第4章 時系列を分析する#
はじめに
本章の構成について説明します。
時系列データを分析するにあたって第一の関門となるのが、取り扱うデータを分析可能なものにすることです。一般に原データは性質の異なる複数の成分の混合によりできています。第1節ではこの混合を見極め分析を容易にできるよう原データを整形する方法をみていきます。
次の関門は時系列が定常的であるのか非定常的であるのかを見極めることです。非定常系列は分析の難度が高いといわれます。とりわけ回帰モデルに基づく分析では、非定常系列に特有のみせかけの回帰とよばれる事象を導き出さないようデータを事前確認することがきわめて重要となります。 第2節では自己回帰モデルの重要な例である和分過程の基本的な性質をまとめています。そして実践的な事例として、米国の2年物国債金利が10年物国債金利に対して因果性を持つのかどうかを確認するコードを作成します。
自己回帰モデルはもっともポピュラーな時系列分析用モデルですが、実際の応用では扱う事象に適した様々なモデルが開発され、活用されています。続く節では応用でよく活用される分析モデルを取り上げ、金融・経済系をを中心とした時系列分析での活用方法を具体的に説明していきます。第 3 節では移動平均モデル(MA、ARMA、ARIMA)を、第 4 節では分散不均一モデル(ARCH、GARCH)を見ていきます。 サンプルコードとして総務省の家計調査統計を使った予測を行ってみます。
第5節ではAR系、MA系を含む広範な時系列の構造を状態空間モデルとして取り扱うことで制御理論やシステム理論で蓄積された有用な技法を活用できることを説明します。この節ではトヨタ自動車の株価推移を状態空間モデルを使い予測するコードを掲載しています。そして株価の予測に時系列分析ツールを使うことの妥当性について少々私見をつけました。
内容に入る前に時系列予測の作業の典型的な流れを紹介しておきましょう。
-
データの収集
目的変数(Y)と説明変数(X)のデータを収集する。例えば、商品の売上(Y)と広告費用(X)のデータがあったとして商品の売上を予測したい場合、広告費用が説明変数となります。また、説明変数が複数になる場合は例えば、住宅価格Yを予測する場合、部屋の広さ(X1)、バスルームの数(X2)、地理的な位置(X3)などを説明変数として収集します。 -
データの整備とモデルの選択
適切な回帰モデルを選択する。説明変数がひとつであれば単回帰分析、複数の説明変数がある場合には重回帰分析を検討する必要がでてきます。そしてモデルが前提とする条件に合致するよう、データの分解、加工、検定などの手法を駆使してデータを整備します。このステップで失敗や漏れがあると後の分析結果自体が意味のないものとなる可能性があります。これらの作業の結果分析対象が定常過程になれば分析が難度は下がるでしょう。 -
パラメータ推定
単回帰モデルでは切片 と回帰係数 の値をデータから推定します。このために最小二乗推定(Least Squares Estimation, LSE)を使うことが一般的です。なぜならば定常過程の要件である正規分布性と等分散性が成り立つ場合、回帰モデルのパラメータを解析的に最適化でき計算が比較的簡単になること、また最小二乗法は推定量が最尤推定量と一致する特別なケースでもあることが知られており統計的性質が良好であるためです。 -
モデルの評価
推定された回帰モデルの性能を評価します。、MSE、MAE、RSD、など様々な手法が知られています。これらについては後述します。 -
予測と解釈
推定された回帰モデルを用いて新たなデータの予測を行うことができます。また、回帰係数の解釈を行い、説明変数が目的変数にどのような影響を与えるかを理解します。 -
結論と報告
分析の結果をまとめ、報告書やグラフを用いて結論を示します。統計的な有意性や予測の信頼性についても報告します。
1. 時系列データの整形#
分析の対象としたい現実の時系列データは様々な要因により理論が要求する整った形になっていないことが通例です。本書では以下に列挙した性格をもつ成分から加法的あるいは乗法的に合成される時系列データを想定します。加法は足し算なのでなじみやすいですが、我が国の経済統計データは、乗法的分解モデルの方が適合するとの考え方が一般的なようです(参考:季節調整手法 経産省)
- 「トレンド(長期変動)」: 長期的な増加あるいは減少を示す成分。例)GDP推移
- 「循環性変動」: 定まった周期がなく長期間をかけて上昇と下降を繰り返し変動を見せる成分。例)景気変動
- 「季節性変動」: 決まった月や日付など季節要因の影響を受けることで生じる成分。例)電力需要
- 「不規則性変動」: ランダムな変動を見せる成分 例)地震の発生
加法的に分解できる時系列データの場合は、
乗法的に分解できる時系列データの場合は、
上記で、
Yt :時点t での時系列データの観測値(データポイント)
Tt :トレンド・循環性変動成分
St :季節性変動成分
Rt :残差成分(不規則性変動他の要因を表す)
トレンド・循環性変動を分析したいとき時系列データに毎年定期的に現れる季節性変動が混入しているとデータを見誤る恐れがあるのでその目的のためにはトレンド・循環性変動と季節性変動を分離する必要があります。原データから季節性変動を除去したあとのデータを「季節調整値」といいます。
加法的に分解される場合は原データから季節性変動を引き算して季節調整値を得る
乗法的に分解される場合は原データから季節性変動を除算して季節調整値を得る
1.1. STL分解#
与えられた時系列データを分解する方法として移動平均を用いてトレンドを抽出する古典的(伝統的)分解法のほか、「STL(Seasonal and Trend decomposition using Loess)分解」と呼ばれる時系列データをトレンド・循環成分、季節成分、残差成分の三つの成分に分解するための手法がよく知られています。これらの手法はオープンソースのツールにおいても整備されているため活用をお勧めです。我が国では政府系のデータの整備はいくつかの手法の並立を経て移動平均の欠点を改良したX-12-ARIMAの導入が進んでいるようです(前出の参考資料「季節調整手法 経産省」)。
以下はSTL分解の手順です。
-
局所的な平滑化 (Local Smoothing)
ローカルな平滑化(Loess平滑化)を使用して、データからトレンド成分を推定する。この手法はデータの中の小さな局所的な変動を平滑化し、トレンドを捉える。 -
トレンドの削除 (Detrending)
推定されたトレンド成分を元のデータから差し引き、トレンドを削除する。これにより、データからトレンドの影響を取り除く。 -
季節成分の分離 (Seasonal Separation)
トレンドを削除したデータに対して、季節成分を抽出する。季節成分は通常、データ内の特定の周期に対する平均的な変動を表す。 -
残差の計算 (Residual Calculation)
トレンドと季節成分を削除したデータから残差成分を計算する。残差成分は、トレンドと季節性に説明されないデータの変動を示す。
サンプルとして使うデータはKaggleが公開している時系列データ(AirPassengers.csv)です。これをダウンロードし、以下のソースプログラムと同じディレクトリに配置します。(Kaggleのサイトへ行く)
以下のコードで参照している statsmdoels STL クラスの仕様、例題集は以下からアクセスできます
# tsa_decomp_stl2.py
# STLクラスを使った時系列の分解を行い結果チャートをひとつのサブプロットに重ねる
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import STL
# 時系列データの読み込み(例)
data = pd.read_csv('AirPassengers.csv', index_col='Month', parse_dates=True)
# STL分解の実行
stl = STL(data['Passengers'], seasonal=13) # 季節周期を指定(例では13)
# 分解結果の取得
result = stl.fit()
# トレンド、季節、残差の成分を取得
trend = result.trend
seasonal = result.seasonal
residual = result.resid
# 4つの成分を一つのsubplotに重ね合わせてプロット
plt.figure(figsize=(12, 6))
plt.plot(data['Passengers'], label='Original Data', color='blue')
plt.plot(trend, label='Trend', color='green')
plt.plot(seasonal, label='Seasonal', color='red')
plt.plot(residual, label='Residual', color='purple')
plt.legend(loc='upper left')
plt.title('STL Decomposition')
plt.show()
このプログラムを実行すると以下のように4種類に分解された時系列データのチャートが表示されます。
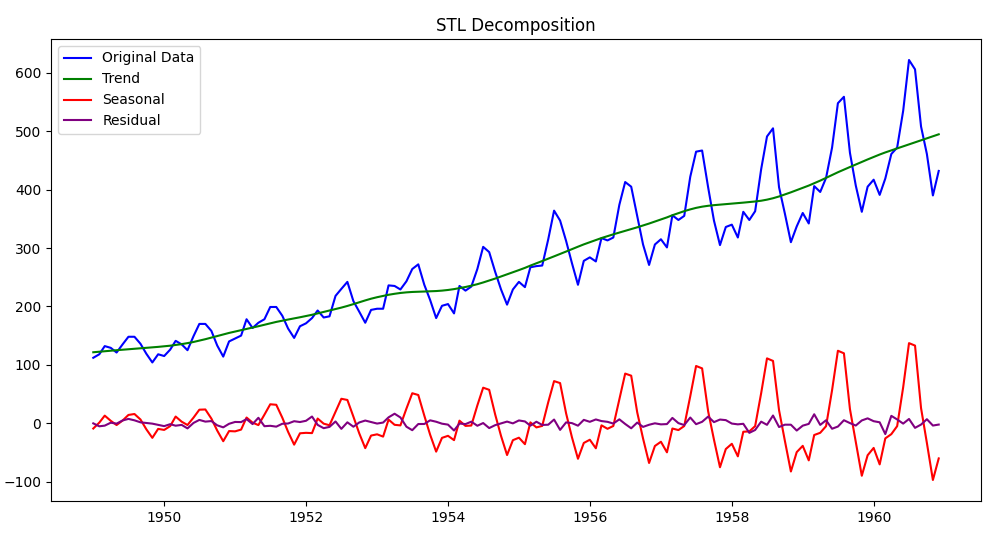
STL分解は通常、データの加法的な性質を前提として設計されているため直接には乗法分解には対応できません。乗法的な季節成分とトレンド成分を分解するためには例えばデータに対数変換を適用し、乗法的な季節成分とトレンド成分を加法的な性質に変換した後STL分解を適用します。
さらに加法性も乗法性も不十分な時系列の分解には「Box-Cox変換」を使うことができます。これは対数変換を拡張して、変換後の時系列データの各時点の分布が正規分布に近づくように以下の定義式におけるパラメータλを調整する手法です。
1.2. Box-Cox変換による分解#
同じくstatsmodelのクラスで複数の季節変動成分を扱うことができるMSTLクラスがBox-Cox変換をサポートしているのでサンプルコードを示します。このサンプルでは乗法合成されているデータ(サンプルデータ2)を作りMSTLクラスで分解する処理をしています。コメント化した部分(サンプルデータ1)は参考のために複数の季節変動を含むデータを加算合成で定義しています。
#
# tsa_boxcox.py
# MSTLクラスを使い乗法モデルの時系列をSTL分解する
import statsmodels as sm
from statsmodels.tsa.seasonal import MSTL
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
np.random.seed(0)
# サンプルデータ1
# リニアに成長するトレンド、一日周期と1週間周期の季節変動、ランダム変動を加算で合成
# np.random.seed(0)
# t = np.arange(1, 1000)
# trend = 0.0001 * t ** 2 + 100
# daily_seasonality = 5 * np.sin(2 * np.pi * t / 24)
# weekly_seasonality = 10 * np.sin(2 * np.pi * t / (24 * 7))
# noise = np.random.randn(len(t))
# y = trend + daily_seasonality + weekly_seasonality + noise
# index = pd.date_range(start='2000-01-01', periods=len(t), freq='H')
# data = pd.DataFrame(data=y, index=index)
# 時系列データのパラメータ
# サンプルデータ2
# リニアに成長するトレンド、12か月周期、ランダム変動を乗算で合成
n = 100 # データポイント数
time = np.arange(1, n + 1)
trend_component = 0.5 * time # トレンド成分(線形成分)
seasonal_component = 0.5 * np.sin(2 * np.pi * time / 12) # 季節成分(年周期の正弦波)
random_component = np.random.normal(0, 0.1, n) # ランダム成分(ノイズ)
# print(random_component)
# トレンド、季節成分、ランダム成分を掛けてデータを生成
original_data = (1 + trend_component) * (1 + seasonal_component) * (1 + random_component)
index = pd.date_range(start='2000-01-01', periods=n, freq='M')
data = pd.DataFrame(data=original_data, index=index)
# データのプロット
plt.figure(figsize=(6, 3))
plt.plot(data, label='Original Data')
plt.legend()
plt.title('Original Time Series Data')
plt.xlabel('Date')
plt.ylabel('Value')
plt.grid(True)
# MSTL関数を使用して季節成分を分解
# lmbdaを設定するとBox-Cox変換が適用される.
# lmbda がNone の場合変換は適用されない. "auto"の場合Box-Cox変換が適用され
# 対数尤度関数を最大化するλパラメータ値が用いられる
result = MSTL(data, lmbda="auto").fit()
# 戻り値はDecomposeResultクラスのインスタンスで以下のメンバーをもつ
# observed: 分解される元データの配列.
# seasonal: 季節変動成分の配列.
# trend: トレンド成分の配列.
# resid: 残差成分の配列
# weight(option): 外れ値の影響を軽減するために使用される重み.
result.plot()
#plt.tight_layout()
plt.show()
オリジナルのデータは以下。
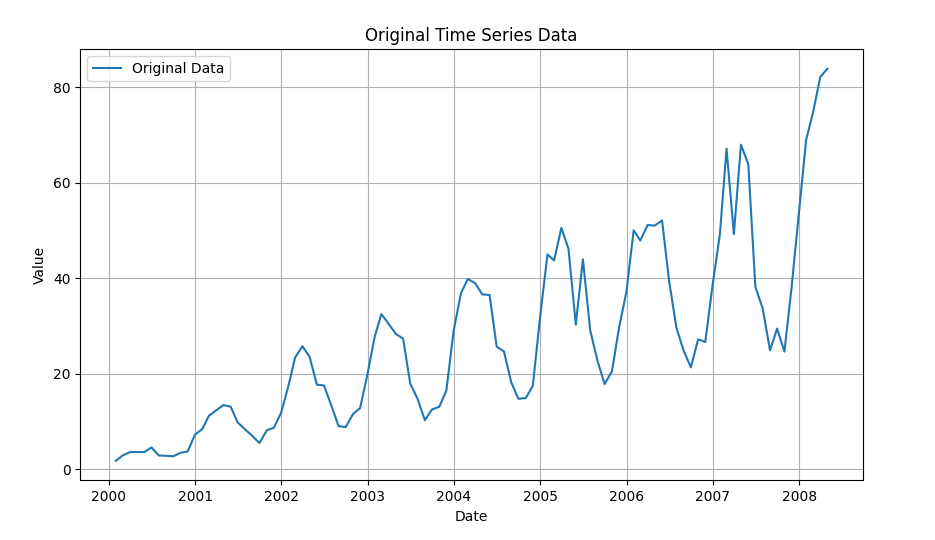
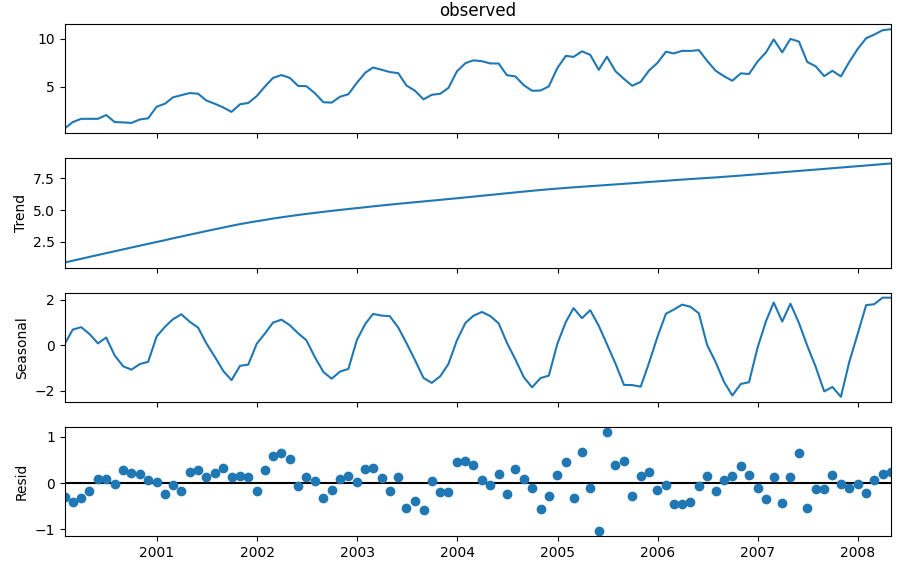
このプログラムを実行すると以下のように分解された時系列データのチャートが表示されます。
これまでの説明で分析の目的に応じて原データをトレンド(T)、循環変動(C)、季節変動(S)、残差(R)に分解する手続きを見てきました。以降では時系列をもとにした回帰分析による予測の手法の有用性を確認していこうと思いますが、その前の重要なステップとして時系列データに対して数理的な技法を適用しやすくするための前処理の方法を補強しておきます。
【入手が容易な時系列データの例】
時系列統計データ 日本銀行
過去の気象データ検索 気象庁
e-Stat 政府統計の総合窓口 独立行政法人統計センター
世界銀行の各種統計データ
1.3. データを正規化する#
時系列データの「正規化」とは、データを特定の範囲や形式に変換することでデータを比較や分析しやすくすることを目的とし、モデルの訓練や予測を向上させるためのデータ前処理を指します。例えばデータがとる値の範囲が大きく異なる複数の時系列データを扱う場合、正規化を行わないと、一部の系列データが他の系列データに比べてモデルに対する影響が大きくなり、モデルの収束や性能が悪化することがあるといわれています。
Min-Max正規化
データポイントの最小値と最大値を使って、データを特定の範囲(通常は0から1)にスケーリングする方法です。式で表すと以下のようになります。
正規化後の値 = (値 - 最小値) / (最大値 - 最小値)
機械学習のライブラリのsklearnを使うので、まだ導入していない場合にはインストールします。
pip install scikit-learn
以下は機械学習ではよく使われるMin-Max正規化の例です。
# tsa_norm_minmax.py
# Min-Max正規化の例
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# サンプルデータ(一つの系列のデータ)
data = np.array([1000, 2000, 3000, 4000, 5000])
# Min-Maxスケーラーを初期化
scaler = MinMaxScaler(feature_range=(0, 1))
# データを正規化
# reshape関数の引数を(-1,n)のように設定した場合配列の形状が
# 自動的に計算されます。元の配列をn列に変更し、行数は自動的に計算
# されます。よく使われる用例です。
normalized_data = scaler.fit_transform(data.reshape(-1, 1))
# 正規化されたデータを元のスケールに逆変換(必要な場合)
original_data = scaler.inverse_transform(normalized_data)
print("正規化前のデータ:", data)
print("Min-Max正規化後のデータ:", normalized_data)
print("逆変換後のデータ:", original_data)
ロバストスケーリング
Min-Max正規化は少数の極端な数値によって変換後のデータの特徴が変わってしまうため注意が必要です。特異なデータ(外れ値)がある場合には除外するか、外れ値があったとしてもデータの特徴を大きく損なわない正規化を利用する方法もあります。 scikit-learnのRobustScalerクラスはそのようなツールの例です。以下のコードはパーセンタイルの概念を利用しています。(参考:補足 分位数)
# tsa_norm_robust.py
# scikit-learnのRobustScalerクラスを使う例
#
import numpy as np
from sklearn.preprocessing import RobustScaler
# サンプルデータ(外れ値を含む時系列データ)
data = np.array([1, 2, 3, 4, 5,6,7, 100])
# RobustScalerのインスタンスを作成
# with_centering: Trueがデフォルトで、中央値がゼロになるようにセンタリングする
# with_scaling:Trueがデフォルトで、quantile_rangeによるスケーリングを有効にする
# quantile_range: ここで指定された幅を単位としてデータをスケーリングする
# 既定値の幅はIQR(Interquartile range,四分位範囲)すなわち25%->75%区間幅となる
scaler = RobustScaler(
with_centering=True,
with_scaling=True,
quantile_range=(25.0, 75.0)
)
# Robust Scalingを適用
scaled_data = scaler.fit_transform(data.reshape(-1, 1))
# 各パーセントタイルを求める
q1 = np.percentile(data, 25)
q2 = np.percentile(data, 50)
q3 = np.percentile(data, 60)
# 結果を表示
print("第1四分位数= %f" % q1)
print("第2四分位数= %f" % q2)
print("第3四分位数= %f" % q3)
print("IQR= %f" %( q3-q1))
print(scaled_data)
実行すると、以下のようにスケーリングされます。

Zスコア正規化 (標準化)
データの位置を平均値からのずれとして、データのスケールを標準偏差の倍率として理解できる形に変換します。
正規化後の値 = (値 - 平均) / 標準偏差
この方法は,平均が外れ値に対して敏感である一方、分布の形状を維持します。使用する時系列データを全部この変換をかけることで各系列データを同一スケール(平均値0、標準偏差1)で扱うことができるメリットがあります。 以下はzスコア正規化の単純な例。numpy、scipy二種類で書いている。
# tsa_norm_zscore.py
# Zスコア正規化の例
import numpy as np
from scipy import stats
# サンプルデータ(一つの系列のデータ)
data = np.array([1000, 2000, 3000, 4000, 5000])
# numpyを使ってZスコア正規化を適用
mean = data.mean()
std_dev = data.std()
standardized_data = (data - mean) / std_dev
print("正規化前のデータ:", data)
print("numpyでZスコア正規化後のデータ:", standardized_data)
# scipyを使ってZスコア正規化を適用
zscore_normalized_data = stats.zscore(data)
print("正規化前のデータ:", data)
print("scipyでZスコア正規化後のデータ:", zscore_normalized_data)
その他の変換
以下の変換方法もポピュラーですが、ここでは説明を省略します。
-
ログ変換
データの変動幅が大きい場合や、非線形な関係を持つ場合、対数変換が有用です。対数変換により、データの分布が正規分布に近づくことがあります。 -
データ差分
時系列データの差分を計算することで、トレンドや季節性を取り除きます。これにより、データが定常性を持つようになり、モデルの予測が向上することがあります。 -
パーセント変化
データのパーセント変化を計算することで、相対的な変化を捉えることができます。金融データの分析ではよく使用されます。
2. 自己回帰モデルによる分析#
弱定常性と強定常性
一般に確率変数の列からなる時系列 が以下の性質をもつとき「弱定常的(Stationary)」であるといいます。
- 期待値 が定数である
- 分散 が定数である
- 自己共分散 がラグ h にだけ依存する
一方、時系列 が「強定常(strictly stationary)であるとは次のように同時分布が時間によらないことをいいます。
強定常性を持つ過程は、期待値、分散、共分散が有限であるならば常に弱定常性を持ちます。これは、強定常性の定義が、二次までのモーメント(平均、分散、共分散)に関する弱定常性の条件を満たしていることから明らかです。
一方、弱定常性を持つ過程が必ずしも強定常性を持つわけではありません。時系列の二次までのモーメントが時間に依存しないが三次以上のモーメントが時間に依存する場合、弱定常性は満たされても強定常性は満たされないからです。
本書では特に断らない限り定常性とは弱定常性を意味します。 定常ではない時系列のことを「非定常(Non-stationary)」であるといいます。
定常時系列の例 「ホワイトノイズ」
平均値がゼロで分散が定数 、自己共分散 がラグ 1 以上ですべてゼロである定常時系列をホワイトノイズといいます。特に が正規分布に従う場合、正規性ホワイトノイズといいます。正規性ホワイトノイズは定義に照らし合わせてみると強定常過程の例にもなっています。
以降、期待値、分散、共分散をしばしば 、、 と略記します。 は自己相関係数(Autocorrelation)と呼ばれ分析では頻出する量なので以後表記を と決めておきます。
定常性がなぜ重要なのか?
