第3章 回帰モデルを正しく使う#
はじめに#
回帰分析をテーマにした議論や資料を読むと、モデルが適正に構成されていることの検証に非常に注意が注がれていることがわかります。本章では回帰モデルがみたすべき前提条件を確認する手法にフォーカスして線形回帰モデルの基本的な知識を整理していきます。 誤った前提からはどんな結論をも導き出すことができる、という論理学の良く知られた教訓を自ら実践しないようにしたいものです.
本章ではまず本論に入る前に回帰分析に関わる表記の揺れを減らしたいために、頻出する用語を記載することにしました。第 1 節は本稿で扱う回帰モデルの定義を明らかにしています。第2章から第7章までは、回帰モデルを正しく運用するための主要な前提条件をどうやって確認していくのか、サンプルコードを交え解説していきます。
線形回帰モデルをベースとした最小二乗法推定はもっとも汎用的でポピュラーな推定方法ですが、第 8 節では古典的な線形回帰モデルから少し離れた確率分布や推定方法を利用することで、より広範な事象を扱う技法について補足します。
基本的な用語#
目的変数(Y): 説明したい現象や結果を表す変数。目的変数、応答変数とも呼ばれます。
説明変数(X): 目的変数に影響を与えると仮定される変数であり、目的変数を結果とすれば説明変数は原因にあたります。予測変数とも呼ばれます。
回帰モデル: 目的変数と説明変数の関係を数学的に表現したもの。説明変数がひとつの場合単回帰モデルとよび、以下のように表します:
ここで、Y は目的変数、X は説明変数、 は切片、 は回帰係数、 は誤差項。 説明変数と目的変数の観測データにもっとよくあてはまるパラメータを求める作業を「目的変数 Y を説明変数 X に回帰する」と言い表します。
回帰係数( regression coefficient ): この係数は、説明変数 X が目的変数 Y にどの程度の影響を与えるかを示すものです。
残差(Residuals): 回帰モデルによる予測値(推定値)と実測値(観測値)との差を指します。すなわち観測値のペアを、観測値に対する予測値を、としたとき残差は です。したがって標本(つまり観測値の系列)ごとに残差の系列は異なったものになります。
誤差項(Error Term):目的変数の真の値と観測値との差を生じさせる予測できないノイズや要因を意味します。「撹乱項」ともいい、回帰モデルにおいてこの項は確率変数として扱われます。
説明変数が複数の場合は以下のように表現される重回帰モデルを使います。nを標本サイズとして
の項も便宜的に変数が掛かっているものと考えれば重回帰モデルはベクトルと行列を用いて簡潔に表現することができます。補足説明 にベクトル・行列の基本事項をまとめていますので適宜参照ください。
さて、 を n 次元の列ベクトル、 を全ての要素が 1 の列ベクトル、 を説明変数のn次元列ベクトルとすれば
さらに区分行列の記法を使うことで、以下のようにシンプルな形式で表現することができます。
ここで、 としました。


1. 古典的線形回帰モデル#
1.1. モデルの定義#
