の数値、例えば 0.2 などを設定すると時間とともに平均 mu 周辺を振動する定常性がみられるようになります。テストデータをチェックするために、ランダム項の正規性を検定するコードを入れています。
# math_abm.py
# 株価時系列をOrnstein-Uhlenbeck過程により株価をシミュレートする:
#
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import shapiro
import japanize_matplotlib
import matplotlib as mpl
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
def generate_abm(s0,mu, sigma,T=252,dt=1):
# Ornstein-Uhlenbeck過程のパラメータ
theta = 0 # 平均回帰速度。 0 はシンプルランダムウォークに相当するので非定常
N = int(T / dt) # 時間ステップ数
# 初期値
X_0 = s0
# ノイズ(ホワイトノイズを時間ステップにスケール)
rng = np.random.default_rng(1234)
dW = np.sqrt(dt) * rng.standard_normal(size=N) # ブラウン運動の増分
# Ornstein-Uhlenbeck過程のシミュレーション
X = np.zeros(N)
X[0] = X_0
for i in range(1, N):
X[i] = X[i - 1] + theta * (mu - X[i - 1]) * dt + sigma * dW[i - 1]
return X
# 算術的ブラウン運動のパラメータ
mu = 50 # 平均値
sigma = 1.0 # 標準偏差
T = 252 # 日数
dt = 0.1 # 時間方向のメッシュ間隔
N = int(T / dt) # シミュレーションのステップ数
S0 = 100 # 初期株価
abm = generate_abm(S0,mu,sigma,T=T,dt=dt)
stock_prices = abm
# 株価差分の計算
diff_price = np.diff(stock_prices)
# 二つのaxesを作成
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 7), gridspec_kw={'height_ratios': [3, 1]})
# 株価時系列のプロット
t = np.linspace(0, T, N)
ax1.plot(t, stock_prices, color='b')
ax1.set_xlabel('日数')
ax1.set_ylabel('株価')
ax1.set_title('算術的ブラウン運動による株価のシミュレーション')
# 株価差分のプロット
ax2.plot(t[1:], diff_price, color='r')
ax2.set_xlabel('日数')
ax2.set_ylabel('株価差分')
ax2.set_title('株価差分時系列')
# 生成した株価データに対して Shapiro-Wilkテストを使用して株価差分の正規性を検定する
stat, p_value = shapiro(diff_price)
print(f'Shapiro-Wilk 検定: 検定統計量= {stat}, p-値= {p_value}')
if p_value > 0.05:
print("株価差分は正規分布に従います")
else:
print("株価差分は正規分布に従いません")
# レイアウトの調整
plt.tight_layout()
plt.show()
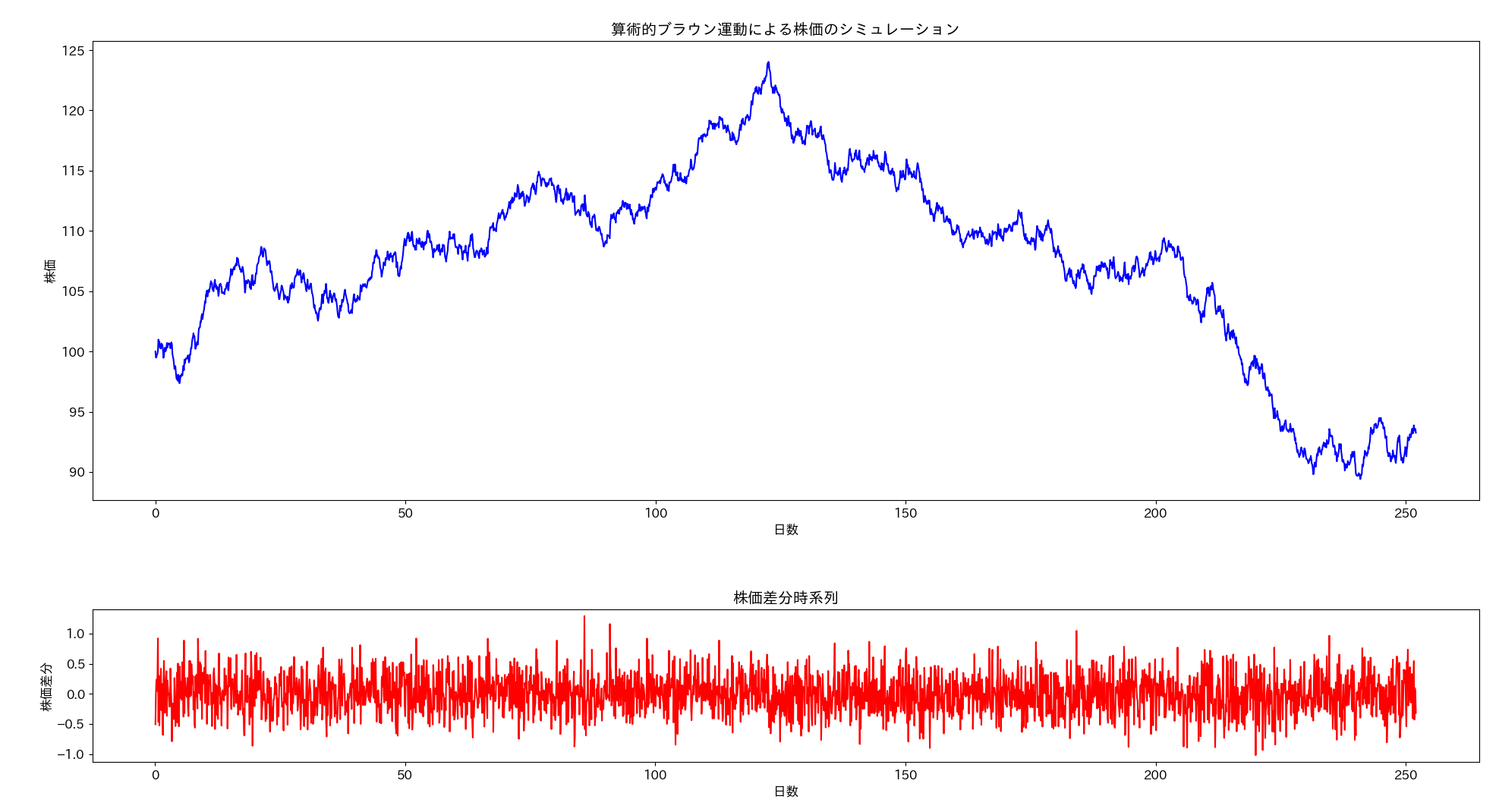
算術的ブラウン運動を用いたモデル化では、株価の変動量は のみに依存するため、価格の変化率が高価格株と比較して低価格株の方が大きくなります。このため低価格株の方が株価のボラタリティの影響が顕著になる特徴があります。
株価を幾何ブラウン運動によりモデル化する
次に前項の考え方2に基づく数学的なモデル化は、連続複利計算における利率 r を長期的な傾向を表す項と正規分布に従うランダムな微小変動の和として表します。

ここで、
は ドリフト(または平均収益率)。 価格の長期的な傾向を表す
は株価のボラティリティ。価格変動のばらつきの大きさを表す
は時間の変化(通常、1日あたりの時間)
は独立同分布で標準正規分布に従う乱数
この定義式から、 は次のように表現されます。
( が小さい場合)の近似を適用すると、
差分形式で書けば、
連続時間の極限()では以下の確率微分方程式に収束します。
ここで、(ブラウン運動の性質)を利用しています。
の変化を元のスケール に戻すために、指数関数をとると、
この式は幾何ブラウン運動としてよく知られています。以下のコードは幾何ブラウン運動により株価をシミュレートしプロットします。
# predi_gbm.py
# 株価時系列を幾何ブラウン運動でシミュレートする:
#
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import shapiro
import japanize_matplotlib
import matplotlib as mpl
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
def generate_gbm(mu, sigma,T=252,dt=1):
rng = np.random.default_rng(1234)
N = int(T / dt)
t = np.linspace(0, T, N+1)
W = rng.standard_normal(size=N+1)
B = np.cumsum(W) * np.sqrt(dt / T)
X = (mu - (1/2) * sigma**2) * t / T + sigma * B
return np.exp(X)
# 幾何ブラウン運動のパラメータ
mu = 1.0 # 平均収益率
sigma = 1.0 # 標準偏差
T = 252 # 日数
dt = 0.1 # Tのメッシュ間隔
N = int(T / dt) # シミュレーションのステップ数
S0 = 100 # 初期株価
gbm = generate_gbm(mu,sigma,T=T,dt=dt)
stock_prices = S0 * gbm
# 対数収益率の計算
log_returns = np.diff(np.log(stock_prices))
# 二つのaxesを作成
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 7), gridspec_kw={'height_ratios': [3, 1]})
# 株価時系列のプロット
t = np.linspace(0, T, N+1)
ax1.plot(t, stock_prices, color='b')
ax1.set_xlabel('日数')
ax1.set_ylabel('株価')
ax1.set_title('幾何ブラウン運動による株価のシミュレーション')
# 対数収益率のプロット
ax2.plot(t[1:], log_returns, color='r')
ax2.set_xlabel('日数')
ax2.set_ylabel('対数収益率')
ax2.set_title('対数収益率時系列')
# 生成した株価データに対して Shapiro-Wilkテストを使用して対数収益率の正規性を検定する
stat, p_value = shapiro(log_returns)