統計分析の手法では標本として得られる観測データの数が多いほど推定の精度は向上します。しかしながら実社会の人間活動から生成される観測データは非常に少ないのがむしろ通常です。定常過程を扱う大きなメリットは、主要な母数である平均、分散、共分散が単時点に依存しないと仮定することにより、推定の入力となるデータを時間方向に増やすことができることです。そして実際にその仮定で作られた予測モデルはうまく機能します。
定常的過程 の平均、分散、共分散それぞれの推定値 として以下のように定義します。これらはいずれも母数の一致推定量となっています(証明は補足 確率・統計)
2.1. 自己回帰型モデル#
自己回帰型モデル(Autoregressive model, AR model)は、現在のデータが過去のデータの線形関数としてあらわされる時系列です。モデルの一般形は次のように表されます。
ここで、
は時点 における観測値
は定数項
はモデルの係数
はホワイトノイズ
自己回帰モデルは時系列データの自己相関を利用して未来の値を予測します。過去の値が現在の値に影響を与える傾向があるデータセットに対して、ARモデルは非常に効果的です。このことは金融、経済、気象予測、信号処理など、さまざまな実世界の時系列データに適用されている実績から伺うことができます。
パラメータ推定が容易
Yule-Walker方程式や最小二乗法など、パラメータを推定するための確立された方法があります。これにより、データに適合するモデルを簡単に構築できます。
拡張が容易
ARモデルは、自己回帰移動平均(ARMA)モデルや自己回帰和分移動平均(ARIMA)モデルなど、より複雑なモデルへの拡張が容易です。これにより、非定常な時系列データやノイズを含むデータに対しても効果的に対応できます。
実装例
以下に、PythonでARモデルを用いた時系列データの予測の簡単な例を示します。
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 仮の時系列データを生成
np.random.seed(42)
n = 100
data = np.cumsum(np.random.randn(n)) # ランダムウォークデータ
time_series = pd.Series(data)
# ARモデルの適用
model = sm.tsa.AR(time_series)
results = model.fit(maxlag=3)
print("ARモデルの係数:", results.params)
# 予測
forecast = results.predict(start=len(time_series), end=len(time_series)+10)
plt.figure(figsize=(10, 6))
plt.plot(time_series, label='Observed')
plt.plot(forecast, label='Forecast', color='red')
plt.title('AR Model Forecast')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
例。AR(1)モデル
最もシンプルなモデル p=1、つまりAR(1)の場合。
AR(1)の定常性条件#
AR(1)モデルの挙動(定常性/非定常性)は の絶対値が 1 よりも大きいか、小さいかによって大きく異なることを示します。
の場合
(10)式を漸化式とみて時点 0 まで展開すると以下のようになります。
期待値を計算すると であることから、
時間 が大きくなると、c の値に関わらず が無限大に発散するため、左辺の期待値も発散します。従って AR(1) は定常性の条件を満たさないことがわかります。
ちなみに分散を計算すると、以下の式が得られ、やはり時間とともに発散していきます。
の場合
今度は(10)式を ラグ まで展開します。
大きな k を考えると2番目の項はゼロに近づくため無視できます。
両辺の期待値をとるとホワイトノイズ部分はゼロになるので
kが無限大の極限で、右辺に等比級数の公式を適用することで以下の結果を得ます。
分散については(15)式,(16)式から k が無限大の極限で、
以上の結果をまとめると、
共分散については
は i=l+h の部分以外はゼロとなることを考慮すると、
これについても k→∞ としたとき の大きさにより結果は変わります
以上の結果をまとめましょう。
-
自己回帰係数 が ならば時系列 は定常的、逆に が定常的ならば 時系列過程は平均に収束し、安定であることを示す。
-
自己回帰係数 が ならば時系列 は非定常的。逆に が非定常的ならば
時系列は発散する。 -
自己回帰係数 が の時、時系列 は非定常的であるが階差 は定常的である
時系列は発散する。しかしながら階差の時系列は定常的である。
AR(p)の定常性条件#
一般のp次のモデル AR(p) の挙動(定常性/非定常性)についても同様の性質を示すことができます。詳細は参考6(「経済の時系列分析」 山本拓(著))等の教科書を参照いただくとして、ここでは結論だけをまとめておきます。
説明の見通しをよくするために、AR(p)モデルを次のように表現してみましょう。
ここで はラグ演算子(Lag operator)、あるいはバックシフト演算子といい、次のように定義します。
つまり、ラグ演算子 とは時点 のデータ を1期前のデータ に変換する演算子です。これを一般化して、ラグ演算子 を 回適用することを次のように定義します。
さらに、ラグ多項式 を導入するとモデルは以下のように書き表されます。
このラグ多項式 を 0 とおいた方程式のことを特性方程式(Characteristic equation)と呼びます。
このとき次の事実が知られています。
AR(p)が定常性をもつための必要十分条件は特性方程式の p 個の根が全て絶対値1よりも大きくなることである
この言明を係数 の式で表現することはAR(1)の時と違って、シンプルな形にはなりません。例えばAR(2)では以下のようになります。
Yule-Walker方程式#
AR(p)が定常である場合の、期待値、分散、共分散についてまとめておきます。
期待値 は時間によらず一定となるので(9)式の両辺の期待値をとることで簡単に求めることができます。
次に、(9)式から(29)式を引いた等式をつくり、さらに両辺に をかけて期待値をとることで共分散に関する等式を得ます。
ここで、 は と無相関なので、は h=0 のとき、 、それ以外の h ではゼロとなります。これを表すために、クロネッカーのデルタ記号()を用いました。
(32)式のの部分の連立一次方程式、あるいはそれを で除して自己相関係数 に関する方程式の形にしたものをユール・ウォーカー方程式(Yule-Walker equation)と呼びます。
上記の方程式を に対してまとめて行列形式にすると、次のようになります。




行列形式では次のように書けます。
ここで、
は自己相関係数行列。
は自己回帰係数のベクトル。
は自己相関係数のベクトルです。
ユール・ウォーカー方程式を使うことで、自己回帰モデルのパラメータ を推定することができます。数値計算用ソフトウェアの numpy には連立方程式を解くための関数が用意されていますので、これを活用して簡単な AR(2) モデルのパラメータ推定を行ってみましょう。 比較のために、statsmodels の AutoReg 関数を使って推定するコードも書いてあります。 推定結果の適合性を評価するために、残差の QQ-プロットとコレログラムをプロットします。また、定量的な評価基準として情報量基準( AIC と BIC )を計算しています。
# reg_check_ar1_yulewalker.py
# Yule-Walker方程式を解き推定したモデルの適合度を評価する
#
import japanize_matplotlib
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
from statsmodels.tsa.ar_model import AutoReg
# AR(3)モデルでサンプルデータを生成()
np.random.seed(0)
n = 100
phi_true = [0.75, -0.25, 0.1]
X = np.zeros(n)
eps = np.random.normal(size=n)
for t in range(3, n):
X[t] = phi_true[0] * X[t-1] + phi_true[1] * X[t-2] + + phi_true[1] * X[t-3] + eps[t]
#time = np.arange(n)
#X = 0.2 * np.random.randn(n) + np.sin(2 * np.pi * time / 12)
# AR(2)モデルを使って推定する
# 1. ユール・ウォーカー方程式をnumpy のsolve関数を使って推定する
# 2. statsmodels のARモデルfit関数を使って推定する
# 1. solve 関数を使う
#
# 自己共分散の計算
def autocovariance(series, lag):
n = len(series)
mean = np.mean(series)
return np.sum((series[:n-lag] - mean) * (series[lag:] - mean)) / n
# ユール・ウォーカー方程式を解く
gamma = np.array([autocovariance(X, lag) for lag in range(3)])
R = np.array([
[gamma[0], gamma[1]],
[gamma[1], gamma[0]]]
)
r = np.array([gamma[1], gamma[2]])
phi_est = np.linalg.solve(R, r)
print("推定されたパラメータ:", phi_est)
predicted_values = phi_est[0] * X[1:-1] + phi_est[1] * X[:-2]
# 2. statsmodels AutoReg による推定
#
#model = AutoReg(X, lags=2).fit()
#phi_est = model.params
#print("推定されたパラメータ:", phi_est)
#predicted_values = model.predict(start=2)
# 残差の計算
residuals = X[2:] - predicted_values
# QQプロットと残差の自己相関(ACF)のプロット
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes[0,0].plot(X, label='オリジナル')
axes[0,0].plot(range(2, n), predicted_values, label='AR(2)モデル推定', color='red')
axes[0,0].set_title('オリジナルと推定の比較')
axes[0,0].set_xlabel('時点')
axes[0,0].set_ylabel('予測値')
axes[0,0].legend()
sm.qqplot(residuals, line='s', ax=axes[1,0])
axes[1,0].set_title('QQプロット')
axes[1, 0].set_xlabel('理論分位数')
axes[1, 0].set_ylabel('標本分位数')
sm.graphics.tsa.plot_acf(residuals, lags=20, ax=axes[1,1])
axes[1,1].set_title('残差の自己相関(ACF)')
axes[1,1].set_xlabel('ラグ数')
plt.tight_layout()
plt.show()
# AICおよびBICの計算
n = len(residuals)
k = len(phi_est) # パラメータ数
sigma2 = np.var(residuals, ddof=k) # 残差の分散
log_likelihood = -n / 2 * (np.log(2 * np.pi) + np.log(sigma2) + 1)
AIC = -2 * log_likelihood + 2 * k
BIC = -2 * log_likelihood + np.log(n) * k
print("AIC:", AIC)
print("BIC:", BIC)
結果として表示されるAIC、BICの数値は、なにか他の推定方法を行って数値の大小を比較することで推定の良し悪しを判断する相対的な数値指標として利用できます。数字が小さい推定モデルを良しとします。
2.2. 単位根と共和分性#
毎日の株価の変動量(=終値の前日差異)はホワイトノイズ の性質を持っていると仮定します。そうすると株価の時間的推移を以下のように定義することができます。もちろん、他の定義の仕方も可能ですが、ここでは作業仮説としてそう考えることにします。
これは一般にランダムウォークと呼ばれる確率過程のひとつのパターンになっており、前記 p 次自己回帰モデル AR(p) で次数 p を 1 とし切片 μ をゼロ、自己回帰係数 を 1 とおいたものに他なりません。
AR(p) モデルの定常性・非定常性は特性方程式の解と密接に関係していることが知られています。
特性方程式の解(根とも呼ぶ)に1が含まれる場合、時系列は「単位根(Unit root)」を持つといいます。
以降、話を次数 p=1の AR(1) に限定します。このときの特性方程式はシンプルです。
従って AR(1) では自己回帰係数 が 1 であることと単位根を持つことは同義です。
冒頭言及したランダムウォークする株価時系列を考えましょう。これは単位根を持つ過程の例になっています。そして漸化式 (36) から分散は であり時間的に発散するため非定常的です。しかしながら階差を見るとはホワイトノイズであり定常的であることがわかります。
階差 が定常的過程になっている場合これを「和分過程(Integrated process)」とよびます。一般的には から d 回の階差をとった時系列が定常的であるとき は d 次の和分過程であるいい、 と表記します。ランダムウォークは です。
株価は単位根過程か?#
非定常過程が単位根を持つかどうかを判定するための必要十分条件は存在します。「Dickey-Fuller検定」あるいはそれを拡張した「Augmented Dickey-Fuller検定(ADF検定)」と呼ばれる統計的検定が、非定常過程が単位根を持つかどうかを評価する手法としてポピュラーです。Dickey-Fuller検定は、帰無仮説(非定常性がある)と対立仮説(非定常性がない、すなわち単位根が存在しない)を検証します。以下にDickey-Fuller検定の基本的な考え方を示します。
Dickey-Fuller検定の帰無仮説と対立仮説:
定数項、トレンド項をもたないAR(1) モデル に対して、検定統計量として以下を定義します。回帰係数の推定値を、の標準誤差を、指定した有意水準に対する臨界値を c としたとき
帰無仮説(H0): 時系列データに単位根(非定常性)が存在する。
対立仮説(H1): 時系列データに単位根(非定常性)が存在しない。
Dickey-Fuller検定は、帰無仮説のもとで統計的な検定統計量を計算し、その値が臨界値を下回るかどうかを確認します。帰無仮説が棄却される(検定統計量が臨界値を超える)場合、対立仮説が受容され、時系列データに単位根が存在しないことが示される。つまり、データは定常過程であると判定します。
以下のコードは定常過程と非定常過程のダミーデータをつくり、プロットするプログラムです。
# tsa_plot_dickey_fuller.py
# Dickey-Fuller検定
#
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import adfuller
import matplotlib.pyplot as plt
import japanize_matplotlib
# ホワイトノイズの生成(定常過程)
np.random.seed(0)
n = 100
white_noise = np.random.normal(0, 1, n)
# AR(1)モデルの生成(定常過程)
phi = 0.5 # 自己回帰係数
ar_data_1 = np.empty(n)
ar_data_1[0] = white_noise[0]
for t in range(1, n):
ar_data_1[t] = phi * ar_data_1[t-1] + white_noise[t]
# AR(1)モデルの生成(非定常過程)
phi = 0.95 # 自己回帰係数
ar_data_2 = np.empty(n)
ar_data_2[0] = white_noise[0]
for t in range(1, n):
ar_data_2[t] = phi * ar_data_2[t-1] + white_noise[t]
# プロット
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(ar_data_1, label='AR(1)モデル (φ={phi})')
plt.title('AR(1)モデル (自己回帰係数0.5)')
plt.grid()
plt.subplot(2, 1, 2)
plt.plot(ar_data_2, label=f'AR(1)モデル (φ={phi})')
plt.title('AR(1)モデル (自己回帰係数0.95)')
plt.grid()
plt.tight_layout()
plt.show()
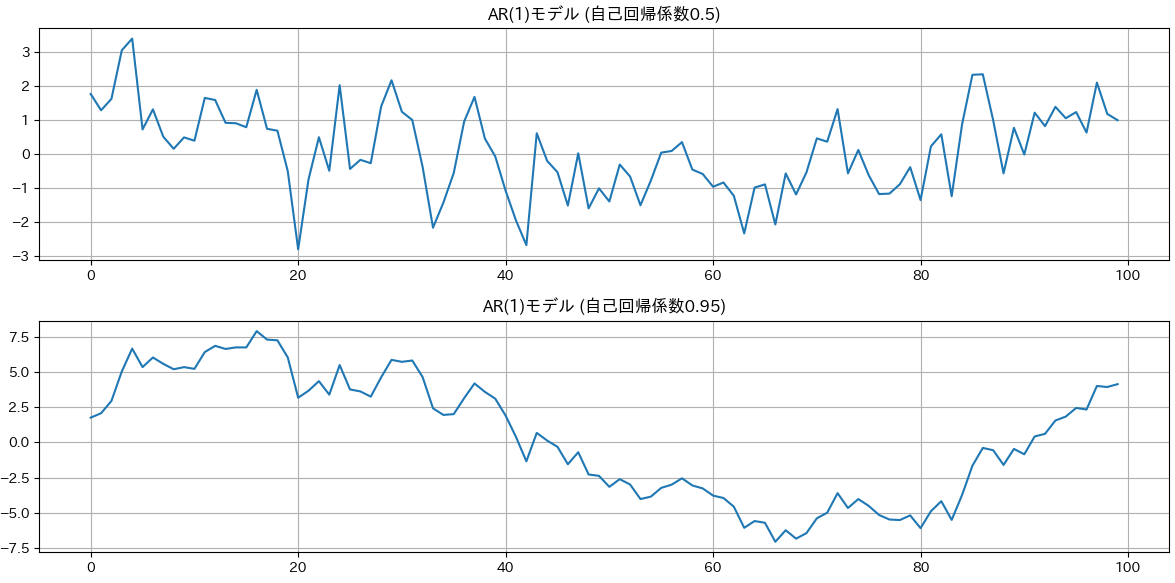
上記のダミーデータに対してDickey-Fuller検定を実行してみましょう。
# tsa_test_dickey_fuller.py
# Dickey-Fuller検定
#
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import adfuller
def test_dickey_fuller(phi):
np.random.seed(0)
n = 100
error = np.random.normal(0, 1, n)
y = np.empty(n)
y[0] = error[0]
for t in range(1, n):
y[t] = phi * y[t-1] + error[t]
# 時系列データをPandas Seriesに変換
time_series = pd.Series(y)
# Dickey-Fuller検定を実行
result = adfuller(time_series)
return result
#
# 時系列データの作成 (定常なAR(1)モデル)
#
phi = 0.5 # 自己回帰係数が1から遠い値
# 検定実行
result = test_dickey_fuller(phi)
print("#========定常なAR(1)モデル)==========================")
print("Dickey-Fuller検定統計量:{:.3f}".format (result[0]))
print("p値:{:.5f}".format (result[1]))
print("ラグ数:{:.3f}".format (result[2]))
print("観測数:{:.3f}".format (result[3]))
print("1%有意水準の臨界値:{:.3f}".format (result[4]["1%"]))
print("5%有意水準の臨界値:{:.3f}".format (result[4]["5%"]))
print("10%有意水準の臨界値:{:.3f}".format (result[4]["10%"]))
# 検定統計量と臨界値を比較
if result[0] <= result[4]["5%"]:
print("5%有意水準において帰無仮説は棄却される。単位根は存在しない(定常時系列)と判定されます。")
else:
print("5%有意水準において帰無仮説は棄却されない。単位根は存在する(非定常時系列)と判定されます。")
#
# 時系列データの作成 (非定常なAR(1)モデル)
#
phi = 0.95 # 自己回帰係数が1に近い値
# 検定実行
result = test_dickey_fuller(phi)
print(" ")