まず以下の条件を満たすいわゆる「古典的線形回帰モデル」を取り扱うことにします(以降、簡単に回帰モデルと略す)。たくさんの前提条件があり、モデルを組み立てる作業の面倒さを伺わせます。しかし例えば経済事象の時系列のように、各時点で得られる標本サイズが小さいモデルであっても、これらの前提条件が満たされているならば、時間をかけて収集した観測データを標本として取り扱うことができます。そう考えてみると前提条件の多さにも納得感はあります。参考6(「経済の時系列分析」 山本拓(著) 創文社)の第2章冒頭にはこの辺りの説明が明快に記述されており参考になります。
-
係数の有意性
分析のそもそもの前提として、採用した説明変数が目的変数に対してほんとうに影響を及ぼしているかどうかを確認する必要があります。これを回帰係数の有意性を確認することでもあります。 -
予測式の線形性
目的変数は非確率変数の説明変数と確率変数の誤差項との線形結合で表されることを確認します。 -
誤差項の正規性
全ての観測点で正規分布に従う独立確率変数である、すなわち期待値は観測点に依存しない定数であることを要請します。回帰モデルは定数項を含めることができるので期待値は簡単のためゼロとおきます。 -
誤差項の等分散性
誤差項の分散は説明変数に依存しない、つまり説明変数の値範囲全体で誤差項の分散が定数であることを要請します。この性質がある場合統計的推定と予測が安定し結果が信頼性あるものとなります。この仮定を(ホモスケダスティシティ、homoscedasticity)と呼称します。回帰モデルの適切性を評価するために重要な性質です。 -
誤差項の自己無相関性
誤差項は自己相関を持たないことを要請します。言い換えると -
重回帰モデルにおける説明変数の独立性
説明変数同士が高い多重共線性(Multicollinearity)を持たないことが望ましいとされています。多重共線性があると、係数の推定が不安定になる可能性があるためです。
想定する回帰モデルが6項目の前提条件を満たすのかどうか。もちろん自明でない限り確認が必要となります。条件を満たさなければ別のモデルを考えるとかアプローチを変えなければならないでしょう。 続く節ではこれら諸前提が、対象とするモデルに対して充足されているのかどうかを確認する手法を見ていきましょう。
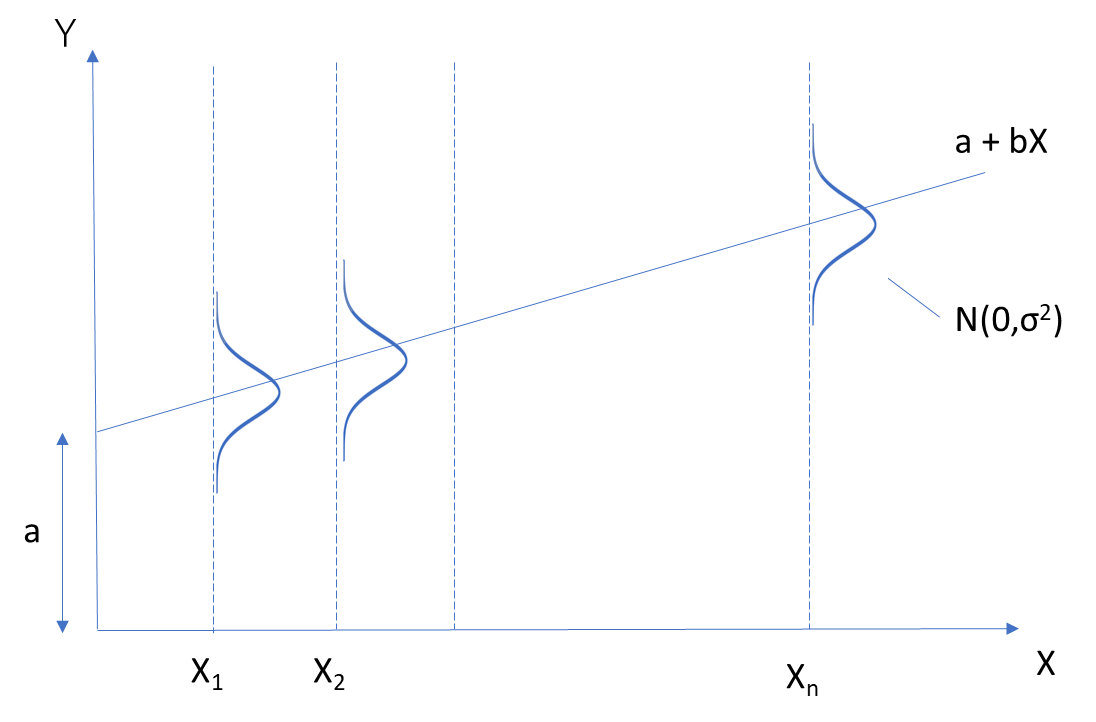
古典的回帰モデルの誤差項のイメージ
1.2. 係数の最小二乗法推定#
回帰モデルの目的は観測値がうまく当てはまるモデルを構築することにあります。これは言い換えるとモデルに現れるパラメータ(回帰係数と切片)を推定する作業です。
第 2 章 2 節で言及した最小二乗法(OLS)、最尤法(MLE)、ベイズ推定は回帰係数の推定方法として良く使われる手法です。そのなかでも最小二乗法は最も基本的で応用先の広い手法です。数学的にはガウス-マルコフの定理によって、線形回帰モデルにおいて最小二乗推定量(OLS)が最良線形不偏推定量(BLUE)であることを保証されています(補足説明 確率・統計)。実際、古典的線形回帰モデルはガウス-マルコフの仮定(線形性、誤差の期待値0、等分散性、誤差の非共分散性)を満たしますので、最古典的線形回帰モデルでは最小二乗推定が最も効率的な推定方法となっています。
この項では最小二乗法推定を題材にして係数推定の考え方の理解を進めたいと思います。