print(f'Shapiro-Wilk 検定: 検定統計量= {stat}, p-値= {p_value}')
if p_value > 0.05:
print("対数収益率は正規分布に従います")
else:
print("対数収益率は正規分布に従いません")
# レイアウトの調整
plt.tight_layout()
plt.show()
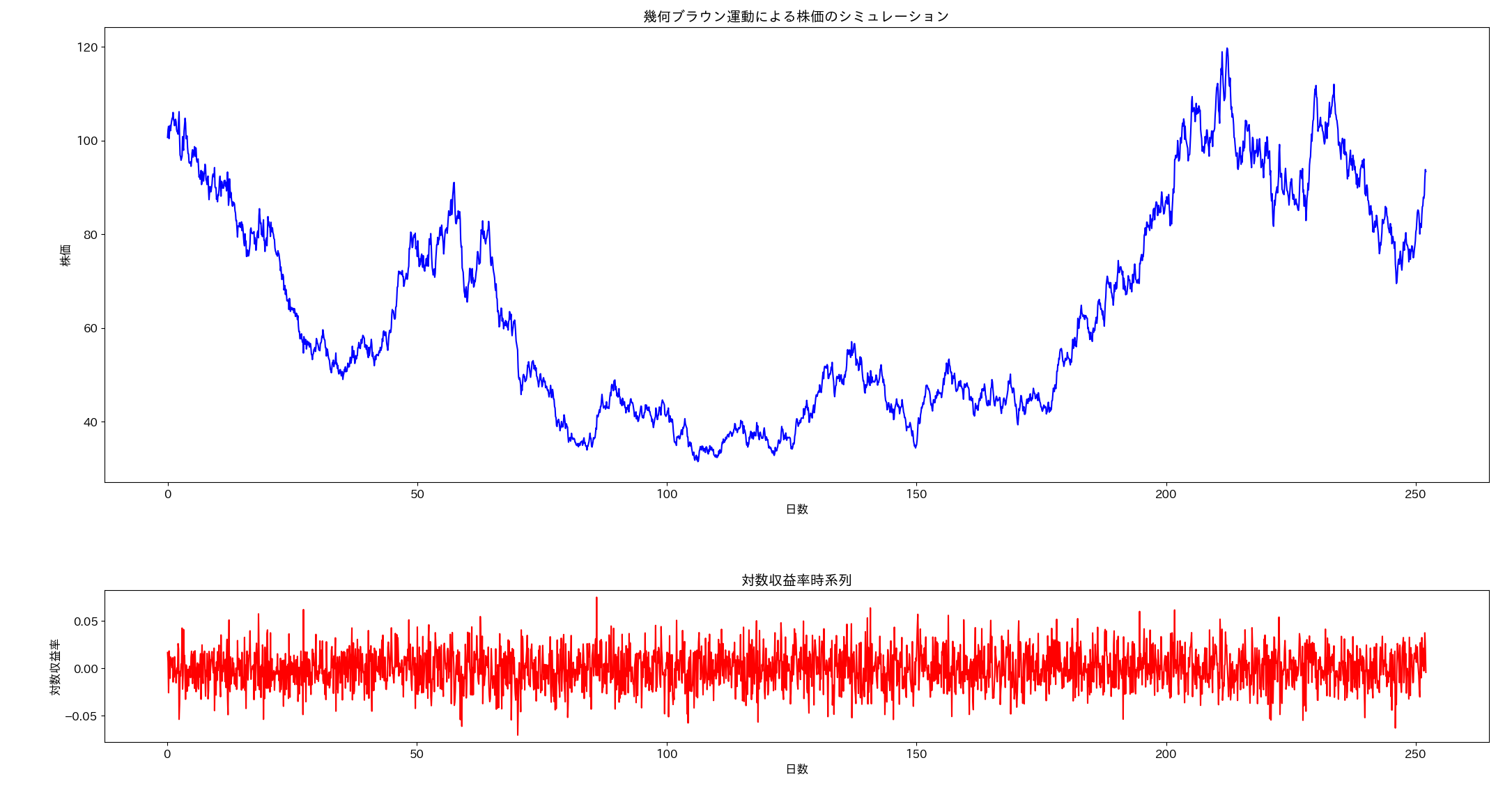
算術ブラウン運動による株価と対比するために乱数シードを共通化しています。乱数シードやパラメータをいろいろ変えてみると、算術ブラウン運動では株価がマイナスになることがありますが、幾何ブラウン運動では常に正値になっています。
幾何ブラウン運動を用いたモデル化では、価格の変化率を考えることで銘柄の成長率やリスクの計算がしやすい特徴があります。そのため金融系の実務において、資産価格をモデル化するためによく利用されます。
1.3. AR(1)を取り出す#
前項では特段の説明無しに、「AR(1) モデルは時間ステップを微小化した極限で OU 過程に収束する」、を前提に話を進めました。すると、株価データを連続時間の確率過程で取り扱うためには、何か小さな時間ステップを定義して株価を近似する必要がありそうで気になります。実際にはうまい具合になっていて、OU過程から一定間隔でサンプリングした時系列はAR(1)モデルになっていることがわかります。そのため本稿では実際の株価データをAR(1)モデルによって推定した得たパラメータをOU過程のパラメータに変換することで、OU過程の解析のステップに進むようにしています。
次のコードは、テスト的に生成したOU過程から一定間隔でサンプリングした時系列がAR(1)モデルに適合していることを検定しています。
# math_ou_sampling.py
# OU過程からサンプリングした時系列がAR(1)であることを確認する
import japanize_matplotlib
import matplotlib as mpl
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.stats.diagnostic import acorr_ljungbox
import matplotlib.pyplot as plt
# 1. OU過程のシミュレーション
def simulate_ou_process(theta, mu, sigma, T, dt):
np.random.seed(42)
N = int(T / dt)
X = np.zeros(N)
W = np.random.normal(0, np.sqrt(dt), N) # ブラウン運動の増分
for t in range(1, N):
X[t] = X[t-1] + theta * (mu - X[t-1]) * dt + sigma * W[t]
return X, np.arange(0, T, dt)
# パラメータ
theta = 0.5
mu = 0.0
sigma = 1.0
T = 100
dt = 0.01
# シミュレーション
ou_process, time = simulate_ou_process(theta, mu, sigma, T, dt)
# 2. 一定間隔でサンプリング
sampling_interval = 10 # 10ステップごとにサンプリング
sampled_indices = np.arange(0, len(ou_process), sampling_interval)
sampled_series = ou_process[sampled_indices]
sampled_time = time[sampled_indices]
# 3. AR(1)モデルの適合
model = ARIMA(sampled_series, order=(1, 0, 0))
fit = model.fit()
# 結果を表示
print(fit.summary())
# ARIMAモデルの推定結果解釈
print("AR(1)モデルの推定結果:\n")
print(fit.summary())
phi = fit.params[1] # AR(1)係数
intercept = fit.params[0] # 定数項
print(f"\n推定パラメータ:\n"
f" AR(1)係数 (phi): {phi:.4f}\n"
f" 定数項: {intercept:.4f}\n")
# 4. Ljung-Box検定
ljung_box_test = acorr_ljungbox(fit.resid, lags=[10], return_df=True)
p_value = ljung_box_test.iloc[0]['lb_pvalue']
print("\nLjung-Box検定結果:\n")
print(ljung_box_test)
# 帰無仮説の説明と結果判定
null_hypothesis = "残差は独立に分布している(有意な自己相関は存在しない)。"
if p_value > 0.05:
conclusion = "帰無仮説を棄却できません: AR(1)モデルは適切と考えられます。"
else:
conclusion = "帰無仮説を棄却します: 残差に有意な自己相関が存在します。"
print(f"\n帰無仮説: {null_hypothesis}\n結果: {conclusion}\n")
# 4. サブプロットの作成
fig, axs = plt.subplots(2, 1, figsize=(12, 8), sharex=True)
# 上側プロット:元のOU過程とサンプリングされた時系列
axs[0].plot(time, ou_process, label="OU 過程", color='blue', alpha=0.6)
axs[0].scatter(sampled_time, sampled_series, color='red', label="サンプリング時系列")
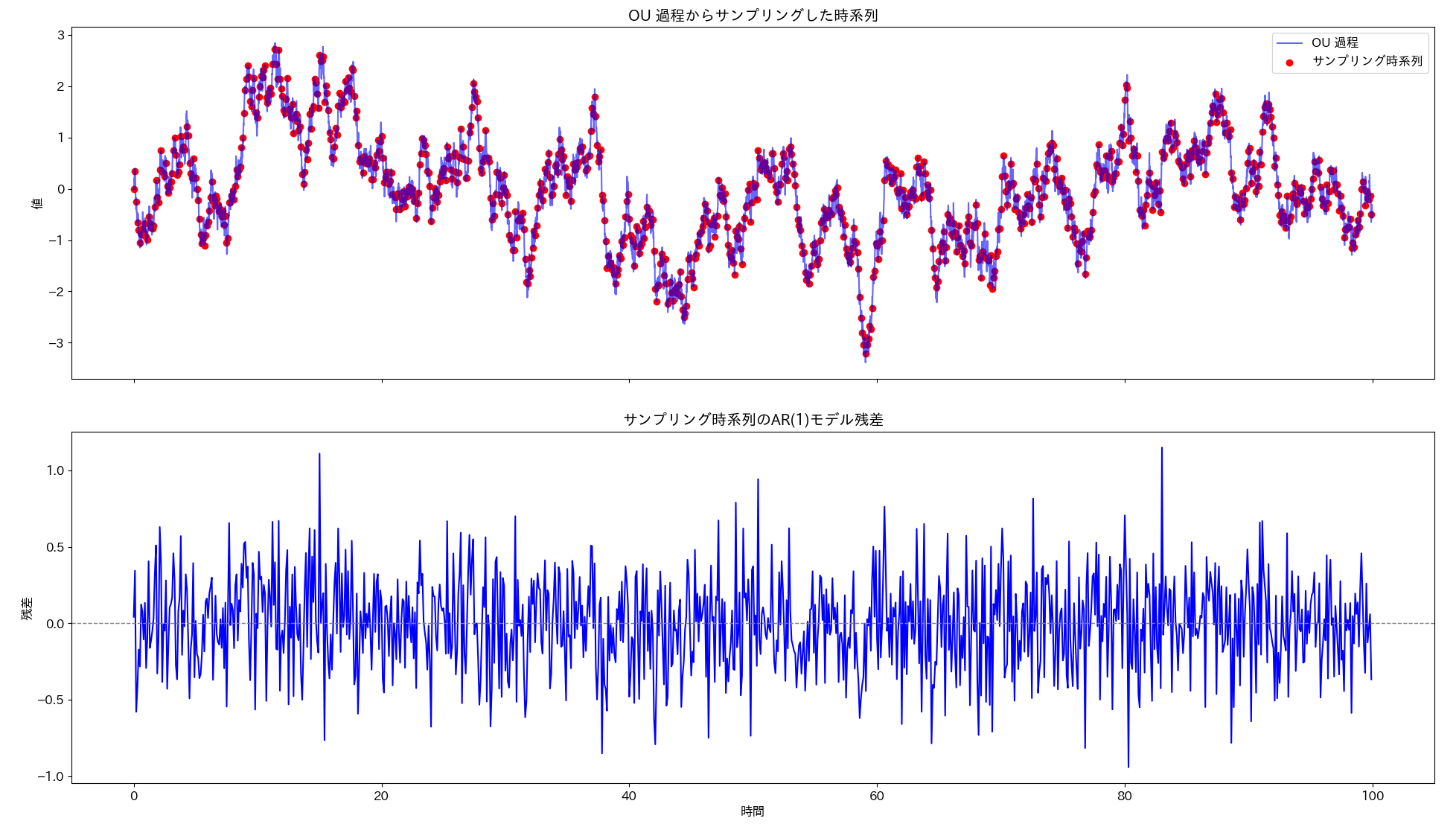
axs[0].set_title("OU 過程からサンプリングした時系列")
axs[0].legend()
axs[0].set_ylabel("値")
# 下側プロット:残差プロット
axs[1].plot(sampled_time, fit.resid, color='blue')
axs[1].axhline(0, linestyle='--', color='gray', linewidth=1)
axs[1].set_title("サンプリング時系列のAR(1)モデル残差")
axs[1].set_xlabel("時間")
axs[1].set_ylabel("残差")
# グラフの調整
plt.tight_layout()
plt.show()
以下は生成したOU過程とサンプリングした時系列をプロットした図です。下方のサブプロットはAR(1)モデルによる推定値とサンプリングした時系列の残差をプロットしています。
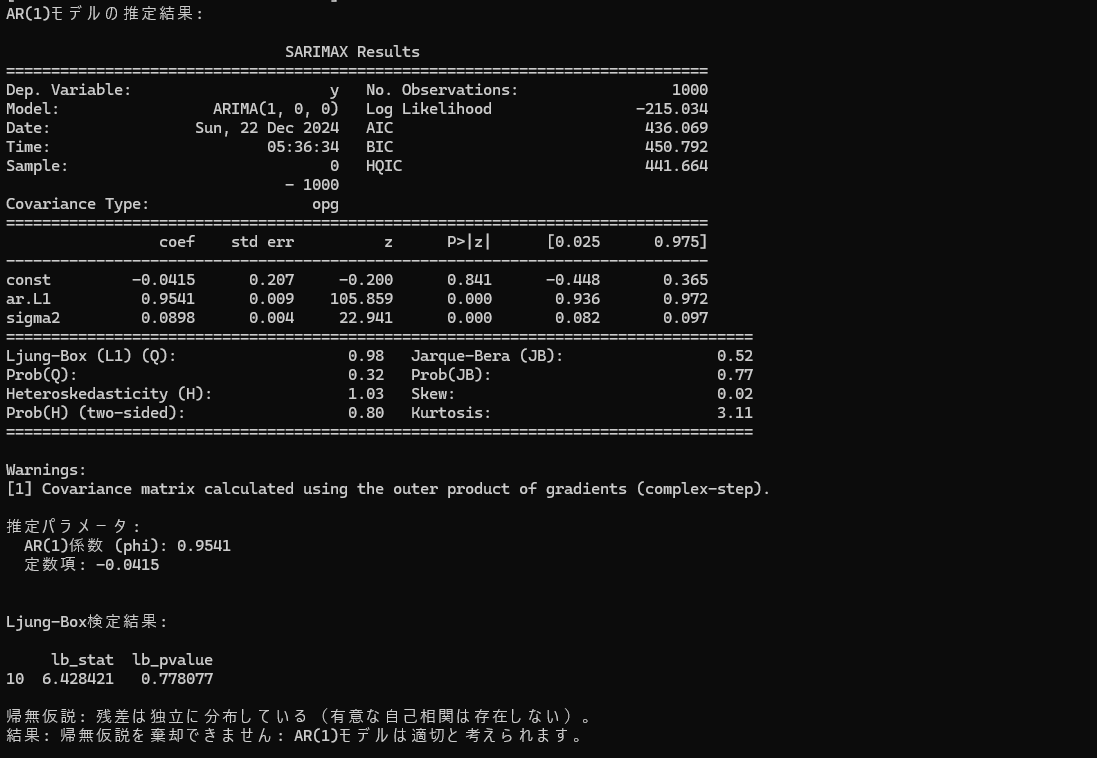
以下は推定結果のレポートです。サンプリングした時系列は検定した結果AR(1)モデルに適合していることを判定できました。
2. 平均回帰時間を見積もる#
2.1. AR(1)で実験してみる#
AR(1) における自己回帰係数が の場合の非常に重要な性質は、平均回帰性を有することです。どこかの時点で時系列の値が平均値より大きく乖離したとしても、時間が経過すると必ず、平均値へと値が戻るタイミングが訪れる場合、その時系列は平均回帰性を有するといいます。必ず平均に戻るとして、いつ頃に戻ってくるのかが非常に気になりますね。100年まってようやく戻るような性質であればあまり役に立ちそうもありません。平均への回帰に要する時間がどの程度であるのかがわかることは非常に重要です。