print("#========非定常なAR(1)モデル)==========================")
print("Dickey-Fuller検定統計量:{:.3f}".format (result[0]))
print("p値:{:.5f}".format (result[1]))
print("ラグ数:{:.3f}".format (result[2]))
print("観測数:{:.3f}".format (result[3]))
print("1%有意水準の臨界値:{:.3f}".format (result[4]["1%"]))
print("5%有意水準の臨界値:{:.3f}".format (result[4]["5%"]))
print("10%有意水準の臨界値:{:.3f}".format (result[4]["10%"]))
# 検定統計量と臨界値を比較
if result[0] <= result[4]["5%"]:
print("5%有意水準において帰無仮説は棄却される。単位根は存在しない(定常時系列)と判定されます。")
else:
print("5%有意水準において帰無仮説は棄却されない。単位根は存在する(非定常時系列)と判定されます。")
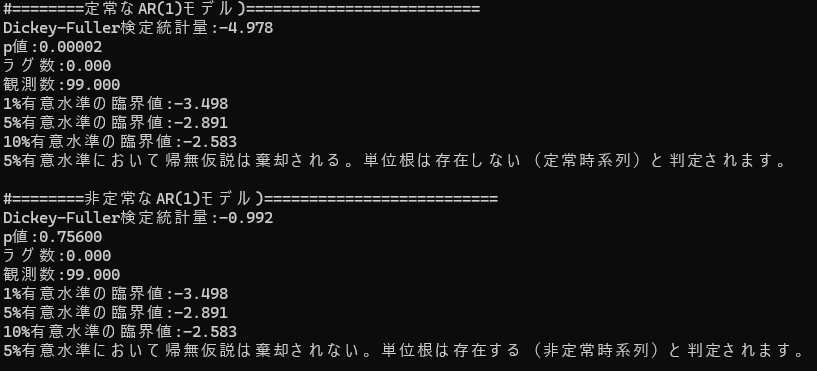
スクリーンダンプに表示されるように、ダミーの定常過程では帰無仮説は棄却されることが確認できました。同じくダミーの非定常過程では帰無仮説は棄却されないことが確認できました。
次に実際の株価データを用いて Dickey-Fuller 検定を実行してみます。あらかじめ対象とする株価データをダウンロードしプログラムと同じディレクトリへ配置しておきます。第1章1節2項で記載したプログラムを使ってダウンロードすることもできます。
# tsa_test_dickey_fuller2.py
# 株価データに対するAugmented Dickey-Fuller検定
#
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import adfuller
import matplotlib.pyplot as plt
import japanize_matplotlib
def test_dickey_fuller(time_series):
# Augmented Dickey-Fuller検定を実行
result = adfuller(time_series)
return result
# CSVを読み込みデータフレームを返す
df = pd.read_csv('1301.T-2023-1d.csv')
# 'Date'列をdatetime64型に変換する
df['Date'] = pd.to_datetime(df['Date'])
# 'Date'列をindexに設定する
df.set_index('Date', inplace=True)
# プロット
plt.figure(figsize=(10, 4))
plt.subplot(1, 1, 1)
plt.plot(df.index, df['Close'])
plt.title('極洋(1301) 終値')
plt.grid()
plt.tight_layout()
plt.show()
#
# 株価データの検定
#
# 検定実行
result = test_dickey_fuller(df["Close"])
print(" ")
print("#========Augmented Dickey-Fuller検定結果==========================")
print("検定統計量:{:.3f}".format (result[0]))
print("p値:{:.5f}".format (result[1]))
print("ラグ数:{:.3f}".format (result[2]))
print("観測数:{:.3f}".format (result[3]))
print("1%有意水準の臨界値:{:.3f}".format (result[4]["1%"]))
print("5%有意水準の臨界値:{:.3f}".format (result[4]["5%"]))
print("10%有意水準の臨界値:{:.3f}".format (result[4]["10%"]))
if result[0] <= result[4]["5%"]:
print("5%有意水準において帰無仮説は棄却される。単位根は存在しない(定常時系列)と判定されます。")
else:
print("5%有意水準において帰無仮説は棄却されない。単位根は存在する(非定常時系列)と判定されます。")
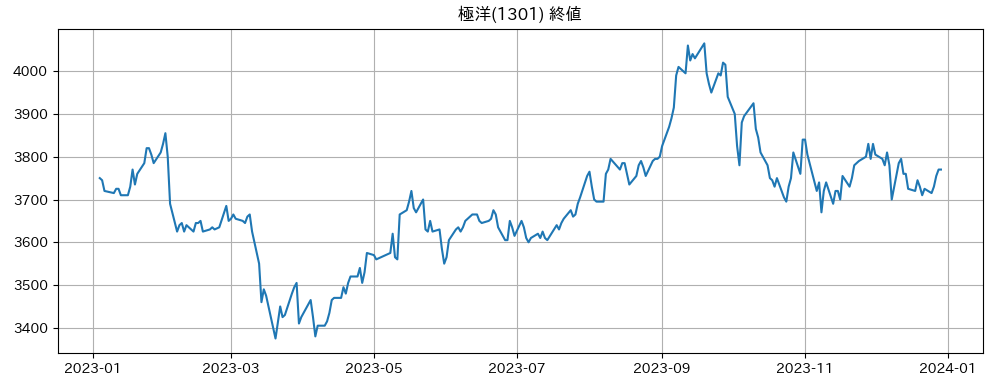

極洋の株価推移は単位根過程であると判定できます。
ただし、全ての株価が単位根過程と判定されるわけではありません。東証上場銘柄の2023年株価データ(一般に売買できる個別株3809件)をチェックしてみました。stasmodelsでは上記のADF検定のほか、Kwiatkowski-Phillips-Schmidt-Shin(KPSS)検定という手法を試すことができます。
二つの検定方法でチェックしたところ以下の結果でした。
| 単位根の有無 | ADF検定(3809銘柄) | KPSS検定(3809銘柄) |
|---|---|---|
| 単位根は存在しないと判定された銘柄数 | 335 | 475 |
| 単位根は存在すると判定された銘柄数 | 3474 | 3334 |
参考まで、二つの検定の双方で単位根無し判定された銘柄の数は160銘柄前後あります。
共和分性、VECM#
1970年代後半から1980年代にかけて、多くの実際の経済データ(GDP、インフレ率、為替レート、株価など)は非定常(トレンドやランダムウォークを持つ)であることが明らかになり、単位根過程の概念が広く認識されるようになりました。
これと並行して、非定常時系列においては、特に経済指標などの時系列が単位根を持つ場合、誤った回帰結果が得られる「みせかけの回帰」の問題が指摘されるようになりました。定常過程を想定した自己回帰モデル(AR)や移動平均モデル(MA)では正しい結果が得られない場合があるのです。
みせかけの回帰
「見せかけの回帰(spurious regression)」は、因果関係がない変数間であっても、単に同じトレンドを
持つことで高い回帰係数や統計的な有意性が示される結果、誤って因果関係が存在するかのように見える現象
を指します。
歴史的には見せかけの回帰は、1980年代にクライヴ・グレンジャーらによって広く認識されるようになりました。
時系列データ間の関係を評価するために、非定常な時系列データ同士を回帰分析した場合、無関係なデータ間
にも高い相関が現れることが指摘されました。グレンジャーとニューボルドは、単位根過程を持つ非定常データ
の回帰分析が誤った有意性を生み出すことを実証しました。
例えば、株価指数と為替レート、GDPと金利、物価と給与水準など回帰分析を行ってみると有意な因果関係が
あるかのような結果が容易に出てきます。
この局面を大きく変えたのが、1980年代に、共和分(Cointegration)の概念を提唱したロバート・エングル(Robert F. Engle)とクライヴ・グレンジャー(Clive W. J. Granger)です。共和分性の概念により、個々には非定常な時系列でも、複数の時系列間に長期的な均衡関係が存在する場合、それらの時系列の線形結合が定常過程になることがを示されました。
例えば、複数の経済変数が個別にはトレンドや単位根を持つものの、これらの変数が長期的には一定の関係を保つ場合、この関係が共和分ベクトルによって表現されます。共和分関係を分析することで、短期的な変動と長期的な均衡を分けて捉えることが可能となります。また、エングルとグレンジャーは単位根時系列が共和分しているかどうかを検定する手法(エングル-グレンジャー検定)を開発しました。グレンジャーは、その画期的な解析方法の研究により2003年にノーベル経済学賞を受賞しています。
二つの非定常時系列の間に共和分性を見出すことができたならば、それらは見せかけではなく、何らかの実体的な影響関係を持っている可能性が強い、ということです。
定義
二つの に従う時系列 と があったとき、その線形結合 が になる、言い換えると定常過程になるとき と は「共和分(cointegration)」の関係にあるといいます。
Engle-Granger 検定
Engle-Granger 検定は、2 変量に限定していますが容易に使うことができる共和分の検定手法です。
この検定では、二つの単位根過程 と の線形結合(例えば )により定常過程(I(0))をつくることができることをDickey-Fuller 検定により調べます。
Engle-Granger 検定は以下の帰無仮説を検証します。
- 帰無仮説 (H₀): と の間に共和分関係が存在しない。
- 対立仮説 (H₁): と の間に共和分関係が存在する。
検定の結果、p 値が通常の有意水準(例えば 5 %)以下であれば、帰無仮説を棄却し、共和分関係があると判断します。逆に、p 値が有意水準より大きければ、帰無仮説を棄却できず、共和分関係はないと判断します。
誤差修正モデル(ECM)
誤差修正モデル(ECM)は、時系列の間の長期的な関係をモデル化しつつ、短期的な調整も含めた動態を考えるのに適した手法です。以下に政策金利と為替レートを例にしてこれらの関係を誤差修正モデルによりモデル化する考え方を説明します。
正しいかどうかはいったんさておき、政策金利(例:)と為替レート(例:)の長期的な均衡関係があるとします。そこでそれらの時系列は単位根を持つ非定常過程であり、共和分関係を持つと考えてみます。
ここで、 は残差であり、もし と の間に共和分関係が存在すれば、 は定常になります。この関係は為替レートと政策金利とが長期的には均衡関係を有することを意味します。
誤差修正モデルでは、説明対象の変数の変動は、長期均衡関係の強さと短期的な変動の合成として表すことができると考えます。
は為替レートの変動です。 は長期均衡からの乖離を示し、これを「誤差修正項」と呼びます。 を調整係数とよび、誤差修正項の影響の大きさを決定します。 は政策金利の短期的な変化が為替レートに与える影響を示します。 はランダムな誤差項でありホワイトノイズであると仮定します。
このようにモデル化することでいくつかの解釈ができるようになります。
-
が負であれば、変動量 は 乖離 と逆符号になるので、乖離が正負どちらであっても、乖離の大きさが減少する方向に推移します。つまり、政策金利あるいは為替レートが何らかの理由で短期的に大きく変動した結果、乖離が拡大したとしても、その乖離は長期的には均衡点( )へ向かって縮小していくと予想できるわけです。
-
の大きさは長期均衡に戻ろうとする速度を示すと考えられるので、金融政策の影響が市場にどれだけ速く反映されるかを示唆するでしょう。
-
は、政策金利と為替レートの「長期均衡係数」と呼ぶべき係数であり、政策金利と為替レートが長期的にどのような関係を持っているかを表します。つまり、 の場合、政策金利が1%上昇すると、為替レートが1.5単位上昇する長期的な関係があると解釈されます
-
は、政策金利の変化は為替レートをただちに変動させる短期変動項であることを意味します。
短期変動を過去ラグ次数 p まで考慮する一般化をすると以下の定義を得ます。
ベクトル誤差修正モデル(VECM)
ECMは通常、2 つの時系列間の影響関係をモデル化しますが、経済や金融のデータは多くの場合、複数の変数相互の影響を考慮する必要があります。そのためベクトル値自己回帰モデル(Vector Autoregressive Model,VAR)の枠組みを使い、ECMの概念を複数の変数に拡張したものがベクトル誤差修正モデル(VECM)です。
VECMの基本的なモデル形式は次のように表されます。
: 各時点 における 個の時系列変数を格納する 列ベクトル
: 各時系列の1階差分を格納する 列ベクトル
: 共和分関係を表す 行列。長期的な均衡関係の情報を持っています。調整速度係数 および共和分ベクトル を使って と分解されます。
: 前期の時系列変数の値を表す 列ベクトル
: 短期的な調整効果を表す 行列。ラグごとに存在し、合計で 個の行列があります。
: 各時点でのランダム変動を格納する 列ベクトル 。
複数の経済変数(GDP、消費、投資、インフレ率、為替レートなど)間には長期的な均衡関係(=共和分性)が存在する場合がありますので、VECMはこれらの変数間の動きと均衡関係を同時に分析するのに有効です。 そして、共和分性を示す時系列の変動は実際にVECMのモデル式で記述できることがグレンジャーの表現定理として知られています。
グレンジャーの表現定理
グレンジャーの表現定理は次を主張します。
「 ベクトル値時系列 が 一階の和分過程 であり、 が共和分の関係にあるならば、VECM形式で表現できる。」
この定理は、共和分関係を有する単位根時系列が存在する場合、これらの時系列は誤差修正モデルにより表現できることを主張します。すると、二つ以上の単位根時系列が共和分しているならば、各変数の変動は、長期的な均衡関係と、長期的な均衡からの乖離(誤差)を調整しようとする短期変動から構成されることがこのモデル定義式によってわかります。
金融・経済領域ではお互いに影響を及ぼしている考えられる事象がしばしば見受けられます。表現定理はそのようなデータの分析に対する理論的な裏付けを与えてくれます。
- マクロ経済データ
GDP、インフレ率、金利など、長期的には関連性があるが、短期的には異なる動きをするデータ。 - 金融市場のデータ
株価、為替レート、金利など、長期的な関係が存在する一方、短期的な調整があるデータ。
VECMに基づき、多変数の共和分性を検定する手法として良く使われるのが次のJohansen検定です。
Johansen 検定
通常、Johansen検定ではランク(共和分ベクトルの数、すなわち独立した長期的な均衡関係の数)を算出するために次のような帰無仮説を設定します。
- 帰無仮説: 共和分ランクが (例えば、共和分ベクトルが0本、1本など)である。
- 対立仮説: 共和分ランクが (例えば、共和分ベクトルが1本以上である)。
この k を時系列の数までひとつづつ上げて行くことで共和分ベクトルの存在数を求めます。
この作業のために、トレース検定と最大固有値検定という二つの検定手法を併用します。一般的な用法では、トレース検定によりランクを求めます。さらに特定の共和分ランクに対するより鋭敏なテストを行い共和分ベクトルの個数を絞り込むために最大固有値検定を補助的に用いることが有効とされているようです。
株価に見る共和分性
共和分性は、金融や経済領域の様々な場面で出現する、という記述を文献で見かけます。それが本当かどうかよくわかりませんが、簡単に確かめることができる事例としてここでは株価時系列における共和分の例を挙げてみます。 事例は第1章3節2項でとりあげた海運業種の商船三井と日本郵船です。以下のコードでは、この二銘柄の単位根検定を行った後で、Engle-granger共和分検定とJohansen検定により共和分性を確認します。この際にウィンドウ期間を約6か月に区切り、日付をスライドしていくことで各期間の共和分性有無をチェックします。コードの後半ではベクトル誤差修正モデルを構成して、学習済モデルを使い将来株価を予測しています。ただしそもそも株価自体は予測可能とは言えないので実利的な期待があっての事例ではありません。
(2026年6月追記) コードに一部分改善余地があったため新しいコードへ置き換えました。データについても2026年6まで取り込んでいます。コード実行結果の評価も併せて改訂しました。
# tsa_coint_2stocks_v2.py
# 海運業に銘柄の共和分性を検証する
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller, coint
from statsmodels.tsa.vector_ar.vecm import coint_johansen
from statsmodels.tsa.vector_ar.vecm import VECM
import japanize_matplotlib
from sklearn.preprocessing import MinMaxScaler
from numpy.linalg import LinAlgError
# データの読み込みとインデックスの明示的な頻度設定(日次ビジネスデー)
nyk = pd.read_csv('9101.T.csv', parse_dates=['Date'], index_col='Date')
mol = pd.read_csv('9104.T.csv', parse_dates=['Date'], index_col='Date')
# 終値のみを使用し、結合と欠損値処理
combined_data = pd.concat([nyk['Close'], mol['Close']], axis=1).dropna()
combined_data.columns = ['NYK', 'MOL']
# 時系列データの頻度を「ビジネスデー(B)」に設定(VECMの警告対策)
combined_data = combined_data.asfreq('B').ffill()
# 分割日を指定(※2026年想定。データ期間に応じて調整してください)
split_date = '2026-01-01'
train_data = combined_data[:split_date]
test_data = combined_data[split_date:]
# --- 1. 単位根検定(ADF検定)※生データで実施 ---
adf_nyk = adfuller(train_data['NYK'])
adf_mol = adfuller(train_data['MOL'])
print(f"日本郵船 ADF 検定統計量: {adf_nyk[0]:.4f}, p-値: {adf_nyk[1]:.4f} -> {'単位根あり(非定常)' if adf_nyk[1] > 0.05 else '単位根なし(定常)'}")
print(f"商船三井 ADF 検定統計量: {adf_mol[0]:.4f}, p-値: {adf_mol[1]:.4f} -> {'単位根あり(非定常)' if adf_mol[1] > 0.05 else '単位根なし(定常)'}")
print("-" * 60)
# --- 2. ローリング(ウィンドウ)共和分検定 ---
window_size = 6 # 6か月
step = 1 # 1か月
window_len = window_size * 20
step_len = step * 20
count_coint_eg = 0
count_coint_jo = 0
window_results = []
# ループ境界の修正(末尾でデータ不足にならないようにする)
for i in range(0, len(train_data) - window_len + 1, step_len):
window_data = train_data.iloc[i:i + window_len]
nyk_window = window_data['NYK']
mol_window = window_data['MOL']
# Engle-Granger検定
coint_t, p_value, crit_value = coint(nyk_window, mol_window)
eg_exists = p_value < 0.05
if eg_exists:
count_coint_eg += 1
# Johansen共和分検定
try:
johansen_test_result = coint_johansen(window_data, det_order=0, k_ar_diff=1)
# トレース統計量と5%臨界値の取得(インデックスの修正)
trace_stat = johansen_test_result.lr1[0]
crit_val = johansen_test_result.cvt[0, 1]
jo_exists = trace_stat > crit_val
if jo_exists:
count_coint_jo += 1
except LinAlgError as e:
jo_exists = False
trace_stat, crit_val = np.nan, np.nan
print(f"エラー: {e} - ウィンドウ範囲: {window_data.index[0].strftime('%Y-%m')}")