金融・経済系で扱われる複雑な挙動示すデータでは最小二乗法以外の推定方法、正規分布以外の確率分布が必要となってきますのでそれらについては本章 8 節以降で改めて言及します。
以後多変数の場合も含めて作業の見通しを良くしたいときにはベクトル代数を適宜活用することにします。
Y,e をそれぞれ標本サイズ n の目的変数、誤差項からなる n 次元列ベクトルとしましょう。 b を k 個の回帰係数からなる k 次元列ベクトル、 を k 個 n 点の説明変数からなる n 行 k 列の行列とします。このとき重回帰モデルのベクトル表記は以下のようになります。
の n 点の観測データと の 点の観測データにもっとも良くあてはまるパラメータ b を推定することを目標とします。
観測データに基づく Y の推定値を と書いたとき、残差 の二乗和 を最小化する b を推定値とする方法を最小二乗推定法(Ordinary Least Square estimation,OLS推定)とよびます。
正規方程式
行列・ベクトル算法(参考 補足説明 ベクトル・行列)をつかって残差二乗和の最小値を求めます。
上記の最後に現れた表現を正規方程式と呼びます。この等式から、 が正則、すなわち逆行列が存在するならば、b について解くことができ、解 が最小二乗推定値となります。
を計算するためには 、 の逆行列を計算する必要があります。
単回帰モデルでは b は2次元ですから逆行列の公式を使うことで即計算できます。 は全ての要素が1の列ベクトル でしたから、区分行列の記法を使い、、 と書きますと、
また、
上記の結果を先の の式に代入し少し式変形することで切片と回帰係数の推定 , を得ることができます。
最小二乗推定を幾何学的にとらえてみる
の 番目要素の説明変数 が 空間を張る第 軸の上にあり、目的変数 は に直交する 軸上にあるとします。すると二次元で描いた下図からわかるように残差ベクトルの二乗和は残差ベクトルと説明変数ベクトルが直交するときに最小になります。別の見方では、 空間への射影演算子を 、恒等演算子を と書くことにすれば、 の 空間への射影 に対して、 が最小の残差ベクトル となります。
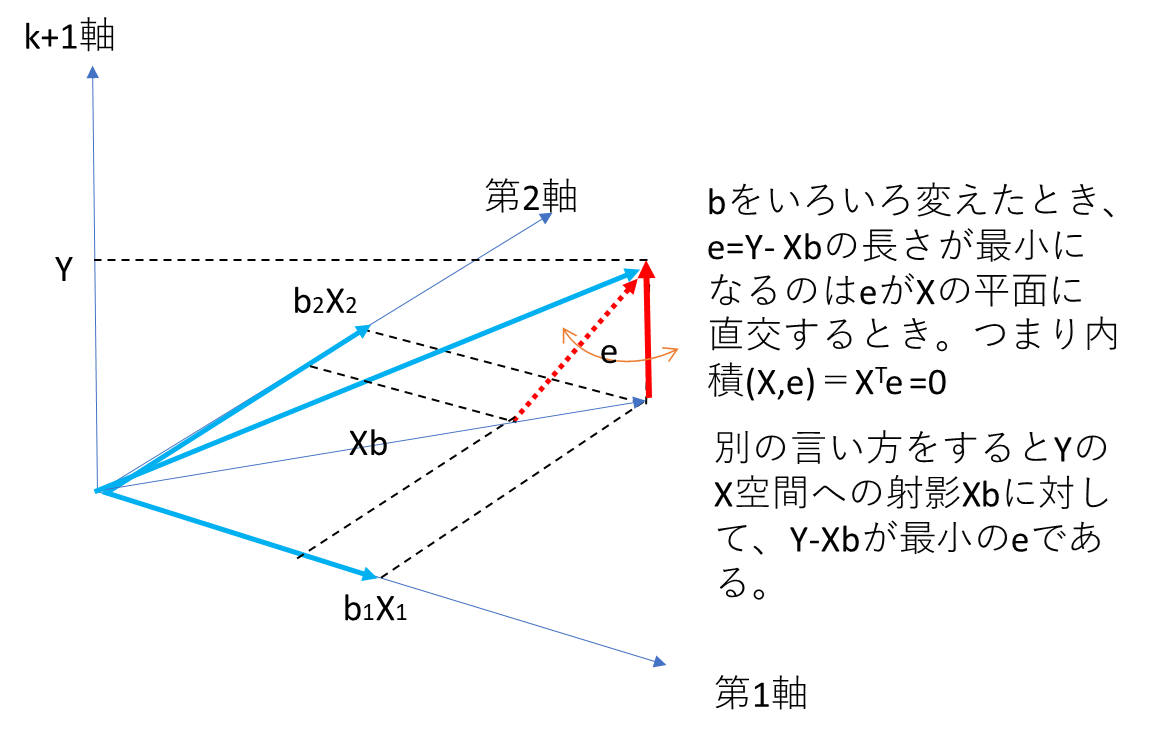
この図から、線形回帰モデルのベクトル表現 において、最小二乗推定の幾何学的なとらえ方は、目的変数 を説明変数の空間に直交射影する操作と見ることができます。このとき、射影された結果が であり、残差 はその空間に直交する成分を表します。
まとめると、射影演算子 により、最小二乗推定された予測値 は次のように表されます:
また、このときの残差 は恒等演算子 を用いて次の式で表せます。
最小二乗推定を幾何学的に理解する視点は、ここで言及した単回帰モデルにとどまらず重回帰モデルに対応する線形方程式の解の性質を理解するためにも有用です。補足説明 ベクトル・行列に、逆行列を拡張したペンローズ・ムーアの疑似逆行列という概念を導入することで、一般的な線形方程式の解の分類を幾何学的に見通しよく理解するアイデアについて補足しています。
手計算で係数の最小推定値を求めるのは大変なので通常は統計解析ソフトウェアが用意する係数推定用の関数を利用することになります。ソフトウェアを使うことで以下のように簡単に結果を求めることができます。
import numpy as np