AR(1)過程を以下のように定義しましょう。
平均回帰時間とは、時系列が を出発し平均値を通過する最初の時刻を意味します。これは数学や物理の教科書でよく使われる第一通過時間(First Passaage Time,FPTあるいは、First Hitting Time,FHT)において、経路の通過点を平均値に設定したときの言い方です。次のように定義します。以下では、話を簡単にするために とします。
AR(1)モデルから回帰時間を計算する試行を多数回実施し、平均値を算出するコードを以下に示します。経路をプロットすることで、 回帰時間の意味合いがイメージしやすくなります。
# math_ar1_mfpt.py
# AR(1)の第一通過時間を計算する試行を繰り返し、頻度をプロットする
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示対応
from statsmodels.tsa.stattools import adfuller
import matplotlib as mpl
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
# ランダムネスのシードを固定
np.random.seed(1)
# パラメータ設定
Phi = 0.5 # AR(1)の係数。1に近づくほど非定常性が現れてくる
Mu = 10.0 # 平均値
Sigma = 0.5 # ノイズの標準偏差
X0 = 0.0 # 初期値
Delta = Sigma # 到達許容範囲は Sigma と同程度に設定
num_trials = 1000 # シミュレーション回数
T_max = 50 # 打ち切り時間
# シミュレーションで第一通過時間を計算
def first_passage_time(phi, mu, sigma, x0, delta, max_time):
t = 0
X = np.zeros(max_time)
X[0] = x0
i = 1
not_passed = True
while i < max_time:
X[i] = mu + phi * (X[i-1] -mu)+ np.random.normal(0, sigma * np.sqrt(1))
if X[i] >= mu and not_passed:
T = i
not_passed = False
i+=1
return T, X
# 各試行の第一通過時間と時系列データを取得
first_passage_times = []
paths = []
for _ in range(num_trials):
t, path = first_passage_time(Phi, Mu, Sigma, X0, Delta, T_max)
first_passage_times.append(t)
paths.append(np.array(path)) # NumPy配列に変換
# 第一通過時間の平均値(シミュレーション結果)
simulated_mean_time = np.mean(first_passage_times)
# ADF検定を試行ごとに適用
print("\nADF検定結果:")
for i in range(min(10, num_trials)): # 最初の10試行
adf_test = adfuller(paths[i]) # NumPy配列を直接渡す
p_value = adf_test[1]
stationary = "定常性がある" if p_value < 0.05 else "定常性がない"
print(f"試行 {i+1}: p値 = {p_value:.4f} ({stationary})")
# 時系列プロット
plt.figure(figsize=(12, 6))
for i, path in enumerate(paths[:10]): # 最初の10試行
plt.plot(path, label=f'試行 {i+1}')
plt.xlim(0,20)
plt.axhline(Mu, color='red', linestyle='--', label='平均値 μ')
plt.title("AR(1) 過程の第一通過時間のシミュレーション")
plt.xlabel("時刻")
plt.ylabel("X_t")
plt.legend()
# 第一通過時間のヒストグラム
plt.figure(figsize=(12, 6))
plt.hist(first_passage_times, bins=10, color='skyblue', edgecolor='black', alpha=0.7)
plt.title("第一通過時間の分布")
plt.xlabel("第一通過時間")
plt.ylabel("頻度")
plt.grid(True)
# 結果を表示
print(f"AR(1)過程による平均第一通過時間: {simulated_mean_time:.4f}")
plt.show()
以下は、実行結果の、構成された時系列の最初の10個を表示した図です。開始点から出発した経路が急速に平均値へ接近した後、振動している様子がわかります。
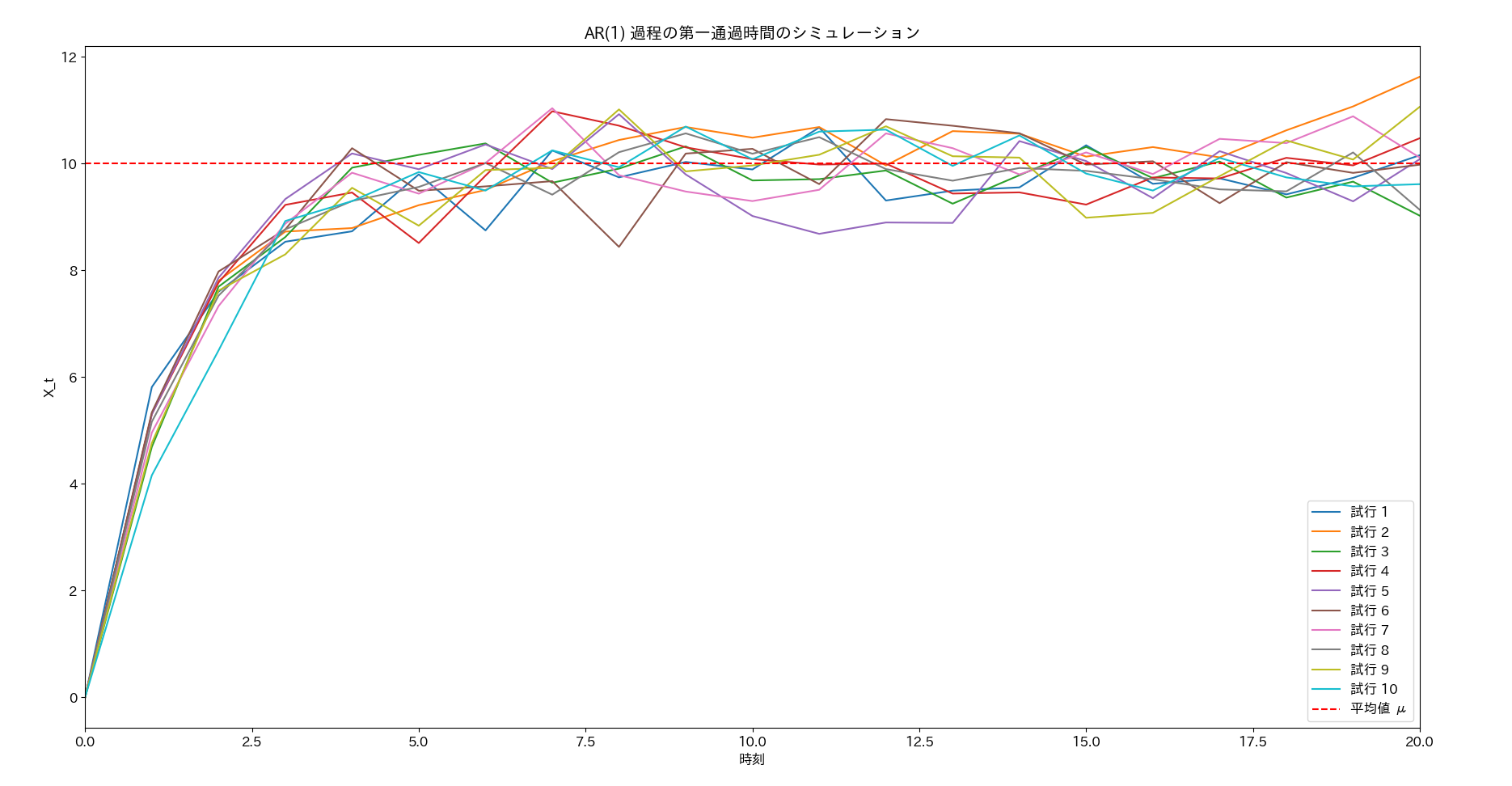
以下は、実行結果の、第一通過時間の分布を表すヒストグラムです。粗いプロットなのでややわかりづらいですが、ピークを挟んで右側へなだらかに下がっていく様子がわかります。
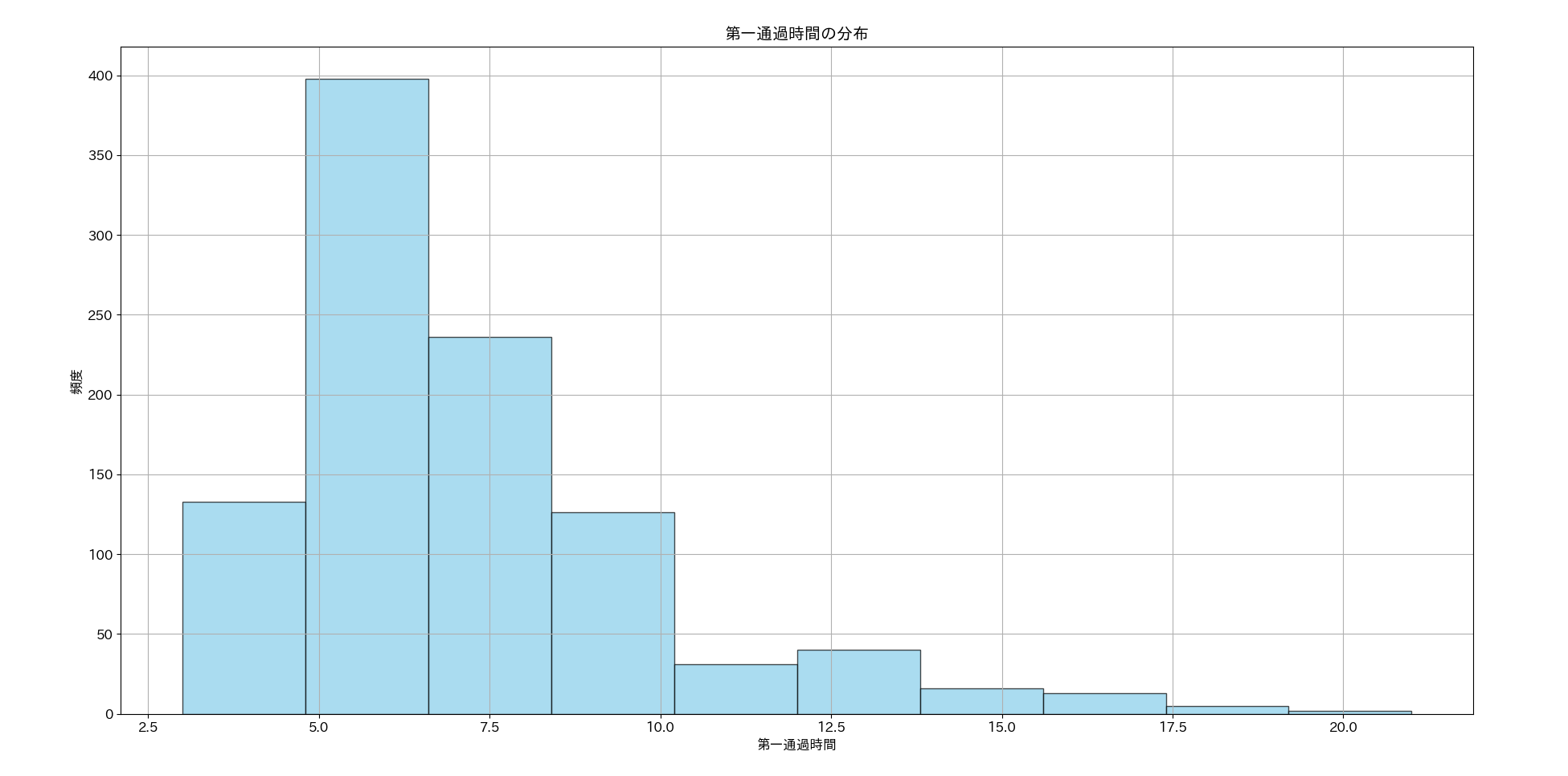
以下は、実行結果の、第一通過時間の分布の平均値です。

サンプルプログラムでは試行を何回も繰り返すことで、第一通過時間の平均値を算出することができました。しかし実際の株価の場合は、繰り返し試行はできませんので何らかの考え方に基づいて平均回帰時間を見積もる必要があります。
この見積りのために役に立つのが第 1 節で紹介しましたオルンシュタイン・ウーレンベック過程です。
2.2. オルンシュタイン・ウーレンベック過程で実験してみる#
オルンシュタイン・ウーレンベック過程を考えます。
ここで、 は平均回帰速度、 は定常平均値 、 はノイズ強度、 は標準ブラウン運動です。
左右の項を移動させます。
積分因子 を掛けます。
左辺は積分の形になるので、次のように変形できます。
これを積分すると、
両辺に を掛けて を得ます。
次に、ブラウン運動の増分については、 であること、そして確率微分に関して良く知られた伊東積分の算法を利用します。伊東積分については残念ながらここで説明する余地がないため、例えば「入門確率過程」 松原望 著 東京図書 等、確率過程の教科書を参照ください。
上記から、期待値については
分散については、ノイズ項 の寄与のみが残ります。
したがって、分散は、
特に のとき、過程は定常状態となります。
- 期待値: ,
- 分散: 。
これにより、OU 過程は時間が経つにつれて、長期的な平衡点 を中心に振動しながら、分散は急速に縮小し一定値 に収束する、という定常的な挙動を示していくことがわかります。
OU 過程の第一通過時間を、AR(1)のケースと同じように、回帰時間を計算する試行を多数回実施し、平均値を算出するコードを以下に示します。
# math_ou_mfpt.py
# Ornstein-Uhlenbeck過程の第一通過時間を計算する試行を繰り返し、頻度をプロットする
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from statsmodels.tsa.stattools import adfuller