window_results.append((window_data.index[0], window_data.index[-1], eg_exists, jo_exists))
# 結果の出力
print(f"期間 {window_data.index[0].strftime('%Y-%m')} - {window_data.index[-1].strftime('%Y-%m')}:")
print(f" E.G.検定: {'あり' if eg_exists else 'なし'} (p値: {p_value:.4f})")
print(f" Johansen: {'あり' if jo_exists else 'なし'} (統計量: {trace_stat:.2f}, 臨界値: {crit_val:.2f})")
print("-" * 60)
print(f"総ウィンドウ数: {len(window_results)}")
print(f"共和分検出回数 -> E.G.検定: {count_coint_eg}回, Johansen検定: {count_coint_jo}回")
print("-" * 60)
# --- 3. VECMモデルの適用と予測 ---
# 決定論的トレンド項(det='co':共和分空間内に定数項あり)を指定するのが実務的に一般的
vecm_model = VECM(train_data, k_ar_diff=1, coint_rank=1, deterministic='co')
vecm_result = vecm_model.fit()
# 予測値の取得(生データスケールで出力される)
forecast = vecm_result.predict(steps=len(test_data))
# --- 4. 共和分ベクトルを用いた正しいスプレッド(定常時系列)の計算 ---
# VECMから推定された共分散ベクトルの係数 beta (構造: [変数個数, 共和分ランク])
beta = vecm_result.beta[:, 0]
print(f"推定された共和分ベクトル係数 (NYK, MOL): {beta}")
# 全期間のスプレッドを計算: スプレッド = beta[0]*NYK + beta[1]*MOL
# 通常は一方の係数を1に正規化するため、NYKベースの乖離にする
spread = combined_data['NYK'] + (beta[1] / beta[0]) * combined_data['MOL']
# グラフ表示用にスプレッドを[-1, 1]に標準化
scaler_spread = MinMaxScaler(feature_range=(-1, 1))
stationary_series = scaler_spread.fit_transform(spread.values.reshape(-1, 1))
# --- 5. 可視化プロット ---
fig, axs = plt.subplots(2, 1, figsize=(12, 9), gridspec_kw={'height_ratios': [3, 1]})
# 上側のプロット(生価格での比較)
axs[0].plot(combined_data.index, combined_data['NYK'], label='日本郵船(実測)', color='blue')
axs[0].plot(combined_data.index, combined_data['MOL'], label='商船三井(実測)', color='green')
axs[0].plot(test_data.index, forecast[:, 0], label='日本郵船(予測)', color='blue', linestyle='--')
axs[0].plot(test_data.index, forecast[:, 1], label='商船三井(予測)', color='green', linestyle='--')
axs[0].set_title('海運業二銘柄の株価推移とVECM予測(生データ)')
axs[0].set_xlabel('日付')
axs[0].set_ylabel('株価(円)')
axs[0].legend()
axs[0].grid(True)
# 下側のプロット(推定された共和分ベクトルに基づくスプレッド)
axs[1].plot(combined_data.index, stationary_series, label='共和分関係から算出したスプレッド', color='red')
# 予測開始線(縦破線)の追加
axs[0].axvline(pd.Timestamp(split_date), color='gray', linestyle=':')
axs[1].axvline(pd.Timestamp(split_date), color='gray', linestyle=':')
axs[1].set_title('二銘柄の価格乖離度(定常時系列)')
axs[1].set_xlabel('日付')
axs[1].set_ylabel('乖離度 ([-1, 1] 正規化)')
axs[1].legend()
axs[1].grid(True)
# 表示期間の制御
start_plot_date = pd.Timestamp('2024-01-01')
end_plot_date = combined_data.index[-1]
axs[0].set_xlim(start_plot_date, end_plot_date)
axs[1].set_xlim(start_plot_date, end_plot_date)
plt.tight_layout()
plt.show()
チャートと検定結果は以下のようになります。
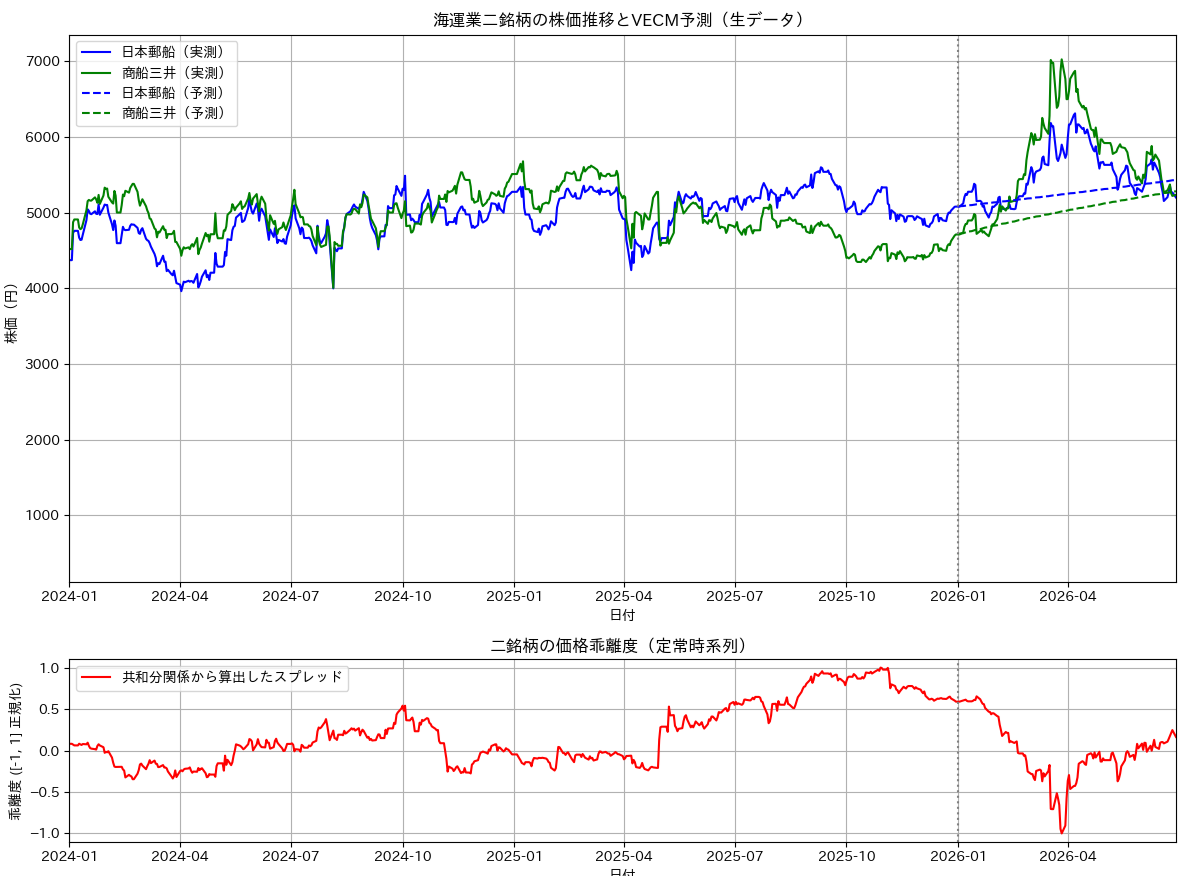
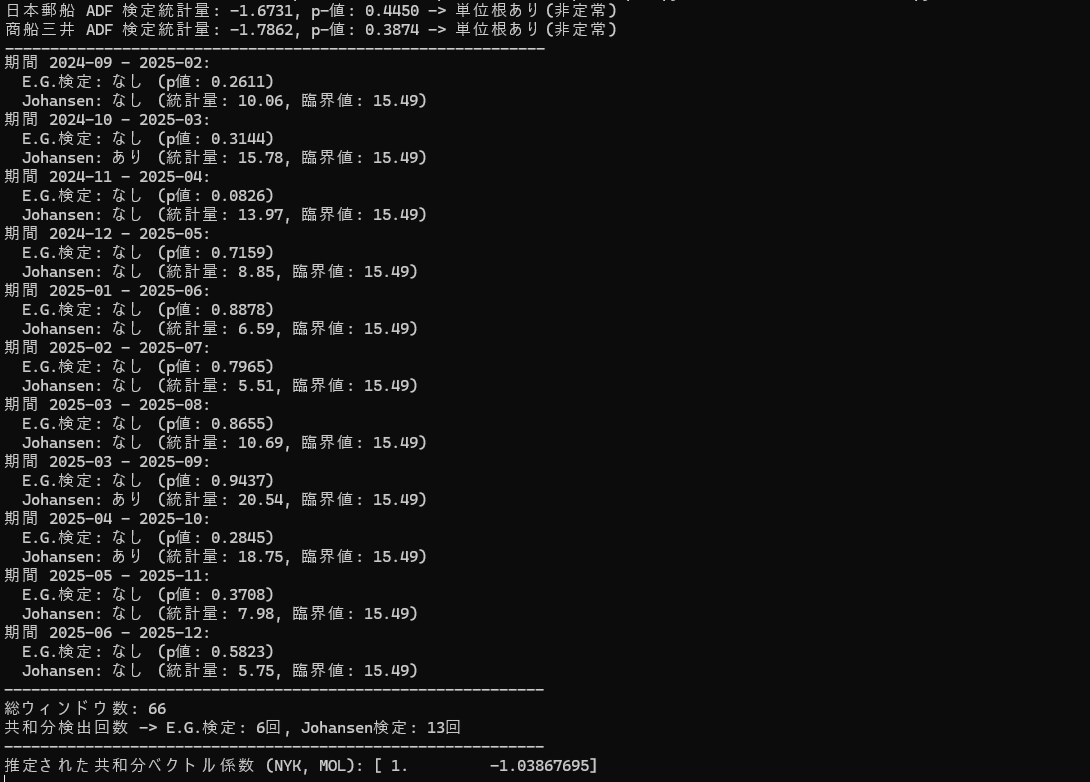
検定結果のコンソール画面から、日本郵船(NYK)と商船三井(MOL)のペアについて非常に重要な統計的特徴が読み取れます。 実務(ペアトレードや時系列分析)の観点から、この結果を3つのポイントで評価します。
1. 前提条件のクリア:両銘柄とも「一階和分 I(1)」プロセス#
検定結果最上部のADF検定(単位根検定)の結果を見ると、双方ともp値が 0.05 を大きく上回っています(郵船: 0.4450、商船三井: 0.3874)。
両銘柄の生価格はどちらも「単位根あり(非定常)」です。これは「株価そのものはランダムウォークしており、そのままでは回帰分析できない」ということを意味し、共和分検定を行うための大前提を完璧に満たしています。
2. 共和分関係の評価:長期的にはあるが、短期的には崩れやすい#
総ウィンドウ数66回(6か月ごとのローリング検定)のうち、共和分が検出された回数は以下の通りです。
- Engle-Granger(E.G.)検定: 6回 / 66ウィンドウ(約9%)
- Johansen検定: 13回 / 66ウィンドウ(約20%)
【統計的な解釈】
- Johansen検定の方が多く検出されている理由: Johansen検定は複数変数の同時決定システム(VAR)をベースにしているため、E.G.検定よりも一般に検出力が高い(共和分を見つけやすい)傾向があります。
- 全体的な評価(「弱い」または「動的な」共和分): 検出率が10%〜20%に留まっていることから、この2銘柄は「全期間を通じて常にガチガチの共和分関係(平均回帰性)にあるわけではない」と言えます。ある時期(例えば画像中の2024-10や2025-03〜04など)には強い連動性(Johansen検定で有意)が見られますが、それ以外の時期には一時的に関係性が外れてバラバラに動いています。
3. 推定された共和分ベクトルの評価#
検定結果最下部の 推定された共和分ベクトル係数 (NYK, MOL): [ 1. -1.03867695 ] は、銘柄の価格が似通っているだけにわかりやすい結果です。
- 解釈: これは以下の数式が定常(時系列として安定)になることを示しています。
下側のプロットでスプレッドが中央(0.0)から大きくプラスやマイナスに乖離したタイミング(共和分が一時的に破綻しているように見える瞬間)は、投資視点で見た場合、ペアトレーディングのチャンス(エントリー・シグナル)になります。なぜなら、長期的には「1: -1.038」の力学で元の鞘に戻る確率が高いからです。ペアトレーディングについては別章で詳しく解説します。
2.3. グレンジャー因果性#
過去現在の事象を観察し、そこに法則性を見出し未来を予測すること。これは自然科学にとどまらず時系列を扱う研究における普遍的な課題です。歴史的な経緯では、因果性の研究は共和分よりもさかのぼり、1969年のグレンジャーによる因果性の研究がエポックメイキングな成果でした。その研究のなかで、時系列の変数 が別の時系列 に対して将来の予測を改善するかどうかを判定する手法を提案しました。
グレンジャー因果性の概念が広まると、非定常な時系列間の長期的な均衡関係についても考慮する必要が出てきました。その中で、1980年代に、エングルとグレンジャーによって共和分の概念が導入され、同時に共和分関係を持つ時系列に関するグレンジャー表現定理(Granger Representation Theorem, GRT)が見出されました。
グレンジャー因果性
おおざっぱに言えば、二つの時系列 X , Y があったとして、「 X の過去が Y の予測に役立つ」場合、X と Y はグレンジャー因果性を有すると言います。この詳しい定義や用例は、例えば 参考6(「経済の時系列分析」 山本拓(著) 創文社 )等の教科書を参照いただくとして、ここでは少々簡略化して概念を説明したいと思います。
グレンジャー因果性は、予測平均二乗誤差(PMSE: Prediction Mean Squared Error)を評価指標としたとき、時系列データ が他の時系列データ の過去の情報を含むことによって予測精度を向上させる場合に成立します。具体的には、 の過去の値を の予測に加えることで PMSE が減少する場合、 が に対してグレンジャー因果性を持つとされます。
二つの時系列 と を考えます。グレンジャー因果性は、次の二つのモデルの予測力を比較することで定義されます。
- 制限モデル(モデル1): の過去の値のみを用いて を予測する。
- 拡張モデル(モデル2): の過去の値に加え、 の過去の値も用いて を予測する。
モデル1(制限モデル):
モデル2(拡張モデル):
ここで、 は定数項、 と はそれぞれ と の遅延項数、 は誤差項を表します。
グレンジャー因果性の評価手順
step1. 各モデルのPMSEの計算: 制限モデルのPMSE()と拡張モデルのPMSE()を計算します。
step2. PMSEの比較: もし となり、統計的に有意であれば(通常はF検定や尤度比検定で確認)、 が に対してグレンジャー因果性を持つと判断されます。
ただし、この因果性はあくまで予測可能性を主張するものであり、時系列を生む母体の活動が因果関係で結ばれていることを主張するものではないことに注意が必要です。
グレンジャー因果性検定
共和分検定は時系列間の長期的な均衡関係を探るのに対し、グレンジャー因果性検定は、一方の変数から他方の変数に対する予測可能性を評価します。これらの手法を併用することで時系列データ間の関係をより深く理解することができます。
グレンジャー因果性の検定では、遅延した過去のデータが他の変数の将来の値を予測するかを調べます。具体的には、ある変数の過去の値を含めた場合に予測精度が向上すれば「グレンジャー因果性がある」と判断します。
共和分検定は、共和分関係を探るために、データが単位根を持つ時系列を前提としますがグレンジャー因果性検定は、データが定常・非定常を問わずに適用可能であり、差分系列を使っても検定が可能です。 判定のアルゴリズムとして F 検定や Wald 検定などを用い、各変数の遅延項の有無を検定します。
グレンジャー因果性検定の帰無仮説
時系列 のモデルにおいて、時系列 は予測に役立たない。すなわち以下の命題 が成立する。
ここで、
はラグ数。
は次のように表される回帰モデルとする。 は誤差項。
帰無仮説 において、すべての がゼロである場合、過去の は に関する情報を提供しない、つまり、 が の予測に寄与しないと考えます。
この帰無仮説が棄却されたならば、 が の予測に有意な情報を提供している、すなわち は に対してグレンジャー因果性を持つ と結論付けます。以下に検証の流れを説明します。
step1. ラグ数を選択する
モデルに含めるラグ数 はAIC(赤池情報量基準)やBIC(ベイズ情報量基準)といった情報量基準を用いて決定します。適切なラグ数を選択することで、モデルの予測精度とパラメータの少なさをバランスさせます。
step2. 帰無仮説のモデル(制約付きモデル)を構築
の現在の値はそのラグ値 のみで予測されると仮定します。変数 X の過去の情報は Y の予測に一切寄与しないという「制約付き」、という意味合いで制約付きモデルと呼びます。
ここで は定数項、 は誤差項です。
step3. 対立モデル(制約なしモデル)を構築
の現在の値を に加え、 も含めて予測するモデルを構築します。Y の予測に X も利用する自由度の高さを評して「制約なし」モデルと呼びます。
step4. パラメータ推定
上記の二つのモデルを最小二乗法(OLS)により推定し、それぞれのモデルの残差の分散を計算します。 制約付きモデル(帰無モデル)と制約なしモデル(対立モデル)のそれぞれについて残差平方和 と を計算します。
step5. 統計量の計算
帰無仮説が正しい場合、制約付きモデルと制約なしモデルの残差平方和の差異が小さくなります。この差異を利用し、以下のように 統計量を計算します。
ここで はサンプル数、 はラグの数です。この 統計量に基づいて、帰無仮説を棄却するかどうかを決定します。
step6. 帰無仮説の検定と解釈
計算された 統計量と、その臨界値を比較します。もし 統計量が臨界値より大きければ、帰無仮説を棄却し、グレンジャー因果性が存在すると判断します。 直接 値と臨界値を比較する代わりに、 統計量に基づく 値を計算し、あらかじめ設定した有意水準(例えば5%)と比較して、因果関係の有無を検証することもできます。
2.4. 経済指標への適用#
グレンジャーの表現定理によって、ベクトル誤差修正モデルをベースとした時系列分析の理論的な基盤が確立されました。以下ではます。以下ではベクトル誤差修正モデルを活用する流れを整理し、実際のデータに適用する例を見ていきます。
【ポイント1】 単位根の検定
VECMの前提として、対象とする時系列の単位根の有無を確認します。本稿では2.3項に掲載したサンプルコードでも使用したAugmented Dickey-Fuller (ADF) 検定を使う例を後述します。
【ポイント2】 共和分性の検定
単位根系列の共和分性の有無を検定します。このための手法としてEngle-Granger検定、Johansen検定等が知られています。本稿では多変数に対応できる後者の検定手法を使う例を後述します。
【ポイント3】 グレンジャー因果関係の検定
選定した遅延次数に基づいて、因果関係の有無を検定します。サンプルコードでは statsmodels のgrangercausalitytests 関数を用いて因果性を検定します。 検定結果には、F統計量やp値が表示されます。p値が設定した有意水準(例えば0.05)未満であれば、 が をグレンジャー的に予測することができると判断します。
【ポイント5】VECMの構築と予測
VECM(ベクトル誤差修正モデル)を構築し、構築したモデルを用いて未来の値を予測します。実際のデータと比較することでモデルの精度を検証します。予測精度の評価には、MSE(平均二乗誤差)やRMSE(平方根平均二乗誤差)などの指標を使用します。
サンプルコードでは、米国の10年物国債金利と2年物国債金利を対象時系列としての共和分性を分析します。検定をかける期間を6か月として、2001年以降開始日をシフトしながら各ウィンドウ期間での検定を行い、共和分検出頻度を求めています。
# tsa_vecm_predict3.py
# 米国長短国債金利の共和分性検証
import pandas as pd
from pandas_datareader import data as pdr
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller, coint
from statsmodels.tsa.vector_ar.vecm import coint_johansen,VECM, select_order
from sklearn.preprocessing import MinMaxScaler
import japanize_matplotlib
import datetime
from numpy.linalg import LinAlgError
import warnings
from statsmodels.tsa.stattools import grangercausalitytests
# 日付範囲の指定
start_date = datetime.datetime(2001, 1, 1)
end_date = datetime.datetime(2024, 12, 31)
# 米国2年債金利 (DGS2) と10年債金利 (DGS10) のデータを取得
short_rate_df = pdr.DataReader("DGS2", "fred", start_date, end_date).rename(columns={"DGS2": "Short_Rate"})
long_rate_df = pdr.DataReader("DGS10", "fred", start_date, end_date).rename(columns={"DGS10": "Long_Rate"})
# データの結合とスプレッドの計算
data = pd.merge(short_rate_df, long_rate_df, left_index=True, right_index=True).dropna()
data["Spread"] = data["Long_Rate"] - data["Short_Rate"]
data.dropna(inplace=True)
# 正規化前のデータの表示用(元データ)
data_raw = data.copy()
# 正規化
scaler = MinMaxScaler()
data_normalized = pd.DataFrame(scaler.fit_transform(data), index=data.index, columns=data.columns)
# ADF検定による単位根検定
def adf_test(series, name):
adf_result = adfuller(series)
print(f"{name} ADF 検定統計量: {adf_result[0]:.3f}")
print(f"{name} p値: {adf_result[1]:.3f}")
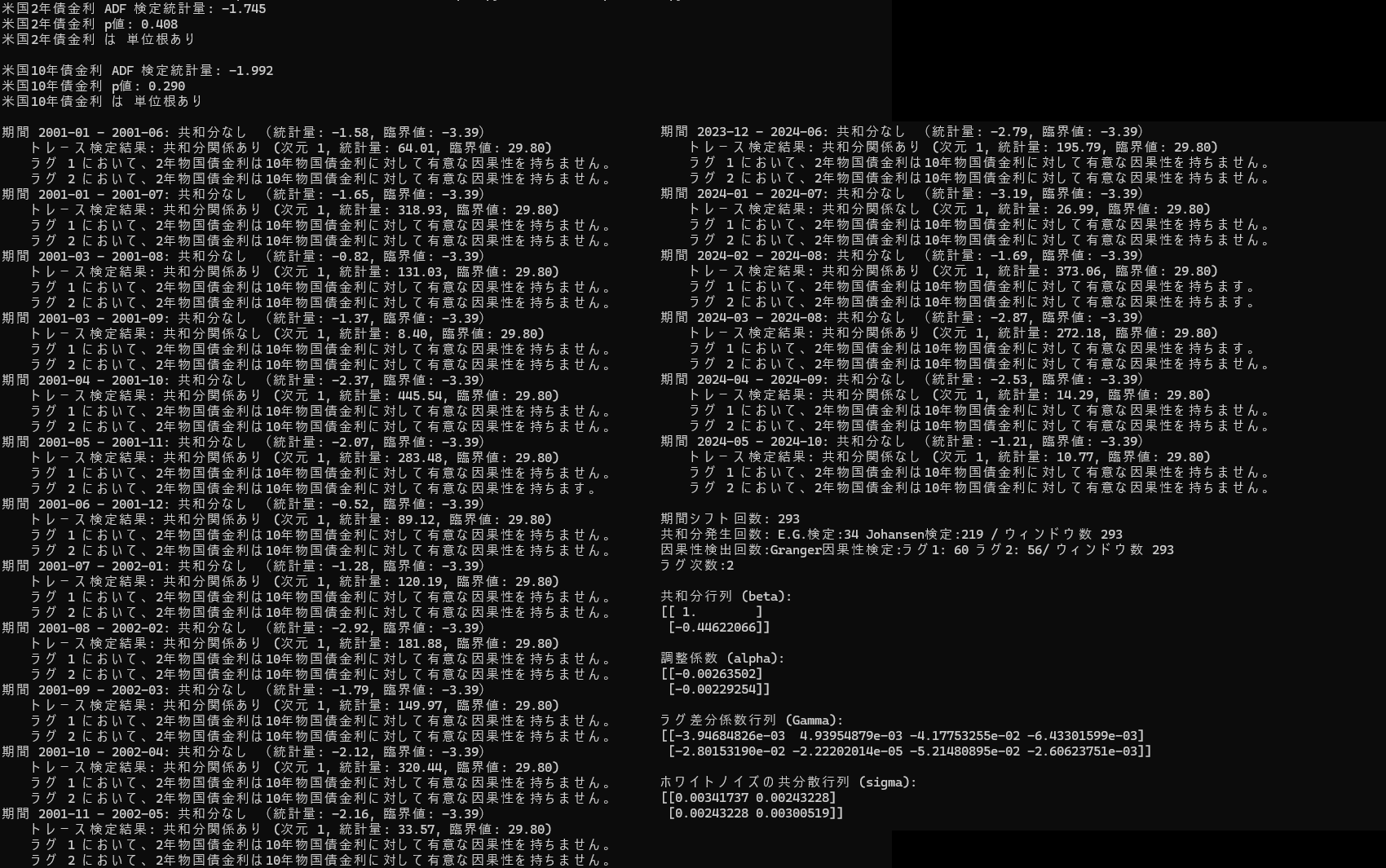
print(f"{name} は {'単位根あり' if adf_result[1] > 0.05 else '単位根なし'}\n")
adf_test(data_normalized['Short_Rate'], "米国2年債金利")
adf_test(data_normalized['Long_Rate'], "米国10年債金利")
# ウィンドウ設定(6か月のウィンドウ、1か月ずつシフト)
window_size_months = 6
step_months = 1
window_results = []
count_coint_eg = 0
count_coint_jo = 0
caus = [0,0]
window_days = window_size_months * 20 # 月次20営業日を仮定
for start in range(0, len(data_normalized) - window_days, step_months * 20):
# ウィンドウごとにデータをスライス
window_data = data_normalized.iloc[start:start + window_days]
dgs2_window = window_data['Short_Rate']
dgs10_window = window_data['Long_Rate']