import statsmodels.api as sm
# 標本データの生成
np.random.seed(0)
X = np.random.rand(100, 1)
X = sm.add_constant(X) # 定数項を追加
Y = 2 * X[:, 1] + np.random.randn(100) * 0.5
# 回帰モデルのフィッティング
model = sm.OLS(Y, X).fit()
# 回帰係数の表示
print(model.params)
推定に関して、一般的に使われる用語がありますので以下にまとめておきます。文献や資料によっては呼称が微妙に異なる場合がありますので、その場合は適宜読み替えてください。
- 偏差積和 (Sum of Products of Deviations,SPD)
説明変数の偏差()と目的変数の偏差()を積和した量です。
- 偏差二乗和 (Sum of Squared Deviation,SSD)
説明変数の偏差()の二乗和、あるいは目的変数の偏差()の二乗和です。後者はあるいは総変動 (Total Sum of Squares,TSS)と呼ばれます。
- 残差二乗和 (Residual Sum of Squares,RSS)
目的変数の残差()の二乗和です。
- 説明二乗和、モデル二乗和、回帰二乗和 (Explained Sum of Squares,ESS)
総変動 TSS を式変形すると、以下のように残差二乗和とそれ以外の項目の和で表すことができます。
前者のRSSは説明変数によって説明できない変動を示すものです。すると後者は説明変数によって説明できる変動を示す量と考えることができます。その意味で後者は説明二乗和と名づけられています。
少し式変形すると、
つまり ESS=0であることと、回帰係数 b = 0 であることは同値です。
- 決定係数 (Coefficient of Determination)
総変動に占める説明二乗和の比率を決定係数と呼びます。 と表記します。
この定義からわかるように、最小値 は、説明変数 が総変動に全く寄与していないことを示しています。また、最大値 は残差がゼロであること、総変動は だけで説明できることを示しています。
それでは以下の節より、古典的モデルが前提とする各種条件を具体的に確認する手法を見ていきましょう。
2. 係数の有意性の確認#
係数の有意性を確認するために、係数がゼロであるのかどうかを判定するために統計的推定を行います。係数がゼロでないと推定できるのであれば説明変数は有意であると判断できます。 この課題を帰無仮説として表現しましょう。 k-変数の回帰モデルを としたとき、回帰係数 に対して、
帰無仮説 (H0): 回帰係数 である
対立仮説 (H1): 回帰係数 である
2.1. T 検定による確認#
この仮説を検定するためによく用いられるのが 第 2 章 2 節で紹介した T 検定です。T 検定は、実際によくある標本数が小さい、あるいは母分散が不明であるような事象を扱うことができるので有用です。
係数の推定値 から以下の検定統計量を定義します。
ここで分母の は残差平方和を使って定義される以下の標本標準誤差です。


p値の計算