import random
from scipy.special import erf
import matplotlib as mpl
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
# ランダムネスのシードを固定
np.random.seed(1)
# パラメータ設定
Theta = 0.5 # 平均回帰率
Mu = 10.0 # 平均値
Sigma = 0.5 # ノイズ強度
X0 = 0.0 # 初期値
T_max = 50 # 最大シミュレーション時間
Dt = 0.1 # 時間ステップ
num_trials = 1000 # 試行回数
Delta = Sigma # 到達許容範囲
# シミュレーション結果を格納
first_passage_times = []
paths = []
# シミュレーション
def first_passage_time(theta, mu, sigma, x0, delta, dt, max_time):
num_steps = int(max_time / dt)
t = np.linspace(0, max_time, num_steps)
X = np.zeros(num_steps)
X[0] = x0
i = 1
not_passed = True
W = np.random.normal(scale=np.sqrt(dt), size=1)
while i < num_steps:
X[i] = X[i-1] + theta * (mu - X[i-1]) * dt + sigma * W[0]
W = np.random.normal(scale=np.sqrt(dt), size=1) # 1ステップごとに生成
if X[i] >= mu and not_passed:
T = i * dt
not_passed = False
i+=1
return T,X
for _ in range(num_trials):
fpt, path = first_passage_time(Theta, Mu, Sigma, X0, Delta, Dt,T_max)
first_passage_times.append(fpt)
#paths.append(np.array(path)) # NumPy配列に変換
paths.append(path) # 初到達までのデータを保存
# 第一通過時間のヒストグラム
plt.figure(figsize=(10, 6))
plt.hist(first_passage_times, bins=30, color="skyblue", edgecolor="black")
plt.title("Ornstein-Uhlenbeck過程の第一通過時間の分布")
plt.xlabel("第一通過時間")
plt.ylabel("頻度")
#plt.show()
# 各試行の時系列プロット
plt.figure(figsize=(12, 6))
for i in range(10): # 最初の10試行をプロット
t = np.arange(len(paths[i])) * Dt
plt.plot(t, paths[i], label=f"試行 {i+1}")
plt.xlim(0,20)
plt.axhline(Mu, color="red", linestyle="--", label="平均値 μ")
plt.title("Ornstein-Uhlenbeck過程の時系列 (時間ステップ dt=0.1) ")
plt.xlabel("時間")
plt.ylabel("X(t)")
plt.legend()
print("\nADF検定結果:")
for i in range(min(10, len(paths))): # 最初の10試行
adf_test = adfuller(paths[i]) # NumPy配列を直接渡す
p_value = adf_test[1]
stationary = "定常性がある" if p_value < 0.05 else "定常性がない"
print(f"試行 {i+1}: p値 = {p_value:.4f} ({stationary})")
# 平均回帰時間の算出
mean_return_time = np.mean(first_passage_times)
expect_mrt = (1/Theta)*np.log((abs(X0 - Mu))/ Delta)
# 以下の近似式は正しいかどうか不明。
#expect_mrt = approximate_first_passage_time(theta, sigma, delta,X0)
print(f"OU過程による平均第一通過時間: {mean_return_time:.4f}")
plt.show()
以下は、実行結果の、構成された時系列の最初の20個を表示した図です。
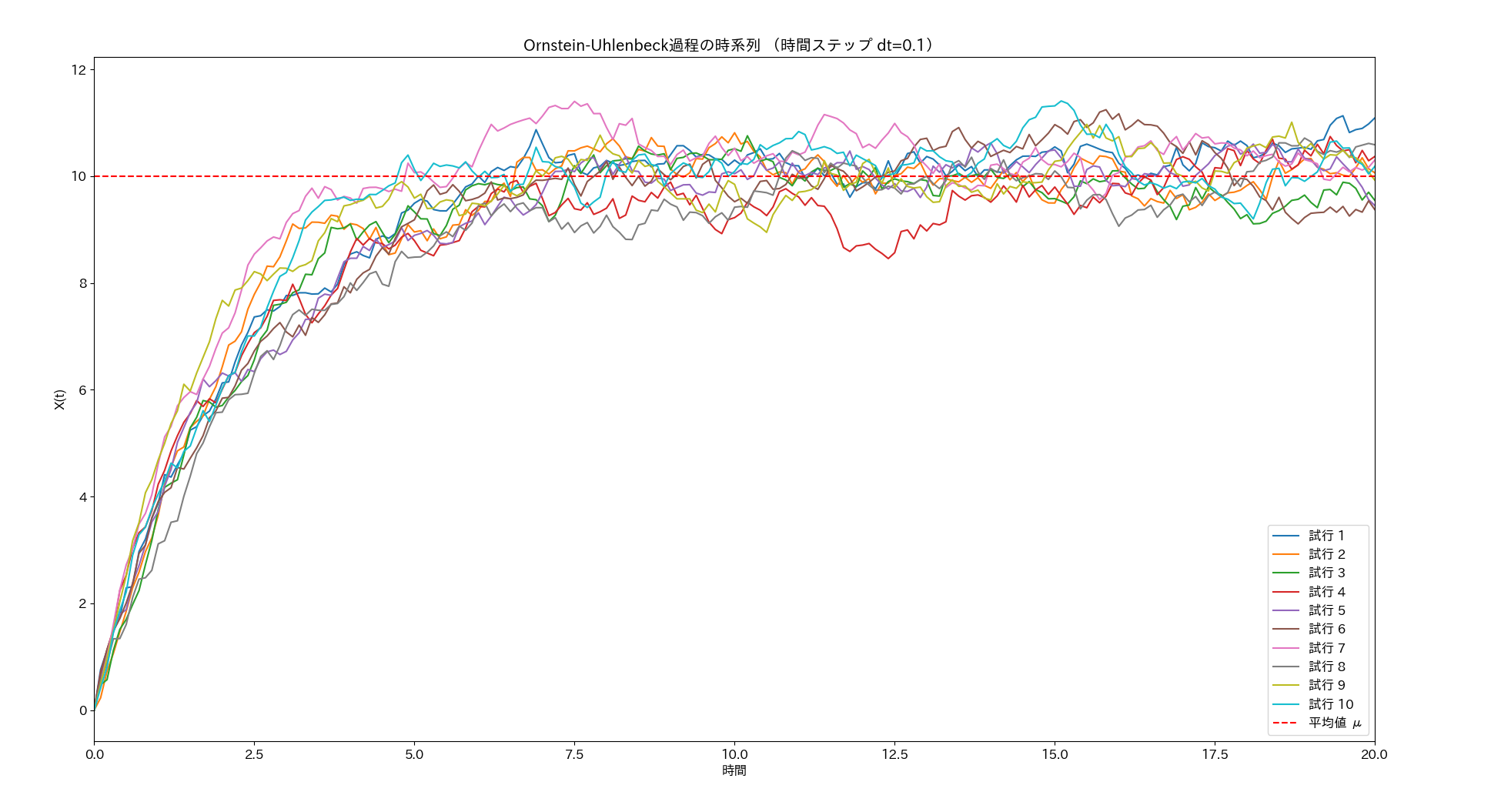
以下は、実行結果の、第一通過時間の分布を表すヒストグラムです。標本数を増やしたせいか、AR(1)の例と比較してさらにはっきり分布のロングテール性が観察されます。
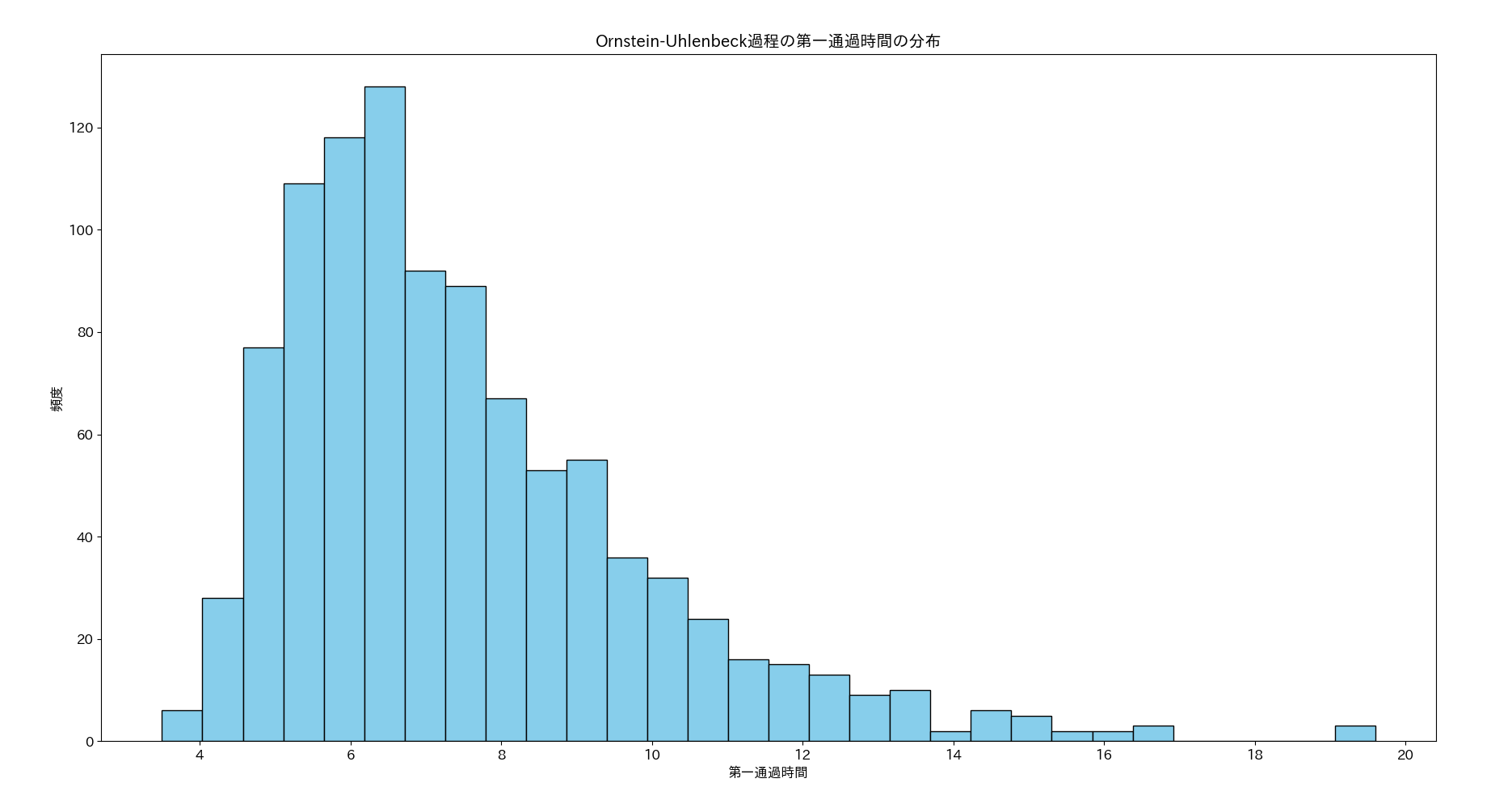
以下は、実行結果の、第一通過時間の分布の平均値と近似式による値の対比です。これも比較的近い値になっています。

2.3. 第一通過時間を見積もる#
実測したデータを基にして、今後予測できる平均回帰時間を算出するためには、何らかのモデル式を構築しておく必要があります。この章では AR(1) によってモデル化できる離散的な株価時系列は対象としていますので、AR(1) に基づく平均回帰時間のモデル式が欲しいところです。この目的のために、連続時間のOU過程によって株価データを近似し、平均回帰時間の見積りモデルをつくる、というアプローチをとります。
オルンスタイン・ウーレンベック過程の第一通過時間#
OU 過程 がしたがう確率分布を としたとき、 の遷移確率密度関数 は以下のように定義されます。
この関数の時間発展を記述する微分方程式はコルモゴロフの前方方程式、あるいはフォッカープランク方程式として知られる方程式によって表現することができます。フォッカー・プランク方程式 (FPE)は解析技術が蓄積されていますので、平均回帰時間を求めるための出発点とします。
初期条件は 、つまり経路は確率 1 で から出発するものとします。
第一通過時間と生存確率
2 節 1 項で言及しました第一通過時間(FPT) を、連続時間の確率過程でも定義します。時刻 で から出発して、 を通過する時刻の最小値を とします。
T は時系列の標本を観察するごとに変化する確率変数です。その確率分布 は次のように定義されます。
確率分布 は、第一通過時間が t より小さくなる確率です。これは言い換えれば時刻 t までに必ず領域外へ脱出する確率です。すると、 は時刻 t までに一度も領域外にでていない確率を意味します。その意味で S を生存確率と呼びます。生存確率 S という概念を利用すると数式の見通しが良くなり便利です。
対応する確率密度関数 は次のように与えられます。
の定義から、
したがって、
逆にいえば、 が計算できれば 、 を求めることができます。
平均第一通過時間(MFPT)と生存確率
平均第一通過時間(MFPT)は、 の期待値です。これは以下のように S の時間方向での全体積分として表すことができます。
この式を部分積分します。

なので、 です。従って、 が成り立つモデルでは、以下の関係が得られます。
生存確率は遷移確率密度から計算できる
生存確率 は、時刻 で位置 から始まった経路が時刻 までの間、区間 におさまっている確率のことでした。これは下記の境界条件に従う経路の遷移確率密度関数 によって表すことができます。