# Engle-Granger共和分検定
coint_t, p_value, crit_value = coint(dgs2_window, dgs10_window)
is_coint = p_value < 0.05
window_results.append((window_data.index[0], window_data.index[-1], is_coint))
if is_coint:
print(f"期間 {window_data.index[0].strftime('%Y-%m')} - {window_data.index[-1].strftime('%Y-%m')}: 共和分あり (統計量: {coint_t:.2f}, 臨界値: {crit_value[1]:.2f})")
count_coint_eg += 1
else:
print(f"期間 {window_data.index[0].strftime('%Y-%m')} - {window_data.index[-1].strftime('%Y-%m')}: 共和分なし (統計量: {coint_t:.2f}, 臨界値: {crit_value[1]:.2f})")
# Johansen共和分検定
try:
johansen_test = coint_johansen(window_data, det_order=0, k_ar_diff=1)
trace_stat, crit_val = johansen_test.lr1[0], johansen_test.cvt[:,1][0]
if trace_stat > crit_val:
print(f" トレース検定結果: 共和分関係あり (次元 1, 統計量: {trace_stat:.2f}, 臨界値: {crit_val:.2f})")
count_coint_jo += 1
else:
print(f" トレース検定結果: 共和分関係なし (次元 1, 統計量: {trace_stat:.2f}, 臨界値: {crit_val:.2f})")
except LinAlgError as e:
print(f"エラー: {e} - ウィンドウ範囲: {window_data.index[0]} - {window_data.index[-1]}")
# グレンジャー因果性検定
# 2年物国債金利が10年物国債金利に対して因果性を持つか確認
# max_lag でラグ数を指定
max_lag = 2 # 最適ラグ数を設定する
# 因果性検定の実行
# grangercausalitytests 関数は、データが [目的変数, 説明変数] の順であることが必要
# ここでは、10年物金利を目的変数、2年物金利を説明変数として設定
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("ignore") # すべての警告を無視
causality_test_result = grangercausalitytests(window_data[['Long_Rate', 'Short_Rate']], maxlag=max_lag, verbose=False)
# 結果の確認
# 各ラグ数について、F検定の結果が表示されます。
# p値が有意水準(例:0.05)以下であれば、因果関係があると判断します。
for lag, test_results in causality_test_result.items():
f_test_pvalue = test_results[0]['ssr_ftest'][1] # F検定のp値
#print(f"Lag {lag}: p-value = {f_test_pvalue}")
if f_test_pvalue < 0.05:
print(f" ラグ {lag} において、2年物国債金利は10年物国債金利に対して有意な因果性を持ちます。")
caus[lag-1] += 1
else:
print(f" ラグ {lag} において、2年物国債金利は10年物国債金利に対して有意な因果性を持ちません。")
print(f"\n期間シフト回数: {len(window_results)}")
print(f"共和分発生回数: E.G.検定:{count_coint_eg} Johansen検定:{count_coint_jo} / ウィンドウ数 {len(window_results)}")
print(f"因果性検出回数:Granger因果性検定:ラグ1: {caus[0]} ラグ2: {caus[1]}/ ウィンドウ数 {len(window_results)}")
# 最適ラグの選択とVECMモデルの適合
# ValueWarning が出力される。回避方法が不明のためここではメッセージ出力を抑制する
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always") # すべての警告をキャッチ
# VECMの最適ラグ順の選択
lag_order = select_order(data[["Long_Rate", "Short_Rate"]], maxlags=10, deterministic="ci")
optimal_lag = lag_order.aic
# VECMモデルの適合
vecm = VECM(data[["Long_Rate", "Short_Rate"]], k_ar_diff=optimal_lag, coint_rank=1, deterministic="ci")
vecm_fit = vecm.fit()
# 警告の表示. 抑制する場合はコメントアウトする
#for warning in w:
# print(f"Warning発生箇所: {warning.filename}, 行: {warning.lineno}")
# print(f"Warningメッセージ: {warning.message}")
# 推定されたパラメータを表示
print(f"ラグ次数:{optimal_lag}\n")
print(f"共和分行列 (beta):\n{vecm_fit.beta}\n")
print(f"調整係数 (alpha):\n{vecm_fit.alpha}\n")
print(f"ラグ差分係数行列 (Gamma):\n{vecm_fit.gamma}\n")
print(f"ホワイトノイズの共分散行列 (sigma):\n{vecm_fit.sigma_u}\n")
# 可視化
plt.figure(figsize=(14, 8))
# 長期金利と短期金利のプロット
axs0 = plt.subplot(2, 1, 1)
plt.plot(data.index, data["Long_Rate"], label="長期金利(10年)", color="blue")
plt.plot(data.index, data["Short_Rate"], label="短期金利(2年)", color="orange")
plt.ylabel("金利 (%)")
plt.legend(loc="upper left")
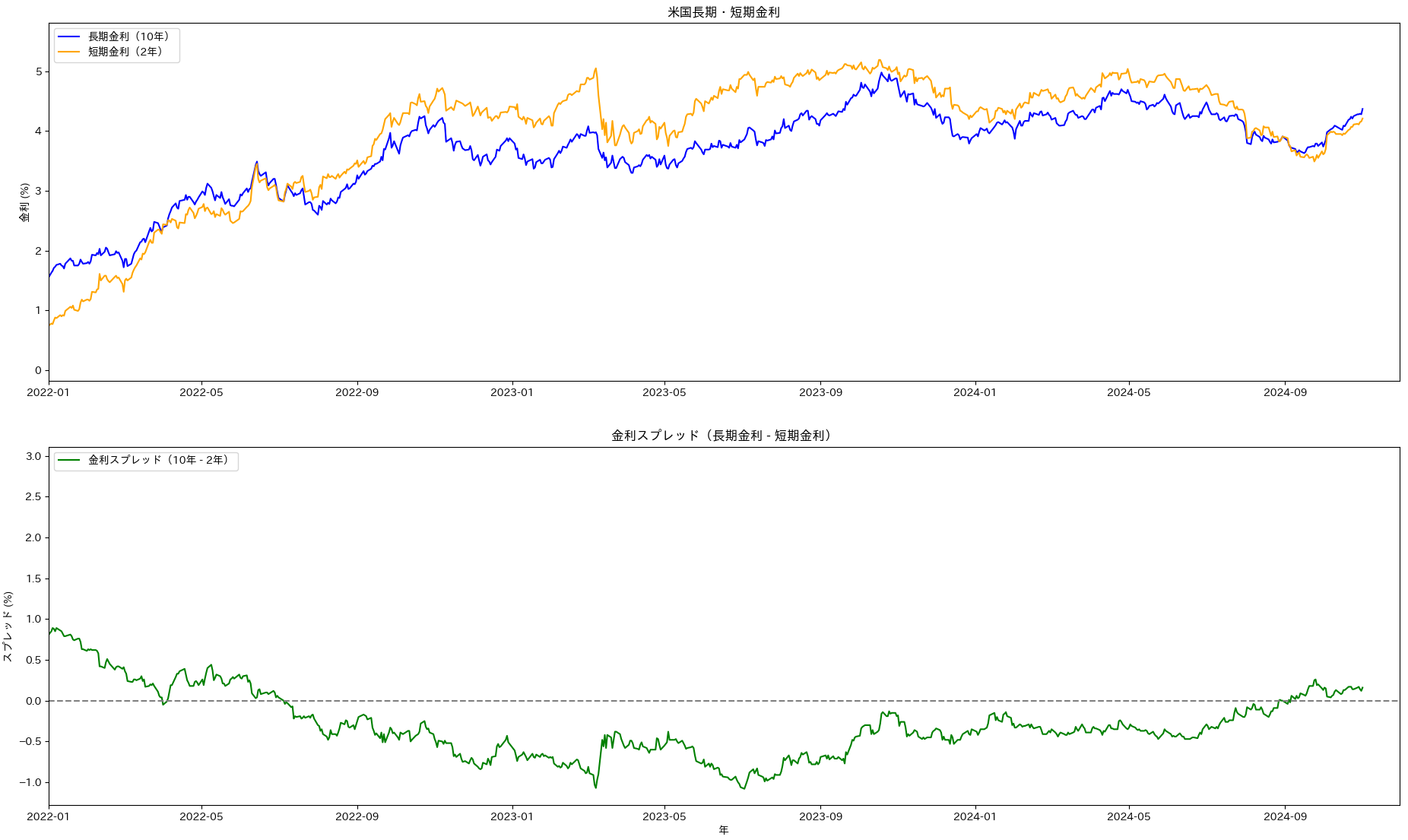
plt.title("米国長期・短期金利")
# スプレッドのプロット
axs1 = plt.subplot(2, 1, 2)
plt.plot(data.index, data["Spread"], label="金利スプレッド(10年 - 2年)", color="green")
plt.axhline(y=0, color="gray", linestyle="--")
plt.ylabel("スプレッド (%)")
plt.xlabel("年")
plt.legend(loc="upper left")
plt.title("金利スプレッド(長期金利 - 短期金利)")
# x軸の表示期間を指定(例:2019年から2024年)
axs0.set_xlim(pd.Timestamp('2022-01-01'), pd.Timestamp('2024-11-30'))
axs1.set_xlim(pd.Timestamp('2022-01-01'), pd.Timestamp('2024-11-30'))
plt.tight_layout()
plt.show()
コードの実行結果について補足します。
推定結果に基づき、VECM(ベクトル誤差修正モデル)の式を行列形式で表現します。ラグ次数2のモデル式は以下の通りです。
ここで、各項目は次のように定義されます。
(1) 変数ベクトル
(2) 調整係数 ()
(3) 共和分ベクトル ()
(4) ラグ差分係数行列 () ラグ次数が2のため、ラグ差分係数行列 は以下の二つの行列で表されます。
(5) ホワイトノイズの共分散行列 ()
これにより、VECMのモデル式は以下のように表されます。
推定されたモデルに基づき、変数間の相互関係と予測可能性について考察します。
VECMは、変数間に 共和分関係(長期的な均衡関係) があることを前提としています。293回のウィンドウシフトによる共和分検定の結果、共和分性が認められた回数は Engle-Granger検定(34回 )とJohansen検定(219回)となり、大きな違いが出ています。データが複数の変数や複雑な共和分関係を持つ場合はJohansen検定の方が適しているのでここでは、 Johansen 検定結果を採用しておきます。すると二つの時系列は高頻度で共和分性を示しています。そして長期均衡は次のように表現されます
調整係数 は、前期の均衡からの乖離に対する各変数の修正速度を示しています。この 値が負であるため、長期均衡からの乖離が発生した場合、それぞれの変数が乖離を解消する方向に調整されることがわかります。このメカニズムにより、短期的乖離があっても長期的には均衡に戻ることが期待できます。
ラグ差分係数行列 は、各変数の短期的な動態を示します。ラグ次数が2であるため、このモデルには過去2期分の変数差分が含まれています。これは、各変数の現在の変化率が、過去の変化に影響を受けることを意味します。 は1期前の変数差分の影響を表し、 は2期前の変数差分の影響を表しています。
(45)式より、10年物国債金利変動 に対して 一期前と二期前の2年国債金利変動 、 の影響が比較的大きいです。一方、2年物国債金利変動 に対する 過去の 10 年物国債金利変動 、 の影響は大きくありません。このことから、短期金利の変動が長期金利に影響を与えている可能性が見えます。
因果関係の解釈
上述のVECMモデル式のラグ差分係数が示す特徴は、短期国債金利の変動が長期国債金利に影響を与えているようには見えます。しかしながらウィンドウ期間 293 回のうちで、2年物国債金利の変動が10年物国債金利の変動に対して因果性を示した件数が、一期前が60回、二期前が 56 回であったことから、どのような時期においても常に確認できる性質とまでは言えません。なにか他の補強的な分析を組み合わせてみる必要がありそうです。
3. 移動平均モデル#
ここまで取り扱ってきましたAR(自己回帰)モデルの他にさまざまな応用領域に適したモデルが多数開発されています。この節では移動平均(Moving average,MA)モデル、分散不均一モデル(Autoregressive conditional heteroscedasticity model, ARCH model)について補足しておきます。
移動平均型のモデルに対しては、各モデルの予測の特徴を比較するために、サンプルコードのなかでは以下、総務省による家計調査の項目に入っている消費支出を共通に使うこととします。
【家計調査(家計収支編) 時系列データ(二人以上の世帯)https://www.stat.go.jp/data/kakei/longtime/index.html#time】
我が国における世帯全体の消費支出総額(GDP統計の家計最終消費支出に相当)や消費動向指数(CTIマクロ,CTIミクロ)等の基本的な指数を算出するためのベースとなる統計データです。 サイトからダウンロードしたcsvの第一行および第一列~第5列は参照しないので削除しておきます。
以下のコードによりコンバートしたcsvを作成します。
# tsa_predi_conv_hmona.py
# 家計調査(家計収支編) 時系列データ(二人以上の世帯)
# https://www.stat.go.jp/data/kakei/longtime/index.html#time
# 元csvから使わない行、列を削除した'家計調査(二人以上世帯).csv'
# をあらかじめ作成しておく
#
import pandas as pd
# CSVファイルの読み込み
file_path = '家計調査(二人以上世帯).csv'
raw_data = pd.read_csv(file_path, header=None)
#print(raw_data)
# 年次情報の抽出
years = raw_data.iloc[0, 1::12].repeat(12).reset_index(drop=True)
# 年月ラベルを作成。空白文字は削除しておく
months = raw_data.iloc[1, 1:].reset_index(drop=True).str.strip()
ym = years+months
ym = ym.dropna(how='any') # NaN行を削除
# データの抽出
data = raw_data.iloc[2:, 1:].reset_index(drop=True)
data.columns = ym
# 分類項目名の設定
data.index = raw_data.iloc[2:, 0].values
# データフレームの転置
df = data.transpose().reset_index()
df.columns = ['年月'] + list(df.columns[1:])
# データフレームの保存
# excelで参照することがあるのでUTF-8 BOM付きで出力します
df.to_csv('家計調査(二人以上世帯コンバート).csv', index=False,encoding="utf-8_sig")
3.1. MAモデル#
移動平均モデル(Moveing Average,MA)は、時系列分析における基本的なモデルの一つであり、過去の誤差を用いて現在の値を説明するモデルです。以下では、MAモデルの定義、数式、特徴、そして具体的な例について説明します。
移動平均モデルは、現在の観測値が過去のホワイトノイズの線形結合として次のように定義されます。
ここで、 は時刻 における観測値、 は定数項であり過程の期待値に等しい。 は時刻 におけるホワイトノイズ(平均が0、分散が一定で独立な誤差項)。 はMAモデルのパラメータ。モデルの次数 は、過去のいくつの誤差項を用いるかを示すパラメータで、MA(q) と表記されます。
MAモデルの特徴をまとめておきます。
-
定常性
MAモデルは定義式が示すように定常過程であり、自己相関関数(ACF)は有限のラグ以降は 0 になります。 -
有限の過去依存性
MAモデルは有限個の過去の誤差項に依存するため、現在の値が有限の過去にのみ影響されます。これはARモデル(自己回帰モデル)とは対照的です。 -
誤差の伝播
過去の誤差項が現在の値にどのように影響を与えるかを示すため、ショックが伝播するプロセスを表現します。
次に、MAモデルを使い、家計調査の統計から将来値を予測するコードを書いてみます。 2000年から2023年までの統計データをモデルの学習用とし、2024年の1月~5月を予測します。 最適なモデルを知るために、3次までの次数の各モデルの情報量基準(AIC)を比較して最小のモデルを選択します。 コードではAR,MAを一つのクラスで利用できる統合されたインタフェース(SARIMAXクラス)を使っています。
# tsa_predi_ma3.py
# MAモデルを使い、家計調査統計時系列データを予測する。
# AICの評価値を比較し最適なモデルを選択する。
#
import japanize_matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.model_selection import train_test_split
#
# 家計調査(家計収支編)時系列データ(二人以上の世帯)をCSVから
# 読み込みデータフレームを返す
np.random.seed(42)
n_train = 24 * 12 # 2000-2023 24年間のデータポイント(月次データ)
n_test = 1 * 5 # 1年間のデータポイント(月次データ)
total_points = n_train + n_test
df = pd.read_csv('家計調査(二人以上世帯コンバート).csv', usecols=[0,11],index_col=0)
df.index = pd.to_datetime(df.index,format='%Y年%m月')
# トレーニングデータとテストデータに分割
train_data = df.iloc[:n_train,:]
test_data = df.iloc[n_train:,:]
print(df)
# 最適なMAモデルの特定と学習
# データの標準化
mean_train = train_data['消費支出'].mean()
std_train = train_data['消費支出'].std()
train_norm = (train_data['消費支出'] - mean_train) / std_train
print(mean_train,std_train)
# パラメータの初期推定
q = range(0, 4)
aic_values = []
params = []
for param in q:
try:
model = SARIMAX(train_norm, order=(0, 0, param))
results = model.fit(disp=False)
aic_values.append(results.aic)
params.append(param)
except:
continue
# 最適なパラメータの選択
best_param = params[np.argmin(aic_values)]
print(f'最良のパラメータ: MA({best_param})')
# 最適なモデルの学習
best_model = SARIMAX(train_norm, order=(0, 0, best_param))
best_model_fit = best_model.fit(disp=False)
ma_l1 = best_model_fit.params['ma.L1'] if 'ma.L1' in best_model_fit.params else 0
ma_l2 = best_model_fit.params['ma.L2'] if 'ma.L2' in best_model_fit.params else 0
ma_l3 = best_model_fit.params['ma.L3'] if 'ma.L3' in best_model_fit.params else 0
sigma2 = best_model_fit.params['sigma2'] if 'sigma2' in best_model_fit.params else 0
print("学習結果のパラメータ:",ma_l1,ma_l2,ma_l3,sigma2)
# 評価期間の予測
pred_start = test_data.index[0]
pred_end = test_data.index[-1]
predictions = best_model_fit.predict(start=pred_start, end=pred_end)
predictions2 = predictions * std_train + mean_train # 標準化を元に戻す
# 予測結果と実際のデータのプロット
plt.figure(figsize=(14, 7))
plt.plot(train_data, label='実績値(学習期間)', color='black')
plt.plot(test_data, label='実績値(予測期間)', color='blue')
forecast_index = pd.date_range(start='2024-01-01', periods=n_test, freq='MS')
plt.plot(forecast_index,predictions2, label='MAモデル予測値', color='red')
plt.xlabel('日月')
plt.ylabel('消費支出(円)')