計算された t 統計量を使って、対応する p 値を計算します。p 値は t 分布の累積分布関数を用いて求められます。上記の右辺の式に現れる(標本サイズ - 係数の数)は、残差の自由度と呼び、モデルの性質を特徴づける重要な指標となっています。自由度が小さければ標本標準誤差SEの値が増え、モデルが過剰にデータにフィットする傾向が強まります。
有意水準と比較
p値を事前に設定した有意水準(例えば、0.05)と比較します。p値が有意水準より小さい場合、帰無仮説を棄却し、係数は統計的に有意であると結論します。
以下サンプルコードでは statsmodels の OLS 関数による推定結果をレポートします。結果レポートには標準的に回帰係数の有意性を確認できるT統計量、p 値が表示されています。
# reg_test_t.py
# 回帰係数の有意性を検定する
#
import numpy as np
import statsmodels.api as sm
# 標本の生成
np.random.seed(0)
X = np.random.randn(100, 1) # 説明変数
beta = 1.5 # 真の係数
y = X.flatten() * beta + np.random.randn(100) * 0.5 # 応答変数
# 定数項の追加
X = sm.add_constant(X)
# 回帰モデルの適合
model = sm.OLS(y, X)
results = model.fit()
# レポートの表示。回帰係数の有意性はレポート中に各回帰係数ごとに表示される
# T検定量、p値を確認すればよい。
print(results.summary())
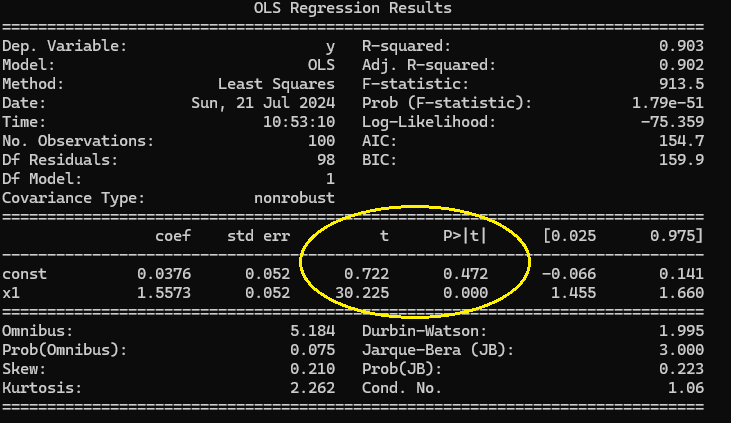
レポートの図中丸で囲った右側( p > |t| )が定数項、係数のp値を示していますので、この結果から係数は有意であり、定数項が有意でないと判定できます。
3. モデルの線形性の確認#
古典的モデルでは、そもそも観測データが従うモデルとして線形予測式を仮定したわけですが、これが正しいのかどうかは確認が必要です。
3.1. RESET検定による確認#
Ramsey の RESET 検定(Regression Specification Error Test)は、線形回帰モデルが適切に指定されているかを検証するための手法です。モデルの仕様の正しさを検証するための検定を仕様検定(Specification test)と呼ぶことがありますので、これは直語的に訳すならば「回帰モデルの仕様誤り検定」ということになります。この検定では、元のモデルに対して非線形の項(例えば、予測値の2乗や3乗など)を追加し、これらの追加項が有意であるかどうかを調べます。
有意性の判定のためには F 統計量を定義します。F 統計量は 2 種類のモデルの分散の比を計算することで、モデル全体の有意性や特定の効果の有意性を評価するために有効な統計量です。 以下に、RESET 検定におけるF統計量の定義を示します。
元の回帰モデルを次のように定義します。
ここで、 は非説明変数、 は説明変数の行列、 は回帰係数のベクトル、 は誤差項です。
元のモデルに予測値の非線形な項を追加した拡張モデルを次のように定義します。