経路は境界 に吸収されるため、 は時間とともに減少し となります。
MFPT 方程式
遷移確率密度関数 は を変数と見たとき、フォッカープランク方程式の随伴方程式の解であることに留意します。ちなみにこの方程式は、時刻 t から過去方向を見た経路の状態を記述するという意味で、コルモゴロフの後方方程式という名称もよく使われています。
二つのフォッカープランク方程式より、
時刻を -t だけシフトします。
に対して積分を行います。左辺は、
右辺は、
両辺をさらに時間で積分します。
したがって、次の関係が得られます。
こうして得られた平均第一通過時間 に関する方程式を MFPT 程式と呼称します。これは非斉次の常微分方程式であるため、フォッカープランク方程式そのもの比べ取り扱いが容易です。
MFPT 方程式の解
OU 過程に対応するフォッカープランク方程式のドリフト項係数関数と拡散項係数関数は以下でした。
これを(2.3.9)に代入します。見やすくするため、空間変数はxに代えて、常微分方程式の形で表します。
説明はまた別の機会にしようと思いますが、一般的な関数 A(x,t),D(x,t) に対して、この方程式の一般解は次の形になります。
ここで、 は反射壁、 は吸収壁です。この一般解より OU 過程に対して最終的に以下の結果を得ます。
出発点を ,吸収壁を としたときの平均第一通過時間が明らかになりました。この積分はpython の数値計算用オープンソースソフトウェアを利用することで容易に算出することができます。以下のコードは、実際の株価データを基づいて構成したOU過程を使ってMFPTの一般解を見積もったものです。先のコードの実行結果から伺えるようにFPTの分布はロングテールになっています。ロングテールの分布に従う確率変数の期待値は往々に極端に大きくなることがあります。そのため参考としてモード(最頻値)も算出しています。
# math_mfpt_mode.py
#
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
from scipy.integrate import quad
import japanize_matplotlib
import matplotlib as mpl
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
# トヨタとデンソーのスプレッドをOU過程で推定したパラメータ
theta = 0.0625 # 平均回帰速度
sigma = 42 # 拡散係数
mu= -10.0 # 通過点(=平均値)
x0= mu - 200.0 # 初期値(約2σ)
def mfpt_integral(x0, L, theta, sigma):
"""平均回帰時間期待値を計算する"""
coef = 2 / sigma**2
def inner_integral(y):
return np.exp(-theta * y**2 / sigma**2)
def outer_integral(z):
inner_result, _ = quad(inner_integral, -np.inf, z)
return np.exp(theta * (z- x0)**2 / sigma**2) * inner_result
result, _ = quad(outer_integral, x0, L)
return coef * result
# 厳密解を用いた平均回帰時間期待値の計算
mfpt_exact = mfpt_integral(x0, mu, theta, sigma)
# モンテカルロ法による平均回帰時間分布のシミュレーション
num_simulations = 10000 # シミュレーション回数
dt = 0.01 # タイムステップ
fpt_samples = []
np.random.seed(42) # 再現性のためのランダムシード
for _ in range(num_simulations):
x = x0
t = 0
while x < mu: # 閾値を通過するまでシミュレーション
dx = theta * (mu - x) * dt + sigma * np.sqrt(dt) * np.random.randn()
x += dx
t += dt
fpt_samples.append(t)
fpt_samples = np.array(fpt_samples)
# 平均回帰時間のヒストグラム
plt.hist(fpt_samples, bins=50, density=True, alpha=0.6, label="FPT ヒストグラム")
# 平滑化のためのカーネル密度推定(KDE)
kde = gaussian_kde(fpt_samples)
t_values = np.linspace(fpt_samples.min(), fpt_samples.max(), 1000)
pdf_values = kde(t_values)
plt.plot(t_values, pdf_values, label="KDE(平滑化されたPDF)", color="red")
# 平均回帰時間の最頻値(モード)
most_frequent_fpt = t_values[np.argmax(pdf_values)]
plt.axvline(most_frequent_fpt, color="green", linestyle="--", label=f"モード: {most_frequent_fpt:.2f}")
plt.axvline(most_frequent_fpt*3, color="green", linestyle="--", label=f"モード*3: {most_frequent_fpt*3:.2f}")
# モード値以下のサンプルの割合を計算
below_mode_count = np.sum(fpt_samples <= most_frequent_fpt*3)
total_samples = len(fpt_samples)
probability_below_mode = below_mode_count / total_samples
# プロット設定
plt.xlabel("平均回帰時間")
plt.ylabel("密度")
plt.title("平均回帰時間の分布")
plt.legend()
plt.grid()
plt.show()
# 結果の出力
print(f"厳密解から計算した平均回帰時間期待値: {mfpt_exact:.2f}")
print(f"モンテカルロ法で計算した平均回帰時間最頻値: {most_frequent_fpt:.2f}")
print(f"平均回帰時間モード値の3倍以下になる確率: {probability_below_mode:.2%}")
実行結果からシミュレーションで得た平均回帰時間の分布をヒストグラム表示したものが以下です。モード値とモード値の 3 倍のところに縦線を描画しています。
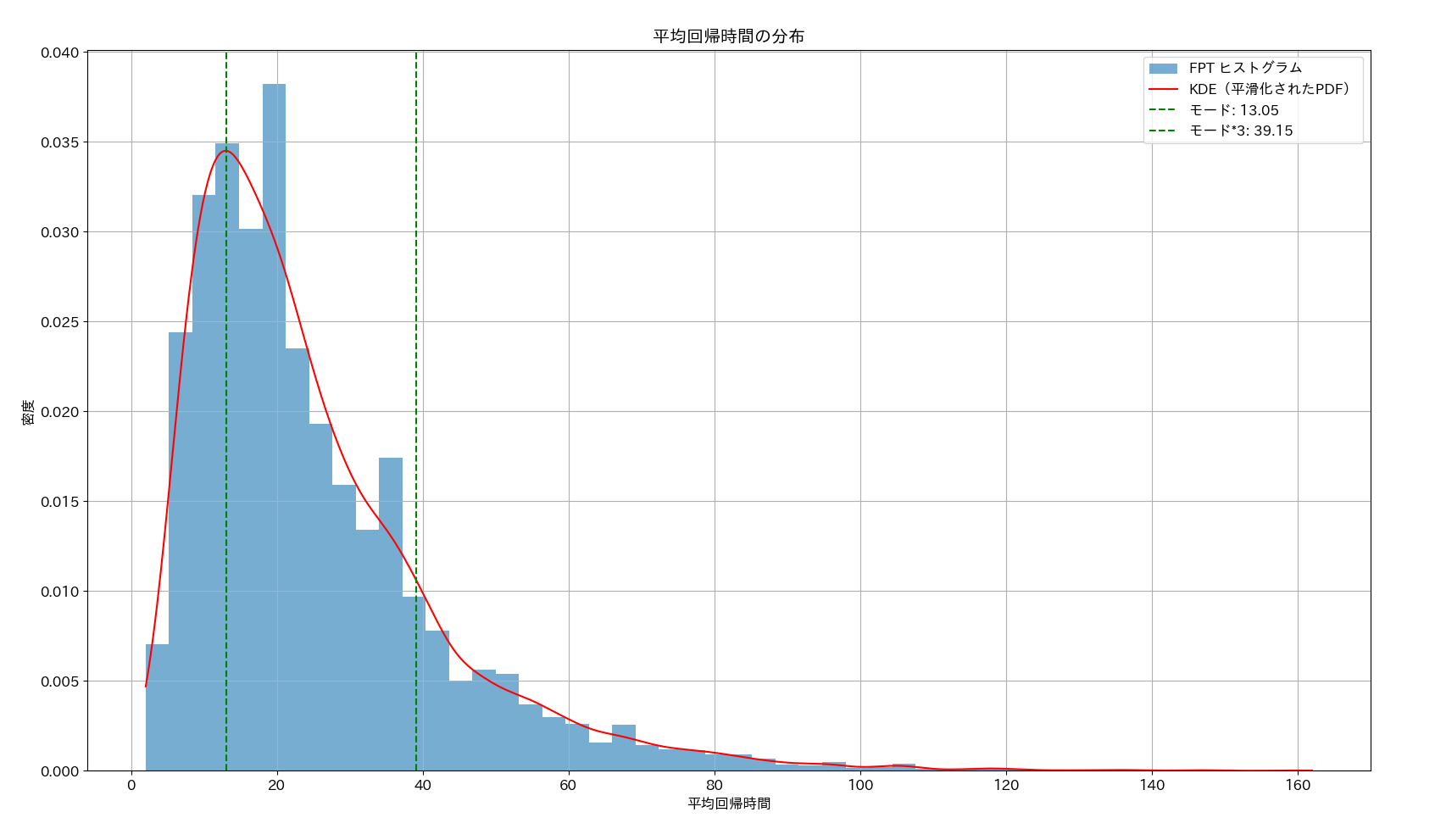
以下は、一般解を数値計算して得た平均回帰時間期待値と、回帰時間のモード値、モード値の 3 倍以下の平均回帰時間が観察された頻度を表示しています。これを見ると、モードの 3 倍まで観察日数を増やしたとき84%程度の頻度で平均回帰を目撃できる、という結果です。平均回帰時間期待値は17.5日です。そしてその3倍の52日までの間に高い確率で平均回帰を観察できるということです。

3. ペアトレーディング#
効率的市場仮説(Efficient Market Hypothesis: EMH)と呼ばれる株式市場における株価形成を説明する概念があります。