plt.title('二人以上世帯の消費支出: MAモデル予測値 vs 実績値')
plt.legend()
plt.grid()
# 表示期間を限定する
plt.xlim(pd.Timestamp('2022-01-01'), pd.Timestamp('2024-05-01'))
# フィッティング結果のレポート
print(best_model_fit.summary())
plt.show()
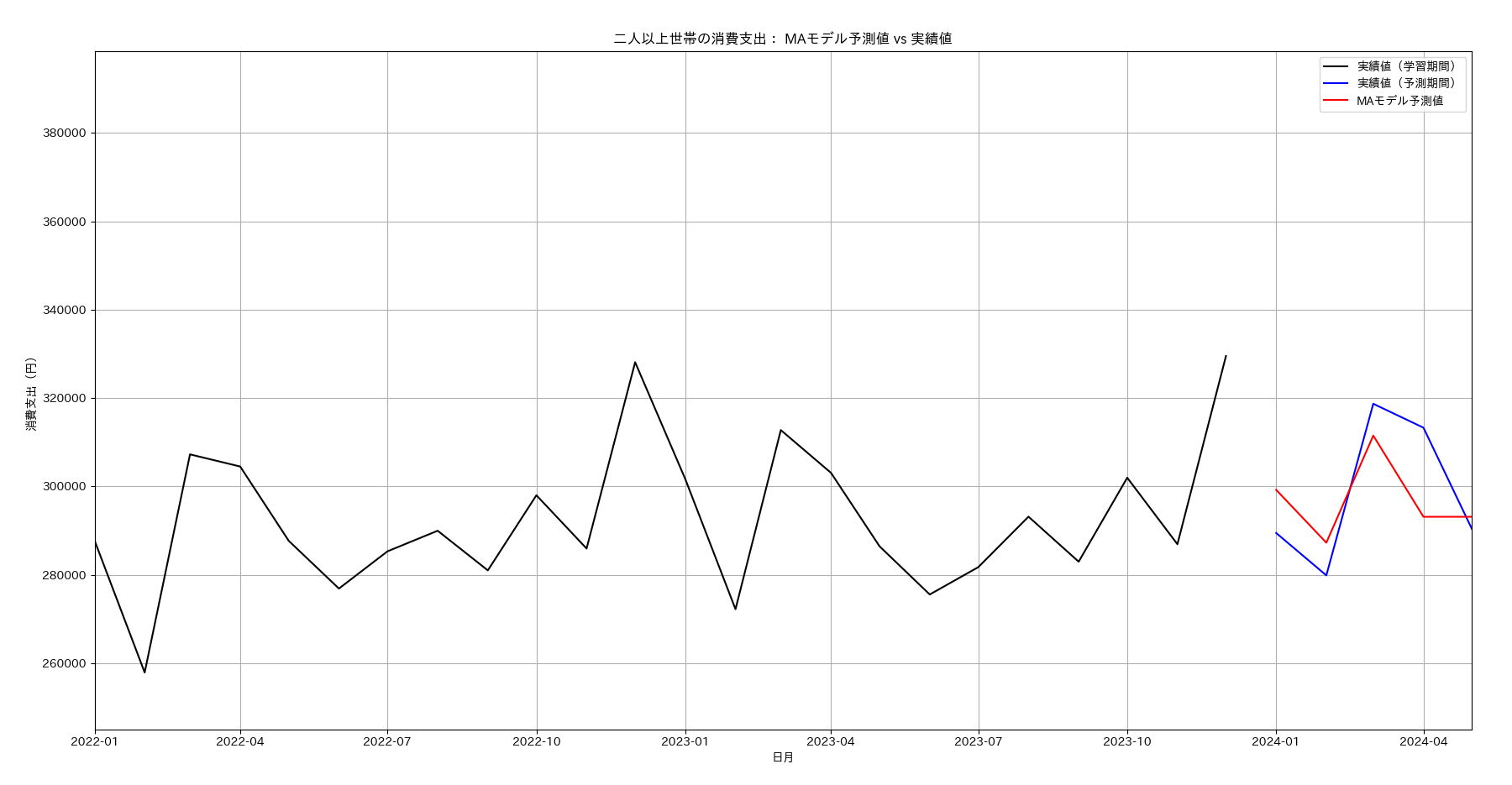
AICの評価の結果MA(3)モデルが選択されました。
3.2. ARMA/ARIMA/SARIMA#
ARMA
自己回帰移動平均(AutoRegressive Moving Average,ARMA)モデルは、自己回帰 (AR) 部分と移動平均 (MA) 部分を組み合わせたモデルです。AR 部分の次数 p と MA 部分の次数 q を使って、MA(p,q)と表記します。
ここで、 は時系列の現在の値。 は自己回帰係数。 は自己回帰項の次数。 は移動平均係数。 は移動平均項の次数。誤差項 はホワイトノイズ(平均0、分散のランダム誤差)
未知の時系列のモデルを推定する場合、単独のARモデルあるいはMAモデルにより推定することと比べて、説明力が向上する分、必要とする次数が少なくて済むメリットがあるといわれています。定義式から、ARモデルの部分が定常であればARMAモデルも定常にありますので、未知の時系列が定常性を有する場合に適したモデルであることがわかります。
ARIMA
対象とする時系列が非定常の場合、例えば第2節でとりあげた株価のモデル化の記述を思い出してみましょう。株価自体は非定常ですが前日差分(収益率)をとると定常時系列になる、いわゆる和分過程の条件を満たす銘柄が非常に多いことを示しました。
そこで対象とする時系列の差分過程にARMAモデルを適用することで、非定常過程を扱うことができるようにしたモデルを 自己回帰和分移動平均(Autoregressive integrated moving average,ARIMA)モデルと呼びます。
ARIMA(p, d, q)モデルは以下のように表されます。
ここで、 は時系列データの現在の値。 は差分演算子。 は差分次数(非定常成分を取り除くための次数)。 は定数項。 はAR成分の係数。 は誤差項(ホワイトノイズ)。 はMA成分の係数。 はAR成分の次数。 はMA成分の次数 。
ラグ演算子、ラグ多項式を使ってモデル式を表現することがしばしば行われますので、以下に補足しておきます。
この定義式の、 に関する項を下記のように左辺に集めます。
差分演算子を次のようにラグ演算子 L を使って表記します
すると、は次のように表せます。
したがって、和の部分は
と を統合して考えると、
ここで、は共通因子であるため、これを括り出すと、
このとき、
であるため、式は
と書き換えられます。これにより、元の式
はラグ演算子を用いてと表現できることが示されました。
次に右辺、
をラグ演算子を用いて書き換えます。
共通因子を括り出すことで、
となります。
ここで、 にラグ演算子を作用させる演算子の多項式を以下のように定義します。
これにより右辺を簡潔に表現できます。
上記をまとめると、ARIMAモデルの定義式はラグ演算子を用いて以下のように表すことがわかりました。
SARIMA
ARIMAモデルに対して、さらに季節性を考慮するために、季節的自己回帰(SAR)、季節的差分(階)、および季節的移動平均(SMA)を導入したモデルが SARIMA(季節調整ARIMA) です。季節性を考慮することで、パラメータが増え、一般にモデルを SARIMA()() と表記します。
ARIMAの自己回帰項に 次の季節的自己回帰項(SAR): を追加しています。そして移動平均項に季節的移動平均項(SMA): を追加しています。 は、 期間の周期を除去するために季節的差分(階): を作用させた後で非季節的差分(階): を作用させたものです。
ラグ演算子を用いた形式で表すこともできます。
ここで、
は季節ラグ演算子。は季節の周期を表す。例えば月次データならと表記します。
は季節的自己回帰項の多項式(次数)。
は季節的移動平均項の多項式(次数)。
は季節差分演算子です。
注) statsmodels ドキュメント では上式に対応して以下の式が記載されています。季節成分のラグ多項式が 、 と表記され、トレンド項 が追加されています。
さて、この辺で本項のARMA系モデルを実際に使ってみましょう。例題として世帯の消費支出を予測してみます。 MAモデルのときと同じように、最適なモデルを知るために、4次までの次数の各モデルの情報量基準(AIC)を比較して最小のモデルを選択します。以下のコードではモデリングのためにstatsmodels のSARIMAXクラスを利用しました。
# tsa_predi_arima3.py
# ARIMAモデルを使い、家計調査統計時系列データを予測する。
# AICの評価値を比較し最適なモデルを選択する。
#
import japanize_matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.model_selection import train_test_split
import warnings,sys
from statsmodels.tsa.stattools import adfuller
import itertools
# 警告メッセージを無視する設定
warnings.filterwarnings("ignore", message="Non-invertible starting MA parameters found. Using zeros as starting parameters.")
warnings.filterwarnings("ignore", message="Non-stationary starting autoregressive parameters found. Using zeros as starting parameters.")
warnings.filterwarnings("ignore", message="No frequency information was provided, so inferred frequency MS will be used.")
#
# 家計調査(家計収支編)時系列データ(二人以上の世帯)をCSVから
# 読み込みデータフレームを返す
np.random.seed(42)
n_train = 24 * 12 # 2000-2023 24年間のデータポイント(月次データ)
n_test = 1 * 5 # 1年間のデータポイント(月次データ)
total_points = n_train + n_test
df = pd.read_csv('家計調査(二人以上世帯コンバート).csv', usecols=[0,11],index_col=0)
df.index = pd.to_datetime(df.index,format='%Y年%m月')
# トレーニングデータとテストデータに分割
train_data = df.iloc[:n_train,:]
test_data = df.iloc[n_train:,:]
# データの標準化
mean_train = train_data.mean().values.flatten()[0]
std_train = train_data.std().values.flatten()[0]
print(std_train,mean_train)
train_standardized = (train_data - mean_train) / std_train
print(train_standardized)
# 最適なARIMAモデルの特定と学習
# パラメータの初期推定
p = d = q = range(0, 4)
pdq = [(x, y, z) for x in p for y in d for z in q]
aic_values = []
params = []
for param in pdq:
try:
model = SARIMAX(train_standardized, order=param, seasonal_order=(0, 0, 0, 0), exog=None)
results = model.fit(disp=False)
aic_values.append(results.aic)
params.append(param)
except:
continue
# 最適なパラメータの選択
best_param = params[np.argmin(aic_values)]
print(f'最良のパラメータ: {best_param}')
# 最適なモデルの学習
best_model = SARIMAX(train_standardized, order=best_param,seasonal_order=(0, 0, 0, 0), exog=None)
best_model_fit = best_model.fit(disp=False)
# 評価期間の予測
pred_start = test_data.index[0]
pred_end = test_data.index[-1]
predictions_standardized = best_model_fit.predict(start=pred_start, end=pred_end, dynamic=False)
# 標準化解除
predictions_standardized.name = '消費支出'
predictions_standardized.index.name = '年月'
print(predictions_standardized.index.name,predictions_standardized.name)
print(std_train,mean_train)
print(predictions_standardized)
predictions = (predictions_standardized * std_train) + mean_train
print(predictions)
# 予測結果と実際のデータのプロット
plt.figure(figsize=(14, 7))
plt.plot(train_data, label='実績値(学習期間)', color='black')
plt.plot(test_data, label='実績値(予測期間)', color='blue')
plt.plot(predictions, label='ARIMAモデル予測値', color='red')
plt.xlim(pd.Timestamp('2022-01-01'), pd.Timestamp('2024-05-01'))
plt.xlabel('日付')
plt.ylabel('消費支出')
plt.title('二人以上世帯の消費支出: ARIMAモデル予測値 vs 実績値')
plt.legend()
plt.grid()
plt.show()
# 学習したパラメータの表示
print(best_model_fit.summary())
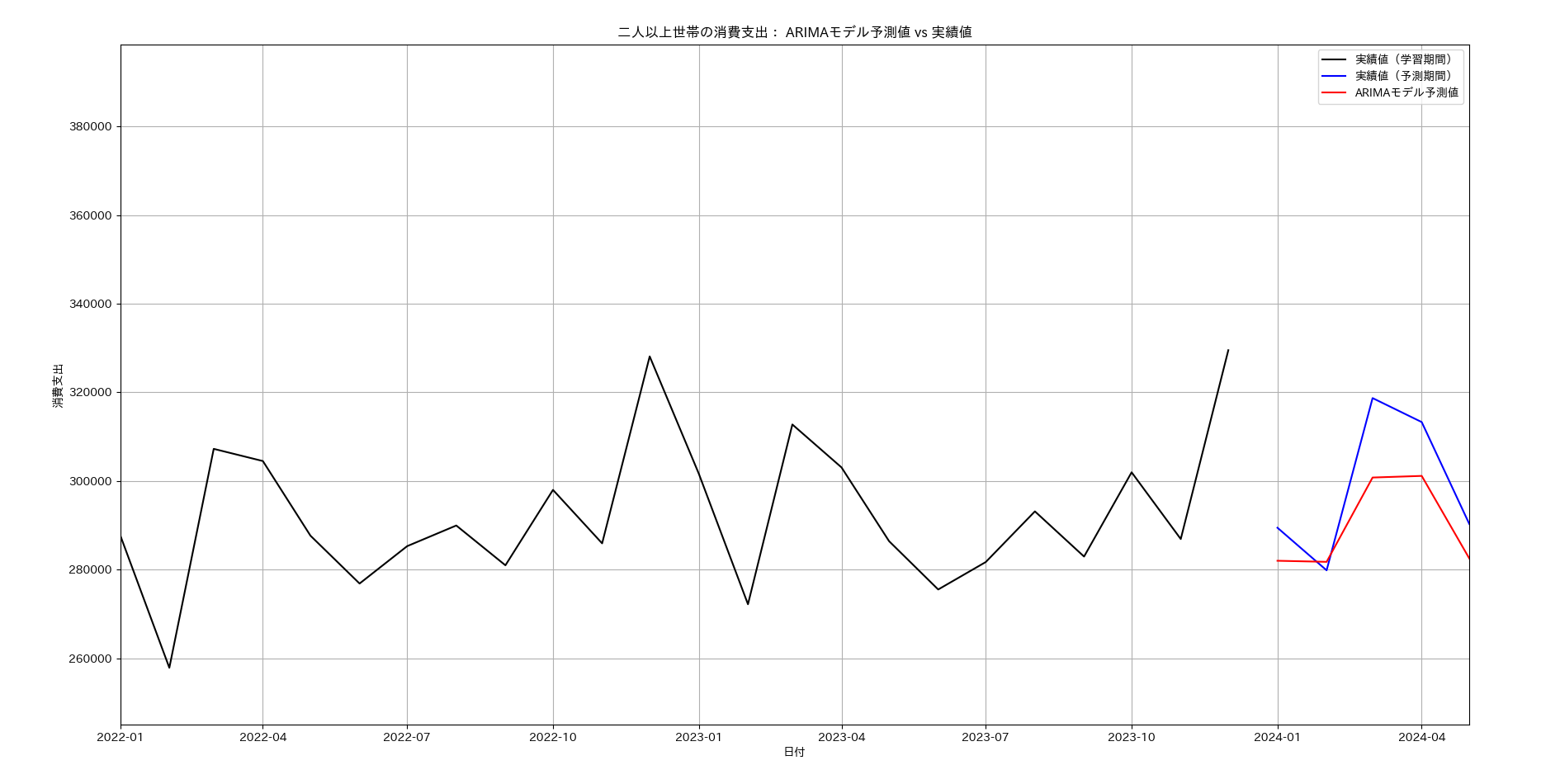
コードを実行すると、最良のパラメータの組は(p,d,q) = (2,1,3)となりました。ちなみに探索する次数を3までにした場合の最良パラメータの組は(p,d,q) = (2,1,1)となります。 d = 1 なので、元の時系列自体は非定常的であると考えるところです。そこで以下のように定常性を検定するコードを追加して実行すると、ADF検定では定常性を示し(単位根がない)、KPSS検定では非定常性を示す(単位根がある)という相反する結果となりました。stasmodelsのマニュアルの該当箇所(https://www.statsmodels.org/dev/examples/notebooks/generated/stationarity_detrending_adf_kpss.html)はこのケースは差分系列が定常であることを示す、と説明しています。とすると、パラメータ推定の結果は整合的であると言えます。
from statsmodels.tsa.stattools import adfuller,kpss
# ADF検定の実行
# 帰無仮説: 系列には単位根がある。
# 対立仮説: 系列には単位根が無い。
result = adfuller(train_standardized)
print('ADF検定統計量:', result[0])
print('p-値:', result[1])
print('臨界値:', result[4])
# KPSS検定の実行
# 帰無仮説: 系列には単位根が無い。
# 対立仮説: 系列には単位根がある。
result = kpss(train_standardized)
print('KPSS検定統計量:', result[0])
print('p-値:', result[1])
print('臨界値:', result[3])

4. 分散不均一モデル#
時系列データの分散が時間とともに変動する性質を示すことを、分散不均一性(heteroscedasticity) と呼びます。1970年代から1980年代にかけて、金融市場のデータ分析において、価格変動やリターンの時系列データに異常な変動(ボラティリティクラスター)が観察されるようになりました。ある期間に高い変動が見られると、その後も高い変動が続く傾向があり、逆に低い変動が見られると、その後も低い変動が続くことが多いのです。これは従来の定常的な時系列モデルでは説明が難しい現象であり、分散不均一性の重要性が認識されたきっかけとなっています。
4.1. ARCHモデル#
ロバート・エンゲル(1982年)は、分散不均一な変動の自己相関を捉えるために、従来の時系列モデルに条件付き分散の概念を導入したARCHモデル(Autoregressive Conditional Heteroskedasticity)を提案しました。
ARCHモデルの基本的なアイデアは、時系列データの現在の分散が過去の誤差項の2乗和に依存するという考え方です。
まず、以下のように平均の周りでランダにな変動するシンプルな時系列を考えるところから出発します。
ここで、 は時点 における条件付き標準偏差、 はホワイトノイズ(平均0、分散1)を表します。
ARCHモデルの核心は、条件付き分散 が過去の誤差項の2乗和に依存することです。そこで影響を現在の分散が影響を受けるもっとも過去のラグ q により特徴づけられるARCHモデルを ARCH(q) と表記し、次のように定義します。
ここで、 、 (i=1, 2, ..., q) です。この式は、現在の分散 が過去の q 期間の誤差項の2乗和の重み付け和で決定されることを示しています。
ARCHモデルの推定は通常、最尤法を用いて行われます。具体的には、観測データから誤差項 を計算し、条件付き分散 を推定するために、最尤法によりパラメータ を推定します。
尤度関数は、観測されたデータが特定のパラメータセットの下で発生する確率を示します。ARCHモデルにおいて、尤度関数を導出するために、まず条件付き尤度を考えます。
観測されたデータ が与えられたとき、条件付き尤度関数 は以下のように定義されます。
ここで、 は時刻 までの情報集合を表し、 は条件付き密度関数です。ARCHモデルの場合、誤差項 は条件付き正規分布に従うため、条件付き密度関数は次のように表されます。

ここで、 です。
尤度関数を最大化するために、対数を取った対数尤度関数を使用します。対数尤度関数 は次のように定義されます。
条件付き密度関数 を代入すると、対数尤度関数は次のようになります。
この対数尤度関数の最大化するパラメータ を、数値最適化手法を使って求めます(後述するサンプルコードではscipyのminimize関数を利用しています)。
そして、推定されたパラメータを使用し、定義式に従って条件付き分散 を計算します。
ARCHモデルが金融市場のデータに見られるボラティリティクラスターの説明を目的として登場したことから、この手法は金融市場のリスク管理、オプション価格付け、ポートフォリオ管理などに広く応用されています。
4.2. GARCHモデル#
ARCHモデルはその後の研究に大きな影響を与えました。Bollerslev(1986年)が提案したGARCH(Generalized Autoregressive Conditional Heteroskedasticity)モデルでは、以下の定義式に見るように、条件付き分散が 過去の条件付き分散にも依存するよう拡張されています。この結果長期的な依存関係を捉えることができるため、実務的に非常に有用です。
ここで、、 ()、および ()はモデルのパラメータです。条件付分散が影響を受けるもっとも過去のラグをqとして、モデルをGARCH(p,q)と表記します。
以下に、実際の株価時系列をGARCH(1,1) によりモデル化し、将来予測を行う例を示します。対象は日本郵船(9101)で、2019年から2023年までの株価をモデルの学習用に使い、2024年1月から7月までの株価を予測し、実際の株価推移と対比しています。
# tsa_predi_garch.py
# GARCHモデルを使い、実際の株価の動向を予測する。
#
import japanize_matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import minimize
import datetime
np.random.seed(42)
dates = pd.date_range(start='2019-01-01', end='2024-05-31', freq='B') # 'B' frequency stands for business days
n = len(dates)
# CSVを読み込みデータフレームを返す
code = '9101'
name = '日本郵船'
df = pd.read_csv(f'{code}.T.csv')
# 'Date'列をdatetime64型に変換する
df['Date'] = pd.to_datetime(df['Date'])
# 表示区間のdfを切り出す
df = df[(df['Date'] >= datetime.datetime(2019,1,1)) & (df['Date'] <= datetime.datetime(2024,10,8))]
df = df.set_index('Date')
prices = df['Close']
#print(prices)
returns = prices.diff()
#print(returns)
n = len(prices)
# 対象時系列データを訓練用とテスト用に分割する
split_date = '2024-05-31'
train_prices = prices[prices.index <= split_date]
test_prices = prices[prices.index > split_date]
train_returns = returns[prices.index <= split_date]
test_returns = returns[prices.index > split_date]
train_dates = train_prices.index
test_dates = test_prices.index
# 学習プロセスが極端な値の大小の影響を受けにくくするために対象時系列を標準化する
train_mean = np.mean(train_returns)
train_std = np.std(train_returns)
train_returns_standardized = (train_returns - train_mean) / train_std
test_returns_standardized = (test_returns - train_mean) / train_std # Standardize test data using train mean and std
# GARCH(1,1) モデルを扱うためのクラス定義
class GARCH11:
def __init__(self, returns):
self.returns = returns
self.n = len(returns)
def log_likelihood(self, params):
omega, alpha, beta = params