完全に効率的な市場においては、株価は、企業の価値を定量化した非確率的な指標値と、それを評価する市場参加者の行動や判断に潜むランダムネスのみで決定されます。そしてこのランダムネスはどのような規則性もないと想定されます。
このような性質に合致する株価モデルを構成するために、第 1 節で定義したランダムウォークがしばしば活用されます。単純ランダムウォークでは、時点tでの株価 を以下のように定義しました。
ここでは時刻 t によらず平均 0 かつ分散が一定の正規分布に従うホワイトノイズです。 効率的な市場のもとで投資家はどのようなリターンを期待できるでしょうか? 一般にランダムウォーク性を持つ時系列 は、以下の性質を持つことが知られています。
ここで、 は時刻 t までの利用可能な情報を表します。この性質をもつ時系列 を マルチンゲール(Martingale)と呼称します。 マルチンゲールが示しているのは株価がランダムウォークであるならば、明日の株価の期待値は今日の株価と同じ、つまり上がり、下がり、どちらに張っても見込めるリターンは残念ながらゼロ、ということです。
しかしながら現実の世界では完全に効率的な市場は存在しない、と考える人は多いようです。そのため第1章で述べたように、何らかの理由で生じた裁定機会をいち早く発見した場合に確実に利益を得る、いわゆる裁定取引手法が存在し、資金力のあるトレーダーにより実践されています。
3.1. 考え方#
統計的裁定取引(statistical arbitrage)は、相関の高い二つ以上の資産の価格差や比率が時間とともに平均に回帰する性質を利用して利益を得る投資手法です。実証的な研究の一例を文末に記載していますので興味のある方はアクセスしてみてください。
この手法では、価格差やスプレッドが過去の平均値から大きく乖離したときに、以下のポジションを取ります。
- 平均より上回っているとき:売り(ショート)
- 平均より下回っているとき:買い(ロング)
本稿では、統計的裁定取引の良く知られたパターンである株式のペアトレーディングを題材として解説します。この手法は日足データを観察し、現物取引と信用取引を組み合わせて実行できるため、個人投資家にとって試しやすい手法と言えます。
ペアトレーディングは、二つの銘柄の株価差異を表すスプレッドが時系列として平均回帰性を持つことを前提として成立します。そのため株価を近似するための時系列としては、離散時間上で定義される AR(1) モデル、あるいは連続時間上で定義される OU 過程のどちらも使うことができます。筆者は日足の株価を参照する取引に親しんでいるため本稿での説明は AR(1) モデルを想定して行います。Ornstein-Uhlenbeck 過程に特有の事項がある場合は随時補足します。
取引の流れ
1. ペア候補の選定
ペアトレーディングの第一歩は、スプレッドが平均回帰性を持つ可能性が高い二つの銘柄ペアを見つけることです。一般論として、同一セクターの銘柄(航空業界での A 社と B 社)は比較的候補を見つけやすいと言われています。
まず最初にピックアップしたふたつの銘柄 A,B が単位根過程(シンプルランダムウォーク)に従っていることを確認します。
次に共和分検定を用いて、スプレッドが定常的であることを確認します。これは具体的には、銘柄価格 , の線形結合でスプレッド を定義し、
が下記のような定常過程になる 、回帰係数 を推定する作業です。
もしこの探索が成功した場合、平均回帰時間を目安として、スプレッドが解消される、すなわち平均値(この場合は )へ回帰すると見込むことができます。
上記の手続きは、保有するパソコンやクラウドリソースの性能が許せば、狙いをつけたセクターを総当たりとして実行することで、条件の良い候補を発見する可能性を上げることができるでしょう。
2. 取引のエントリーとエグジット:
スプレッドが平均値から一定の閾値 L を超えて乖離した場合に取引を開始します。L の決め方は自分の目標次第かと思いますが、あまり大きすぎる値を設定すると当然ながら取引の開始ポイントが出現しない恐れがありますので、標準偏差の 2 倍(いわゆる 2σ )内が適当かと思います。
- エントリー
- : を信用売り、 を現物買いする。
-
: を現物買い、 を信用売りする。
-
エグジット
- スプレッドが平均値へ近づき、あらかじめ定めた利益条件を満たしたタイミングで反対取引を行いポジションを閉じる。
3. リスク管理
ペアトレーディングに伴うリスクを低減させるための主要なポイントを整理しておきます。
- 打ち切り条件を設定すること
- スプレッドが閾値を超えた後も、一定期間経過しても平均に回帰しない場合、ポジションを解消します。
-
打ち切り時間の目安は、平均回帰時間を参考に設定。
-
ボラティリティをウォッチする
- スプレッドの分散 が大きすぎる場合は、取引を控えます。
-
実現損益が想定を大きく超える場合、早期にポジションを解消します。
-
モデルを継続的に検証する 選定した銘柄は今日単位根性を示したとして、明日も間違いなく単位根性を示すとは限りません。また、選定したペアA,Bが明日も共和分性を必ず示すとは限りません。このためモデルの推定をこまめに行い、パラメータを更新すること、銘柄ペアの探索を更新することが望ましいです。
3.2. 実装#
前項の概念説明に従って、実際の株価でペアトレーディング戦略を試すためのコードを作成します。コードの目的は、ペアトレーディングの対象となる銘柄ペアを探索です。探索された銘柄ペアに対しては、前項の流れに沿って取引をすすめます。
コードに関する補足
- 輸送機器セクターから自動車関連7社を探索対象とする
- 過去1年間の株価データから候補を探索する
- 対象に対して共和分検定を行いペアトレーディング候補をピックアップする
- スプレッドの計算とAR(1)モデルへのフィットを行う
- 平均回帰時間を見積もる関数 mfpt_compute() のなかで、スプレッドが拡大した場所(2*spread_std) から平均値へ回帰する設定。
# math_ar1_pairtrade.py
# ペアトレード候補銘柄を探索する
import pandas as pd
import numpy as np
from statsmodels.tsa.stattools import coint, adfuller
from statsmodels.regression.linear_model import OLS
from statsmodels.tsa.ar_model import AutoReg
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語対応
import warnings
import matplotlib as mpl
from scipy.special import erf
from scipy.integrate import quad
import yfinance as yf
def get_data(code, index_as_date=True, start_date=None, end_date=None, interval="1d"):
df = yf.download(code, start=start_date, end=end_date, interval=interval)
# MultiIndex対策
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
df.index = pd.to_datetime(df.index)
df = df.rename(columns={
"Open": "open",
"High": "high",
"Low": "low",
"Close": "close",
"Adj Close": "adjclose",
"Volume": "volume",
})
if not index_as_date:
df = df.reset_index().rename(columns={"Date": "date"})
df["ticker"] = code
return df
# フォントサイズの全体設定
mpl.rcParams['font.size'] = 12 # 全体のフォントサイズを12ptに設定
def get_price_data(tickers, start_date, end_date):
"""
銘柄リストから株価データを取得する
"""
data = {}
for ticker in tickers:
try:
df = get_data(ticker, start_date=start_date, end_date=end_date)
data[ticker] = df['close']
except Exception as e:
print(f"銘柄 {ticker} のデータ取得に失敗しました: {e}")
return pd.DataFrame(data)
def find_cointegrated_pairs(data):
"""
共和分検定を行い、共和分性があるペアを見つける
"""
n = data.shape[1]
pairs = []
for i in range(n):
for j in range(i+1, n):
ticker1, ticker2 = data.columns[i], data.columns[j]
score, p_value, _ = coint(data[ticker1], data[ticker2])
if p_value < 0.05: # 共和分関係があると判断
pairs.append((ticker1, ticker2))
return pairs
def estimate_spread_coefficients(price1, price2):
"""
スプレッドの係数(beta)を最小二乗法で推定
spread = price1 - beta * price2 の形で定義
"""
X = price2.values.reshape(-1, 1) # price2を特徴量とする
Y = price1.values # price1を目的変数
model = OLS(Y, X).fit() # 最小二乗法による回帰
beta = model.params[0] # 回帰係数(beta)
return beta
def estimate_ou_params(spread):
"""
OU過程のパラメータをAR(1)推定結果から換算(回帰係数θ、平均値μ、ノイズの標準偏差σ)
https://math.stackexchange.com/questions/345773/how-the-ornstein-uhlenbeck-process-can-be-considered-as-the-continuous-time-anal
"""
# AR(1)モデルを使用してOU過程のパラメータを推定
model = AutoReg(spread, lags=1).fit()
# phi -> theta
phi = model.params[1]
theta = -np.log(phi) # AR(1)係数から推定されるθ
# 平均値μはAR(1)の定常状態
mu_ar = model.params[0]
mu_ou = mu_ar / (1 - phi)
# ノイズの標準偏差は残差の標準偏差として推定
sigma_ar = np.std(model.resid)
sigma_ou = sigma_ar * np.sqrt(2 * theta / (1 - np.exp(-2 * theta)))
print(f"Φ= {phi}, mu_ar= {mu_ar}, sigma_ar= {sigma_ar}")
print(f"θ= {theta}, mu_ou= {mu_ou}, sigma_ou= {sigma_ou}")
return phi,theta, mu_ou, sigma_ou
def calculate_mean_reversion_time(phi,mu,x0,delta):
"""
平均回帰時間を計算
"""
# 第一到達時間の近似式を用いた期待値。
theta = - np.log(phi)
expected_time = (1 / theta) * np.log(abs(x0 - mu) / delta)
return expected_time
def mfpt_compute(theta, sigma,x0, b,mu):
"""平均回帰時間期待値を計算する"""
coef = 1 / sigma**2
def inner_integral(y):
return np.exp(-theta * (mu -y)**2 / (2*sigma**2))
def outer_integral(z):
inner_result, _ = quad(inner_integral, -np.inf, z)
return np.exp(theta * (mu -z)**2 / (2*sigma**2)) * inner_result
result, _ = quad(outer_integral, x0, b)
return coef * result
if __name__ == "__main__":
warnings.simplefilter('ignore')
# 銘柄リスト
tickers_label = {"7201.T":"日産自動車","7203.T":"トヨタ自動車","7211.T":"三菱自動車", "7269.T":"スズキ", "7270.T":"SUBARU", "7261.T":"マツダ","7267.T":"ホンダ","6902.T":"デンソー"}
tickers = ["7201.T","7203.T", "7269.T", "7270.T", "7261.T","7267.T","6902.T"]
start_date = "2023-11-20"
end_date = "2024-12-19"
# データ取得
price_data = get_price_data(tickers, start_date, end_date)
price_data.dropna(inplace=True) # 欠損値を除去
print(price_data)
# 共和分性のあるペア探索
pairs = find_cointegrated_pairs(price_data)
print("\n")
print("共和分性のあるペア:", pairs)
# スプレッドの主要パラメータ推定
for pair in pairs:
print("\n")
ticker1, ticker2 = pair
price1 = price_data[ticker1]
price2 = price_data[ticker2]
# 最小二乗法でbetaを推定
beta = estimate_spread_coefficients(price1, price2)
print(f"スプレッド: {tickers_label[ticker1]} - {beta:.4f} * {tickers_label[ticker2]}")
# スプレッドを計算
spread = price1 - beta * price2
# AR(1) モデルでフィット
phi,theta, mu_ou, sigma_ou = estimate_ou_params(spread)
print(f" AR回帰係数 (Φ): {phi:.4f}")
print(f" OU回帰速度 (θ): {theta:.4f}")
print(f" 平均値 (μ): {mu_ou:.4f}")