var = np.zeros(self.n)
var[0] = np.var(self.returns) # initialize variance
for t in range(1, self.n):
var[t] = omega + alpha * self.returns[t-1]**2 + beta * var[t-1]
ll = -0.5 * (np.log(2 * np.pi) + np.log(var) + self.returns**2 / var)
return -np.sum(ll)
def fit(self):
initial_params = [0.1, 0.1, 0.8]
bounds = [(0, None), (0, 1), (0, 1)]
result = minimize(self.log_likelihood, initial_params, bounds=bounds)
self.params = result.x
return self.params
def predict(self, steps):
omega, alpha, beta = self.params
var = np.zeros(steps)
var[0] = np.var(self.returns)
for t in range(1, steps):
var[t] = omega + alpha * self.returns[-1]**2 + beta * var[t-1]
return var
# 標準化された訓練データを使ってGARCH(1,1) モデルを学習する
garch_model = GARCH11(train_returns_standardized)
params = garch_model.fit()
print("Estimated parameters:", params)
# 学習済みパラメータを使って予測データを作成する
forecast_horizon = len(test_returns_standardized)
predicted_variances = garch_model.predict(forecast_horizon)
predicted_returns_standardized = np.random.normal(0, np.sqrt(predicted_variances))
# オリジナルのスケールに戻す
predicted_returns = predicted_returns_standardized * train_std + train_mean
# 結果をプロットする
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10), sharex=False)
ax1.plot(train_dates, train_prices, label='株価実績値(訓練期間)', color='black')
ax1.plot(test_dates, test_prices, label='株価実績値(テスト期間)', color='blue')
ax1.plot(test_dates, train_prices[-1] + np.cumsum(predicted_returns), label='株価予測値', color='red', linestyle='--')
ax1.legend()
ax1.set_xlabel('日付')
ax1.set_ylabel('株価(円)')
ax1.set_xlim(pd.Timestamp('2023-01-01'), pd.Timestamp('2024-10-08'))
ax1.set_title('%s(%s)の株価をGARCHモデルにより予測する' %(name,code))
ax2.plot(test_dates, test_returns, label='収益率実績値(テスト期間)', color='blue')
ax2.plot(test_dates, predicted_returns, label='収益率予測値', color='red', linestyle='--')
ax2.legend()
ax2.set_xlabel('日付')
ax2.set_ylabel('収益率(円)')
ax2.set_title('株価収益率')
plt.tight_layout()
plt.show()
結果は以下のようになりました。割と自然な推移のように見えますが、たまたまそうなっただけのようにも思えます。対象を増やしたり、定量的な性能評価をいろいろ試すことで理解が進むのではないかと思います。
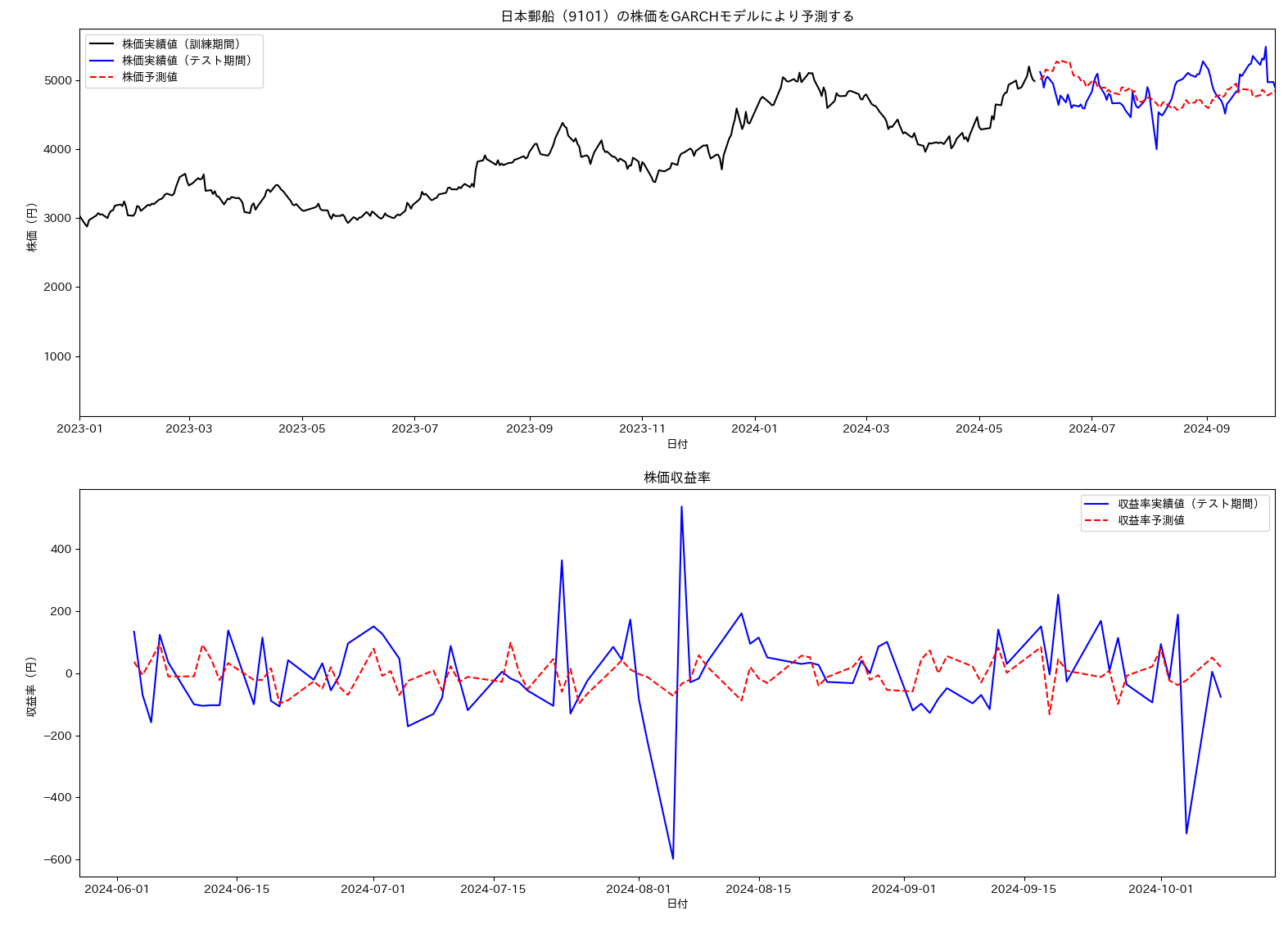
5. 状態空間モデル#
状態空間モデルの歴史は古く、 1950 年代から 1960 年代にかけて、航空機、ミサイルといった動的システムの挙動をモデル化し、リアルタイムで制御したいというニーズから発達しました。
これらのシステムの挙動は高度に動的であり、刻々と変化する情報(状態)を基に制御を行う必要があります。しかし、システムの内部状態は直接観測できないため、外部からの観測データ(レーダー測定値など)を基に、内部の「状態」を推定し、それを使ってシステムを制御する技術が必要とされました。
この問題に対処するために 1960 年にルドルフ・E・カルマンが考案したのが、カルマンフィルター(Kalman Filter)です。これは線形ガウスシステムの状態の最適推定を行う手法であり、特にノイズを含むデータに対してもロバストな推定ができるなど革新的なアイデアが提案されました。
1960 年代から 1970 年代にかけて、状態空間モデルは科学技術領域のみならず経済学や統計学の分野へも展開していきます。経済や金融市場のデータは時間とともに変化し、その変動には観測できない要因(潜在的なトレンドや季節性など)が大きな役割を果たす点で、状態空間モデルとの親和性が高いのです。
例えば、トレンドや季節変動が含まれる非定常データを明示的に扱うために、SARIMA や GARCH など複雑な時系列モデルが考案されています。これらのモデルは状態空間モデルとしてとらえることにより、観測されない潜在変数(例:トレンドや季節性)をモデルに組み込み、カルマンフィルターを始めとした制御技術の分野で高度に発達した技法を活用することができるメリットがあります。
この節では状態空間モデルの構成、推定方法、例題を順次説明していきます。記述はできるだけstatsmodelsの状態空間モデルのドキュメントと用語を合わせるようにしましたので、statsmodelsの説明ドキュメントや例題も参照すると理解が進みやすいと思います。
5.1. 状態空間モデルの構成#
状態空間モデルは、次の二つの主要な方程式で構成されます。
- 状態方程式 (State equation) システムの内部状態が時間的にどのように推移するか(遷移)を定義する。
- 観測方程式 (Observation equation) 外部から観測可能なデータ(観測データ)と、内部状態との関係を定義する。
【状態方程式 (State Equation) 】
状態方程式は、内部状態 の時間的推移方法を記述します。
ここで、
: 時刻 における の状態列ベクトル。
: の遷移行列。状態の時間的な推移を表す。
: の状態切片。時刻 におけるレベル(オフセット)。
: の選択行列。摂動(外部擾乱)が状態ベクトルに与える影響を示す。
: の摂動ベクトル。各要素はホワイトノイズであり、 の共分散行列 を持つ。
【観測方程式 (Observation Equation) 】
観測方程式は、観測データ が状態 に基づいて生成される変換式を表します。
ここで、
: の観測データベクトル(時刻 における観測値)。
: の観測行列(観測データと状態の関係を表す)。状態が直接観測される場合は単位行列。
: の状態ベクトル(時刻 における内部状態)。
: の観測切片(時刻 におけるオフセット)。
: の観測誤差ベクトル。各要素はホワイトノイズであり、 の共分散行列 を持つ。
このようにして、状態空間モデルは観測データと内部状態の動的な関係を数学的にモデル化し、観測誤差と状態摂動の両方を考慮しながら、時間的推移を予測することができます。ここで定義した状態空間モデルは、方程式の線形性及びに摂動、観測誤差の正規性から線形ガウス空間モデルと呼ぶことができます。
以下に、これまでに言及してきた各種時系列モデルは、状態空間モデルを使うことでどのように表現されるのか見ていきます。
1. ARモデルの状態空間表現
AR(p)モデルを次のように定義します。
ここで、
: 時刻 における観測値。
: 自己回帰係数。
すなわち、: 平均0、分散 の白色雑音(ホワイトノイズ)。
AR(p) の状態空間モデル化では、状態ベクトル は過去の観測値から構成される 次元のベクトルとして定義します。そして状態方程式と観測方程式を通じて観測値 を予測・更新します。
状態方程式は、状態ベクトル の時間遷移を示します。状態方程式の定数項はこの場合無いので、以下のように表すことができます。
遷移行列 は次のように定義します。
選択行列 は定数のベクトル R として表現できます。
状態ベクトル の最初の成分がそのまま観測値になるとみなすので、誤差項 は無しとします。従って観測方程式は以下のように定義します。
ここで、観測行列 。
は、と同一です。 すなわち、
2. MAモデルの状態空間表現
MA()モデルを次のように定義します。
状態ベクトル は、過去の誤差項 から構成される 次元の列ベクトルとして定義します。
観測方程式は、観測データ は状態ベクトル の線形結合として表されます。定数項はありません。
観測行列は、 。
状態方程式は、
x 遷移行列 、選択行列 はそれぞれ以下のように定義します。遷移行列は状態ベクトルの要素を時間シフトする作用を定義した行列になっています。


は、と同一です。
3. ARMAモデルの状態空間表現
ARMAモデルMA() を状態空間モデルで表現する場合、AR(自己回帰)部分とMA(移動平均)部分の両方を含む状態方程式と観測方程式を定義する必要があります。
ARMA()モデルをの定義式を再掲しておきます。
状態変数 は、過去の観測値と誤差項により構成される列ベクトルです。
状態方程式は、
遷移行列
成分と 成分をそれぞれ時間シフトする作用を定義した行列です。見やすくするために、上のq行と下のp行の場所に水平線を、左のq列と右のp列の場所に垂直線を入れて表します。


選択行列 は 次元の行列で最初の行以外はゼロです。
は、と同一です。
観測方程式は、現在の状態から観測値 を生成します。
は過去の観測値の係数で、AR部分を表します。
は過去の誤差項の係数で、MA部分を表します。
は白色雑音。
この式では、観測方程式の中で過去の観測値と過去の誤差項が重み付けられて合成され、現在の観測値 を生成します。
上述の他にもARIMA、SARIMAといったさらに複雑なモデルに対して状態空間を使った定式化が可能です。ただし式がかななり煩雑になってきますのでここでは同様の説明は省略し、のちほど5.3項で、サンプルコードを作って動作を具体的に見ていくことにします。
4. ARCHモデルの状態空間表現
ARCH()は、時系列データの条件付き分散が過去の誤差の2乗の関数として変動するモデルです。このモデルを状態空間の形式で記述します。
前提として、ARCH()モデルを次のように定義します。
ここで、
は観測データ。
は時点 での条件付き分散。
はARCHモデルのパラメータ。
状態変数 は、過去の誤差項の2乗の値を成分とする列ベクトルです。
x 遷移行列 は
観測行列 は、
観測方程式は、平方根を用いて形式的に以下のように定義します。
状態方程式の定義は以下です。
選択行列 は q-次の単位行列 です。
は、時刻 t での誤差項の二乗を成分とする列ベクトルです。
5. GARCHモデルの状態空間表現
GARCH()モデルは、ARCHモデルを拡張し、条件付き分散が過去の誤差項の2乗だけでなく、過去の条件付き分散も考慮するモデルです。GARCHモデルも状態空間モデルとして表現できます。
GARCH()モデルを次のように定義します。
は観測データ。
は時点 での条件付き分散。
は誤差の過去の影響を表すARCHパラメータ。
は過去の分散の影響を表すGARCHパラメータ。
は現在時点の観測データに影響を与える最も過去の誤差項のラグ数, は現在時点の観測データに影響を与える最も過去の条件付分散項のラグ数,
状態変数 は、過去の誤差の2乗と過去の条件付き分散の値から構成した列ベクトルです。


遷移行列
見やすくするために、上のq行と下のp行の場所に水平線を、左のq列と右のp列の場所に垂直線を、入れて表します。
観測行列
選択行列
は、時刻 t での誤差項の二乗と条件付分散を成分とする列ベクトルです。
状態方程式
観測方程式
ARCHの場合と同じ表記です。
5.2. パラメータの推定#
前項で定義した状態空間モデルについて、状態を予測するプロセスを説明します。
大きくいうと、まず観測データを入力として「フィルター」処理によって状態 を推定・更新します。この際に、さらに正確に状態を推定するため「平滑化」を行うことができます。次にこのステップで得られたパラメータセット() を最尤法により最適化します。そして最適なパラメータを用いて次の時点の状態を決定します。これらを逐次的に繰り返していくことで最適な予測を行うことができます。
以下、これらのプロセスについて補足していきます。
1. フィルター
フィルター(Filtering)は、時点 (t) までの観測データを使って、その時点での状態変数 (\alpha_t) の条件付き分布を推定し、更新する手続きです。これは「オンライン推定」とも呼ばれ、リアルタイムでデータが得られる環境下で、その時点での状態を最もよく推定することに焦点を当てています。カルマンフィルターが典型例で、線形ガウス状態空間モデルに基づき効率的なフィルタリングを行うことができます。
カルマンフィルターは以下の例が示すように様々な場面に応用されています。
工学・制御システム
-
航空機やロケットの位置・速度・加速度のリアルタイム追跡。
-
ロボットの動きやセンサーデータの統合による自己位置推定。
医療
-
心拍や脳波など、医療データのノイズ除去や平滑化。
-
患者の生体信号のリアルタイム解析。
経済・金融
-
経済指標の推定や予測(例: GDP 成長率のリアルタイム推定)。
-
株価や為替レートの予測・平滑化。市場のボラティリティやトレンドの推定にも使用されます。
例えば、株価の動的モデリング。株価データを状態空間モデルとしてモデル化する場合、カルマンフィルターを使って株価の「トレンド成分」や「周期成分」をリアルタイムに推定します。株価が外部要因(経済指標や金利)によって変動すると仮定したモデルで、フィルタリングにより実際の株価観測に基づきトレンドを更新し、最新の状態を推定します。5.3項では、カルマンフィルターを実装した statsmdoels の状態空間モデル(SARIMAX,UCM)のコード例を紹介します。
【カルマンフィルターの基本ステップ】
カルマンフィルタは、観測データを用いて、時点 での状態ベクトル を推定するための手法です。観測方程式と状態方程式に基づき、状態ベクトルの事後分布を更新します。
step 1. 初期化
- 初期状態の推定値 と初期誤差共分散行列 を設定します。
- 初期状態は事前に準備した適当なモデルにより推定したものを使うか、外部情報を用いて与えます。
step 2. 時間更新
を、時刻 までの観測情報 の下での時刻 の状態の期待値とします。これは言い換えると観測 が与えられる前の時点 で、 を事前推定した値です。
状態遷移方程式 及びに、 がホワイトノイズであることから、 であるため、
次に状態の 時点での予測誤差を と定義すると、この共分散行列 は、以下のように表わされることがわかります。
これは、 を 時点で事前推定した値です。感覚的に言えば、時点 での状態の不確実性が、時点 にどのように変化するかを推定したものです。
先の予測された状態の期待値から、予測誤差 は次のようになります。
従って、
混合項( など)は、 と が独立であり、 の期待値がゼロであるため消えます。
は であり、 は であるから、前述の共分散行列の予測式が導かれました。
step 3. 観測による状態の更新
観測 に基づいて事前推定を を適切に更新することを事後推定と呼びます。事後推定は以下のように事前推定値と、観測 とその予測 の差(観測誤差)から作られた推定式を「最適化」したものであると定義します。
この係数 をカルマンゲインと呼びます。カルマンフィルターの理論では、予測誤差の分散 を最小にする K を最適カルマンゲインと呼び、最適カルマンゲインに対して得られた推定式を事後推定と考えるものです。
Pの定義式から、
先の推定式から、
これを用いて、誤差共分散行列を展開します。
誤差共分散行列 を最小化する を求めるために、 を について微分し、その結果を 0 に設定します。
この式を について解くと次のようになります。
この最適カルマンゲインを使うことで事後推定 を得ます。
step 4. 繰り返し
時間更新と観測更新を繰り返し、時点 以降に進みます。
2. 平滑化
すべてのデータが得られた後に、過去の状態をより正確に推定するために用いられる手続きが「平滑化(Smoothing)」です。平滑化は、観測データ全体を用いて各時刻の状態推定を後処理することで、将来の情報を反映し、推定精度を高めます。カルマンフィルターが過去から現在へと順方向に推定を行う「前向き処理」であるのに対し、平滑化はフィルタリング後の情報を用いて、逆方向(後ろ向き)に処理を行う手続き、ということができます。
statsmodels の状態空間モデルでは、カルマンフィルターによる処理結果に対して、平滑化を行うことができます。
【平滑化の基本ステップ】
平滑化は、前段としてフィルタリングを行った結果に適用します。
step 1. フィルタリング
カルマンフィルターを用いて、時点 における状態 の事後推定値 と予測誤差の分散 を求められたとします。
ここで、 は(最適)カルマンゲインです。
step 2. 平滑化
過去にさかのぼって状態の推定を改善します。このために、 フィルタリング結果を元にして、平滑化状態 を求めます。遡及的に計算され、未来の情報を考慮した状態の更新、予測誤差共分散行列の更新を行います。
は平滑化ゲインと言います。
平滑化の結果、状態 の新しい推定値 は、全ての観測値 を考慮した推定値となります。
5.3. 予測を実践する#
この項では状態空間モデルを実際の金融・経済系データに適用した場合、どのような予測ができるのかを、サンプルコードを動かして見ていこうと思います。テーマは「トヨタ自動車の株価を米国・日本の主要金融・経済指標から予測する」です。なお以下の予測コードでは、企業業績や企業のファンダメンタル情報は直接の入力情報として使わないことを注記しておきます。
さて、ドル建て日経平均株価は、NYダウ株価指数に対して従属的に動く、という説があります(Financial Trend、2010年、第一生命発行)。現在でもこの説が通用するならば、日経平均株価を構成する主要銘柄であるトヨタ自動車の株価の値動きは、日経平均株価及びに米国の主要金融・経済指標からなんらか影響を受けると考えてよさそうです。ただし筆者は適切な指標選択に対する見識を有していませんのでここではアプリオリに以下を環境変数(外生変数)として設定することにします。
- 日経平均株価
- ドル円為替レート
- 米国国債長短金利スプレッド(10年物金利と2年物金利の差)
- 失業率(Unemployment Rate)
- 個人消費支出(Personal Consumption Expenditures,PCE)
statsmodelでは表現力の高い状態空間モデルとして未観測成分モデル(Unobserved Components Model,UCM )あるいはSARIMAXを利用することができます。これらは関数の呼び出しコード1行の相違以外コードを共通化できるので便利です。
以下に二種類のモデル化方法を簡単にまとめておきます。
未観測成分モデル(UCM)
以下は外生変数を考慮したUCMの観測方程式です。
は、時点 における外生変数のベクトルであり、 は外生変数に対する係数ベクトルです。
未観測成分モデルは、時系列データを観測できない成分の和として表します。
各成分は
: 観測された時系列データ
: トレンド成分。ランダムウォーク、ローカル線形トレンドなど、さまざまな形でモデル化できます。
: 季節成分。周期的に繰り返されるパターンであり、四半期や月などの頻度に応じて変動します。
: 循環成分。特定の周波数で振動する成分を表します。一般的には、減衰係数と周期を用いて定義します。
: 誤差項(ホワイトノイズ)
状態空間モデルの一般定義式に照らし合わせると、状態変数 は、上記のトレンド成分、季節成分、そして循環成分から構成されます。具体的な構成は着目する成分により異なってきます。ここでは割愛しますが詳細は statsmodels のドキュメント を参照ください。
SARIMAX(Seasonal ARIMA with eXogeneous regressors)
statsmodels の SARIMAX モデルは、状態空間モデルとして自己回帰(AR)、移動平均(MA)、季節性(S)、外生変数(X)を組み合わせたモデルを提供します。このモデルは、次のような一般的な構造を持っています。
SARIMAX()モデルは、次のように定義されます。
ここで、
は観測値。
はホワイトノイズ。
と は、通常の自己回帰および移動平均の多項式。
と は、季節性自己回帰および移動平均の多項式。
はバックシフト演算子()。
と はそれぞれ非季節性および季節性の差分次数。
は季節の周期。
は外生変数の行列で、 はその係数ベクトル。
以下にサンプルコードを記載します。
- データはインターネットからダウンロードできるものから選定しています。日次の株価、為替データはyahoo_finで取得、その他はpandas_datareaderを使っています。後者はデータソースとして米国連銀(FRED)のサイト を利用しています。このサイトはアカウント登録不要で、網羅的かつ使い勝手がよいのでお勧めです。
- 値の範囲が大きく異なるデータが混在する場合、学習に失敗しないようスケーリングを掛けることが常道ですが、このコードでは、変化率(株価でいえば収益率)に変換して関係性を調べています。
- テストデータは予測ウィンドウ期間(1か月)を定義して、各月ごとに1か月分の株価を予測します。外生変数有りの予測(赤いラインチャート)と、外生変数無しの予測(ピンクのラインチャート)を作成しています。
- 観測方程式の定義では時刻 T での観測データは同じ時刻 T での外生変数から影響を受けます。しかし株価に適用した場合、日付 T でのトヨタの株価が影響を受けるのは日付 T-1 以前の外生変数になりますので、全ての外生変数を一日分シフトしています。
# tsa_statespace_predi_return.py
# 状態空間モデルにより株価収益率を予測する
# Unobserved Components Model と SARIMAXを比較する
import pandas as pd
import numpy as np
from yahoo_fin import stock_info
import pandas_datareader.data as web
import statsmodels.api as sm
from statsmodels.tsa.statespace.sarimax import SARIMAX
import matplotlib.pyplot as plt
import japanize_matplotlib
import sys,warnings
import datetime
import matplotlib.dates as mdates
import warnings
from statsmodels.tools.sm_exceptions import ConvergenceWarning
# 特定の警告を無視
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=UserWarning) # ValueWarningはUserWarningに含まれます
warnings.filterwarnings("ignore", category=ConvergenceWarning)
def interporate_df(daily_df):
# 現在のデータの最新日付を取得
latest_date = daily_df.index[-1]
# 最新の日付の月の月末を取得
month_end = latest_date + pd.offsets.MonthEnd(0)
# 同じ月の月末までデータを補完
if latest_date < month_end:
extended_index = pd.date_range(start=latest_date + pd.Timedelta(days=1), end=month_end, freq='D')
last_value = daily_df.iloc[-1,0:1].values.flatten()[0]
extended_df = pd.DataFrame(last_value, index=extended_index,columns=daily_df.columns)
daily_df = pd.concat([daily_df, extended_df])
return daily_df
# 1. 期間を設定
start_date = '2020-01-01'
train_end = '2024-11-30'
test_start = '2024-02-01'
test_end = '2024-11-30'
end_date = '2024-12-31'
# 2. 株価データ(yahoo finnance usがソース)
symbols = ['7203.T','AAPL', 'MSFT', 'GOOG', 'AMZN', 'TSLA']
stock_price = stock_info.get_data(symbols[0], start_date=start_date, end_date=end_date)['close']
stock_returns = stock_price.pct_change().dropna()
# 3. 各ファクターのデータ取得(ドル円為替レート、失業率、個人消費、金利スプレッド、日経平均株価)
usd_jpy = stock_info.get_data("JPY=X", start_date=start_date, end_date=end_date)['close'].pct_change()
unrate = web.DataReader('UNRATE', 'fred', start_date, end_date).pct_change().dropna()
unrate = unrate.resample('D').ffill() # 月次データを日次データに補完(直前の値を保持)
unrate = interporate_df(unrate)
pce = web.DataReader('PCE', 'fred', start_date, end_date).pct_change().dropna()
pce = pce.resample('D').ffill() # 月次データを日次データに補完(直前の値を保持)
pce = interporate_df(pce)
gt10 = web.DataReader('DGS10', 'fred', start_date, end_date)
gt2 = web.DataReader('DGS2', 'fred', start_date, end_date)
yield_spread = pd.DataFrame(gt10.values - gt2.values, index=gt10.index, columns=['YieldSpread'])
nikkei = stock_info.get_data("^N225", start_date=start_date, end_date=end_date)['close'].pct_change()
# その他指標 適宜利用
#sp500 = web.DataReader('SP500', 'fred', start_date, end_date).pct_change().dropna().squeeze() # 1次元配列に変換
#nasdaq_composite = web.DataReader('NASDAQCOM', 'fred', start_date, end_date).pct_change().dropna().squeeze() # 1次元配列に変換
#cpi = web.get_data_fred('CPIAUCSL', start=start_date, end=end_date).resample('D').ffill()
print('unrate\n',unrate)
print('gt10\n',gt10)
print('gt2\n',gt2)
print('pce\n',pce)
# 4. すべてのデータのインデックスを揃える
common_index = nikkei.index.\
intersection(yield_spread.index).\
intersection(usd_jpy.index).\
intersection(pce.index).\
intersection(stock_returns.index).\
intersection(unrate.index)
# 各データを共通のインデックスに合わせる
nikkei = nikkei.loc[common_index]
usd_jpy = usd_jpy.loc[common_index]
yield_spread = yield_spread.loc[common_index]
pce = pce.loc[common_index]
unrate = unrate.loc[common_index]
stock_returns = stock_returns.loc[common_index]
# 5. 外生変数をまとめる
factors = pd.DataFrame({
'unrate': unrate.values.squeeze(), # 1次元配列に変換
'PCE': pce.values.squeeze(), # 1次元配列に変換
'YieldSpread': yield_spread['YieldSpread'].values.squeeze(), # 1次元配列に変換
'usdjp': usd_jpy.values.squeeze(), # 1次元配列に変換
'nikkei': nikkei.values.squeeze(), # 1次元配列に変換
}, index=nikkei.index).dropna() # インデックスを揃えて欠損値を除外
# 外生変数データを1日後ろにシフト(日本市場の株価予測のために前日の外生変数値を使用)
factors = factors.shift(1).dropna()
# 6. インデックスを揃える
common_index = stock_returns.index.intersection(factors.index)
# 両方のデータフレームを共通インデックスに基づいて再サンプリングまたはフィルタリング
stock_returns = stock_returns.loc[common_index]
factors = factors.loc[common_index]
print('factors',factors)
print("stock_returns",stock_returns)
#print("stock_returns.index",stock_returns.index)
#print("factors.index",factors.index)
# 7. データを学習用とテスト用に分割する
# 目的変数
y_train_data = stock_returns[:train_end]
y_test_data = stock_returns[test_start:test_end]
# 説明変数
X_train_data = factors[:train_end]
X_test_data = factors[test_start:test_end]
# 予測ウィンドウサイズ(1か月、22営業日と想定)
window_size = 22
# テストウィンドウ期間のインデックス
test_start_date = y_test_data.index[0]
test_end_date = y_test_data.index[-1]
# ウィンドウの開始日リストを生成
window_starts = pd.date_range(start=test_start_date, end=test_end_date - pd.Timedelta(days=window_size), freq='22B')
# プロット用の設定
num_windows = len(window_starts)
fig, axes = plt.subplots(nrows=(num_windows+1) // 2, ncols=2, figsize=(14, 4 * (num_windows/2+1)))
print(window_starts)
#print(y_train_data)
#print(X_train_data)
date_format = mdates.DateFormatter('%y-%m')
for i, test_window_start in enumerate(window_starts):
test_window_end = test_window_start + pd.Timedelta(days=window_size)
# 各ウィンドウ内のデータを抽出
y_train_data_window = y_train_data[:test_window_start]
X_train_data_window = X_train_data[:test_window_start]
y_test_data_window = y_test_data[test_window_start:test_window_end]
X_test_data_window = X_test_data[test_window_start:test_window_end]
#print('y_test_data_window.index\n',y_test_data_window.index)
#print('X_test_data_window.index\n',X_test_data_window.index)
# 8. 外生データを使用するモデル
# モデル定義と学習
#model = sm.tsa.UnobservedComponents(y_train_data_window, exog=X_train_data_window, level='local linear trend', seasonal=12)
model = SARIMAX(y_train_data_window, exog=X_train_data_window, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
result = model.fit(disp=False)
# 学習期間最終株価
train_last_price = stock_price[:test_window_start][-1]
#print(stock_price[:train_end].tail())
print(train_last_price)
# テスト期間の予測(1か月分の株価収益率を予測する)
forecast = result.get_forecast(steps=len(y_test_data_window), exog=X_test_data_window)
forecast_mean = forecast.predicted_mean
#forecast_ci = forecast.conf_int() # 信頼区間の取得
forecast_price = train_last_price * (1 + forecast_mean).cumprod()
# 予測結果に日付インデックスを追加
forecast_price.index = y_test_data_window.index
print(forecast_price)
# 9. 外生データを使用しないモデル
# モデル定義と学習
#no_exog_model = sm.tsa.UnobservedComponents(y_train_data_window, level="local linear trend", seasonal=12)
no_exog_model = SARIMAX(y_train_data_window, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
no_exog_result = no_exog_model.fit(disp=False)
# テスト期間の予測(1か月分の株価収益率を予測する)
forecast_without_exog = no_exog_result.get_forecast(steps=len(y_test_data_window))
forecast_without_exog_mean = forecast_without_exog.predicted_mean
forecast_price_without_exog = train_last_price * (1 + forecast_without_exog_mean).cumprod()
# 予測結果に日付インデックスを追加
forecast_price_without_exog.index = y_test_data_window.index
print(forecast_price_without_exog)
# 10. サブプロットに描画
ax = axes[i // 2][i % 2]
ax.plot(stock_price.loc[:train_end], label='株価実績値(学習期間)', color='green')
ax.plot(stock_price.loc[test_start:], label='株価実績値(テスト期間)', color='blue')
ax.plot(forecast_price.index, forecast_price, label='株価予測値(外生変数あり)', color='red')
ax.plot(forecast_price_without_exog.index, forecast_price_without_exog, label='株価予測値(外生変数なし)', color='pink')
##ax.set_title(f"Window from {start_date.date()} to {end_date.date()}")
ax.xaxis.set_major_formatter(date_format)
ax.set_xlim(pd.to_datetime('2024-01-01'), pd.to_datetime('2024-11-30'))
#ax.set_ylim(200,4300)
ax.grid(True)
ax.legend()
# パラメータ推定結果の表示
#print(result.summary())
plt.tight_layout()
plt.show()
コードを実行すると以下のチャートが表示されます。
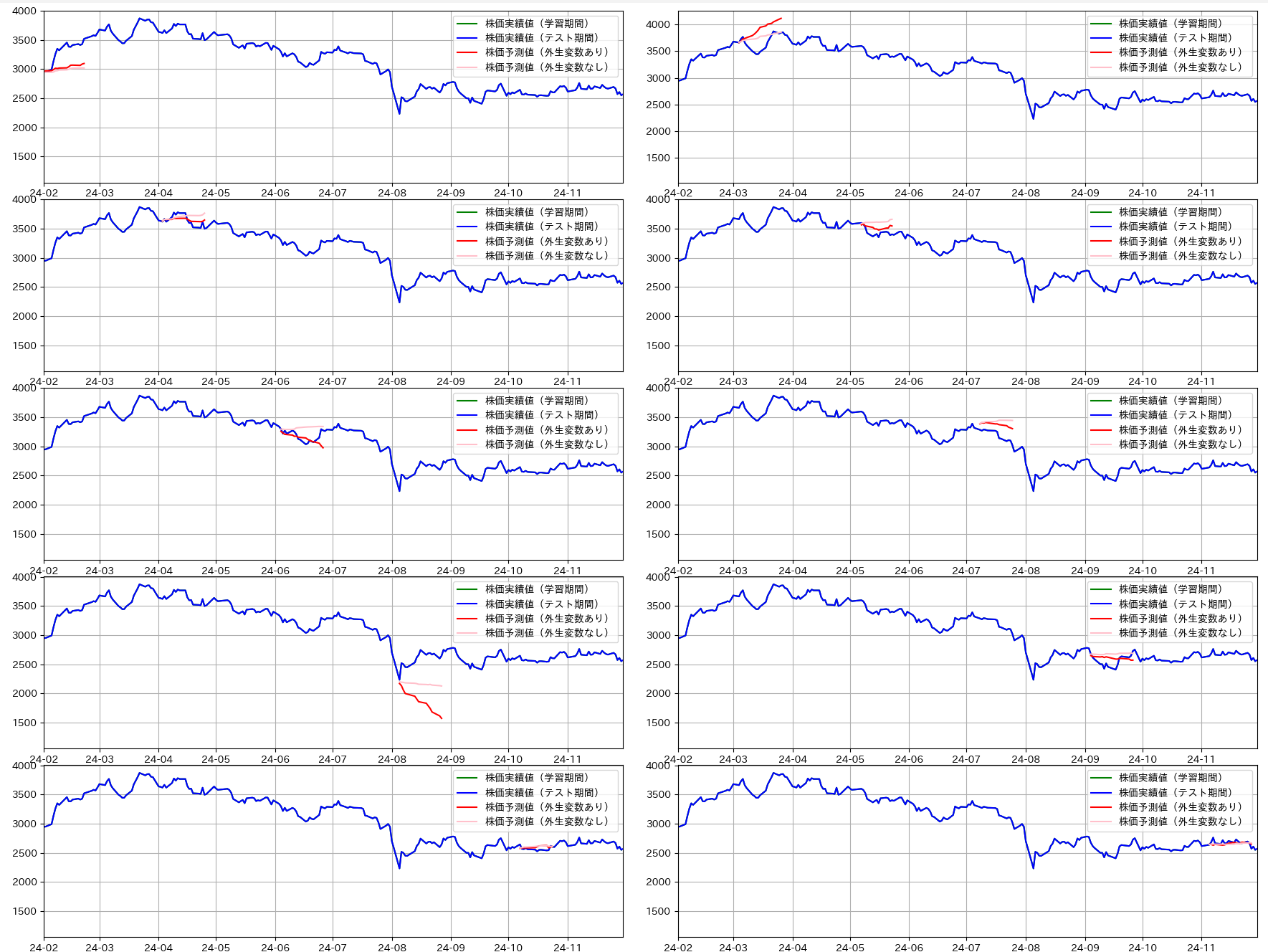
チャートの予測値をみてどう思われるでしょうか? 4,5,6,7,10,11月は実績値と割と近い動きをしているように見えます。これに対して2,3,8,9月の乖離が大きいです。これは以下のように株価に影響を与える明白な材料(ショック要因)があったことによると考えられます。
2月の実績値上昇の背景:2月6日の同社2024年3月期決算が大幅な増収増益の発表があり株価は急上昇しました。 3月の実績値下落の背景:3月8日発表の米雇用統計の結果FRBによる早期の利下げ観測により円高・ドル安が進んだ結果自動車株はのきなみ下落しました(参考:日経QUICKニュース )。 8月の実績値上昇の背景:これは8月2~5日発生の日経平均株価大暴落の反動での急上昇です。9月の下落は、相場全体の地合悪化のなかで自動車株が全面安、との見立てがあります(参考:日本経済新聞)。
回帰(AR)やMA(移動平均)は、過去の平均的な挙動を統合して予測を行いますので、雇用や物価のようにマクロ的な数値として積み上げられた指標の分析に適していると思います。一方、株価は、不随意に発生する環境要因や、多数のトレーダーの「読み・思惑」といった要因に強く影響されます。過去データとして振り返って見てみれば、このコードの時系列処理手法はそれなりに悪くない予測をしているように思えます。しかし、ショックはいつ発生するのかわかりませんので、時系列分析をベースにして株価を予測して実際の取引を行うのは相当リスクがあると感じます。