print(f" ノイズの標準偏差 (σ_ou): {sigma_ou:.4f}")
# スプレッドの標準偏差を基に閾値を設定
spread_std = np.std(spread)
print(f" スプレッドの標準偏差*2 : {2*spread_std:.4f}")
upper_threshold = mu_ou + 2 * spread_std # 平均+2標準偏差
lower_threshold = mu_ou - 2 * spread_std # 平均-2標準偏差
mean_reversion_time = mfpt_compute(theta, sigma_ou, lower_threshold,mu_ou,mu_ou)
print(f" 平均回帰時間: {mean_reversion_time:.0f} 日")
# スプレッドが閾値を超えたタイミングを検出
upper_crossings = spread[spread > upper_threshold].copy() # 閾値を超えたデータポイントを Series として取得
lower_crossings = spread[spread < lower_threshold].copy() # 下閾値を超えたデータポイントを Series として取得
# スプレッドのプロット
plt.figure(figsize=(10, 5))
plt.plot(spread, label=f"スプレッド ({tickers_label[ticker1]} - {beta:.4f} * {tickers_label[ticker2]})", color='blue')
plt.axhline(mu_ou, color='red', linestyle='--', label='平均値 μ')
plt.axhline(upper_threshold, color='green', linestyle='--', label='上閾値 (μ + 2σ)')
plt.axhline(lower_threshold, color='green', linestyle='--', label='下閾値 (μ - 2σ)')
# 上閾値を超えたタイミングに垂直線とアノテーションを追加
for date, value in upper_crossings.items(): # Seriesのアイテムを取得
plt.axvline(date, color='purple', linestyle='--', alpha=0.7, label='上閾値越え' if date == upper_crossings.index[0] else "")
plt.text(date, value, f"{date.date()}", rotation=45, color='purple', fontsize=9, verticalalignment='bottom')
# 下閾値を超えたタイミングに垂直線とアノテーションを追加
for date, value in lower_crossings.items(): # Seriesのアイテムを取得
plt.axvline(date, color='orange', linestyle='--', alpha=0.7, label='下閾値越え' if date == lower_crossings.index[0] else "")
plt.text(date, value, f"{date.date()}", rotation=45, color='orange', fontsize=9, verticalalignment='top')
plt.title(f"スプレッド: {tickers_label[ticker1]} - {tickers_label[ticker2]}")
plt.xlabel("日付")
plt.ylabel("スプレッド")
plt.legend()
plt.grid(True)
plt.show()
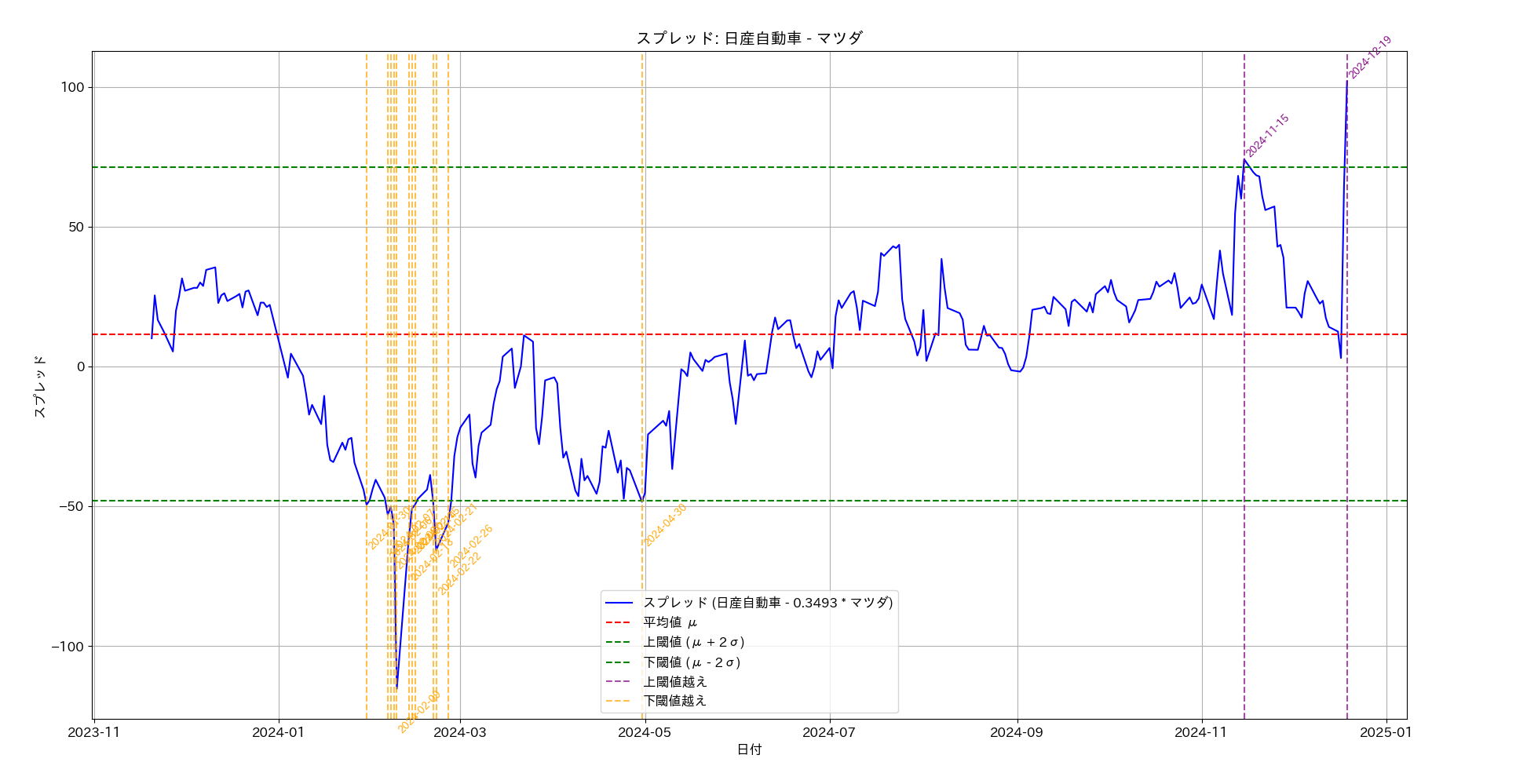
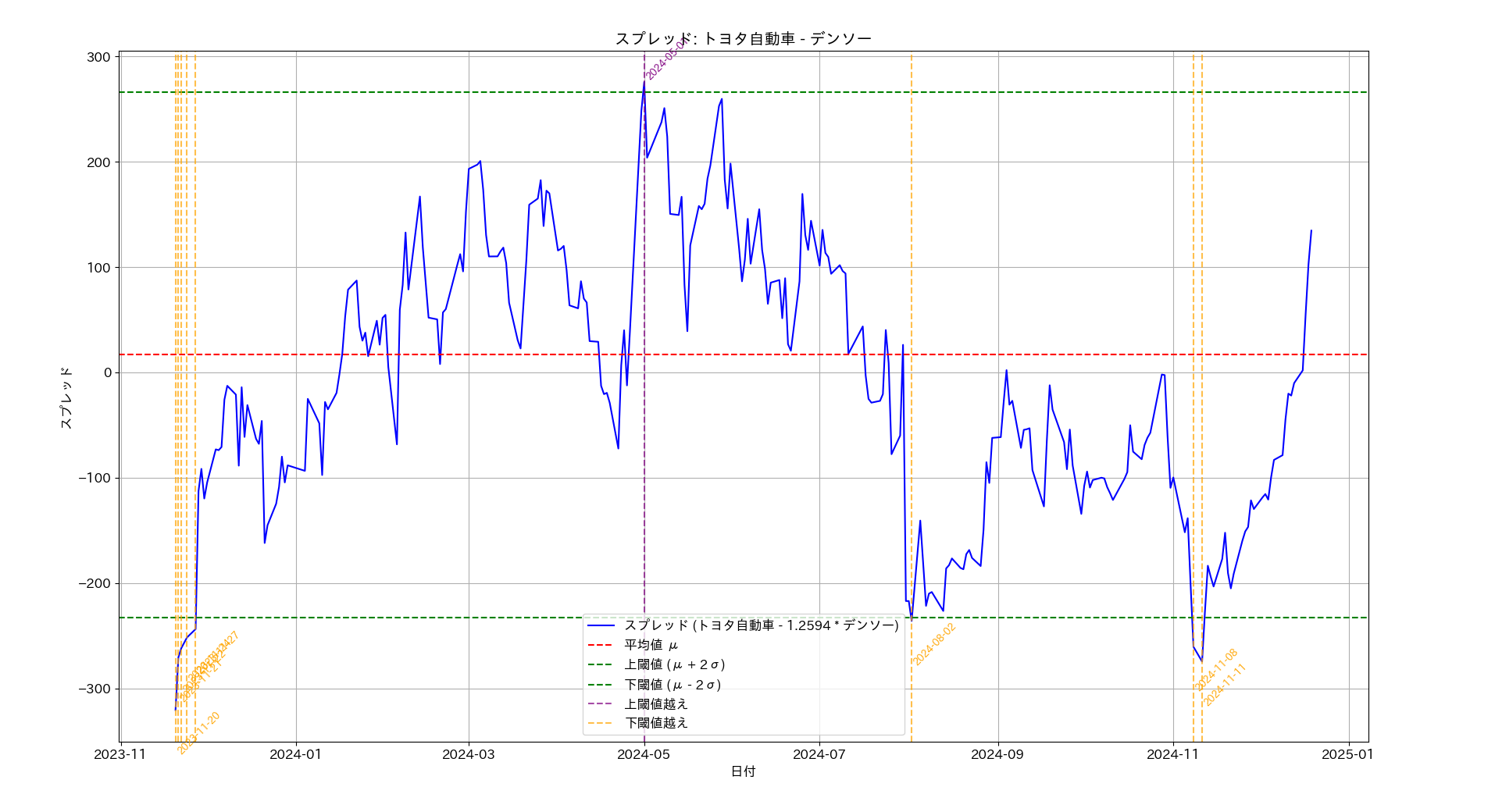
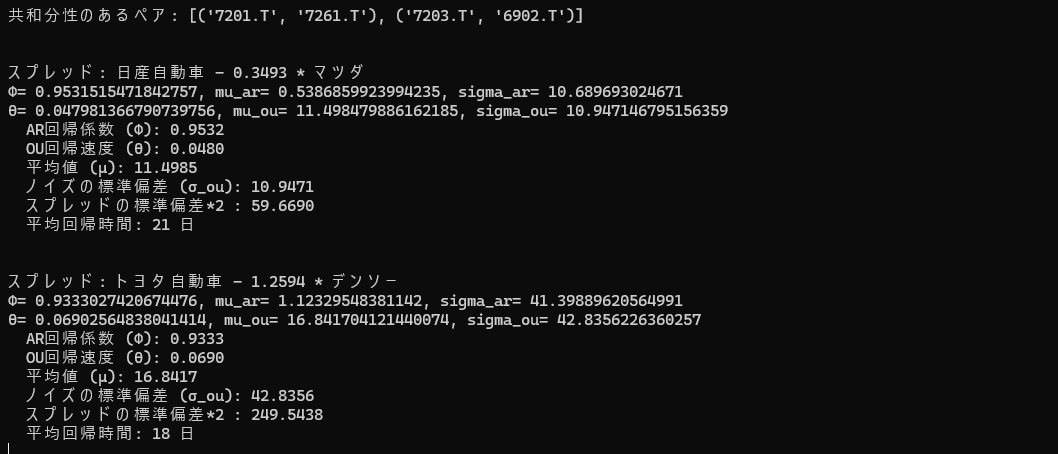
探索した結果 2 件のペアが見つかりました。
推定したパラメータ、近似式による平均回帰時間の結果です。
【続く作業について】
実験の結果、ペアトレーディングの対象となる銘柄として、(日産、マツダ)と(トヨタ、デンソー)が見つかりました。平均回帰時間を見ると、双方おなじような日数ですが、(トヨタ、デンソー)のほうがスプレッドの幅が大きめであり、取引が成功した場合の利益を多く見込めます。そこでこの銘柄ペアを選択することにします。
スプレッド S は、
S = 株価(トヨタ自動車) - 1.2594 * 株価(デンソー)
チャート上にプロットされていますが、直近では 11 月 11 日にマイナス方向でスプレッドが閾値を超えています。そこで時間を巻き戻して、探索の期間を 2023 年 11 月 12 日から 2024 年 11 月 11 日に変更してプログラムを実行してみます。つまり今が11月11日の後場が終了して、最新株価で探索をしようとしているところだと想像してください。
すると、うまい具合に 2024 年 11 月 11 日時点でもペアトレーディングの対象として(トヨタ、デンソー)は検出されます。スプレッドがマイナス乖離なので、3 節 1 項の取引開始の条件の通り、トヨタを現物買い、デンソーを信用売りによりエントリーします(あくまで仮定です)。
本項を執筆している 12 月 21 日時点で、首尾よくエグジット条件に達しています。この設定ではかなり大きなスプレッドをエントリー条件に設定していますが、上記のスプレッドのチャートを見るとわかるように、もう少し条件を緩和しますとその分、成功裏にエグジットできる頻度も増えると思われます。
ペアトレーディングは銘柄ペアさえ探索できてしまえば、後はエントリーして結果をじっくり待つだけなので、平日仕事で多忙の社会人の個人投資家にも手掛けやすい手法ではないでしょうか。しかも、銘柄を選ぶ際にテクニカルチャートやらファンダメンタル情報やらを気にする必要すらありません。やるべきことはスプレッドの動きが確率の法則に従って動いてくれることを日々祈るだけです。
2026年3月追記
株価データ取得ツールをyahoo_finからyfinanceに移行しましたので再度同じ日付で実行すると、
得られる数値が微妙に変わっていました。結果として検出された共和分ペアはトヨタとデンソーの
1ペアだけでした。株価過去データの見直しがあった可能性もありますが、原因は特定していません。
期間を変えてみたり、他の業種ペアも試してみると面白いと思います。例えば上記の自動車業界で、
対象を2025年に変えるとまた他の共和分ペアを見つけることができます。
この章の参考文献とリンク#
参考 9:株式売買における統計的裁定のパフォーマンス 石鎚英也 専修大学学術機関リポジトリ
参考 10:Wiki First-hitting-time model
参考 11: Enzo Orlandini, University of Padova,"First passage times and escape rates" (注)1-dのOU過程のMFPTの解析的な解が書かれている。講義用の教科書のようで公開期間や利用基準が不明。
参考 12: lrich Schwarz,Heidelberg University,Department of Physics and Astronomy,"Stochastic Dynamics" (注)1-dのOU過程の一般解、MFPTを近似した式が書かれている。講義用の教科書のようで公開期間や利用基準が不明。