ここで、 は予測値の 2 乗、3 乗などの非線形な項を含む行列、 はこれらの項に対応する回帰係数のベクトルです。元のモデルから得られる残差平方和を とし、拡張モデルから得られる残差平方和を とします。
上記の前提のもとで、F 統計量は以下として定義されます。
ここで、 は追加された非線形項の数、 は元のモデルのパラメータ数、 は標本サイズです。
非線形な追加項の有意性を判断するための帰無仮説は、以下となります。
帰無仮説
帰無仮説(H0): 追加された係数項ベクトル はゼロである
対立仮説(H1): 追加された係数項ベクトル はゼロではない
statsmodels にはこの検定を行うための関数が用意されています。以下にテストデータを作って、検定を実行するコードを示します。
# reg_test_ramsey_reset.py
# 回帰モデルの線形性をRamseyのRESET検定で検証する。
#
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.stats.diagnostic as smd
import matplotlib.pyplot as plt
import japanize_matplotlib
# 標本を生成する
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 3 * X + np.random.normal(0, 1, 100) # Linear relationship with noise
# データフレームをつくる
data = pd.DataFrame({'X': X, 'y': y})
# モデルに定数項(切片項)を追加する
X = sm.add_constant(data['X'])
# 線形回帰モデルに適合させる
model = sm.OLS(data['y'], X).fit()
print(model.summary())
# 2乗から4乗までのRESET検定を実行する
# use_f=False カイ二乗検定を利用 use_f=True F検定を利用
reset_test_power2 = smd.linear_reset(model, power=2, use_f=True)
print('RESET 検定 (乗数=2):', reset_test_power2)
reset_test_power3 = smd.linear_reset(model, power=3, use_f=True)
print('RESET 検定 (乗数=3):', reset_test_power3)
reset_test_power4 = smd.linear_reset(model, power=4, use_f=True)
print('RESET 検定 (乗数=4):', reset_test_power4)
# 説明変数と応答変数w抽出する
y = model.model.endog
X = model.model.exog
predictor = 'X'
# 予測値を求める
y_pred = model.fittedvalues
# 線形成分を除いた残差を求める
res = y - y_pred + model.params[predictor] * X[:, model.model.exog_names.index(predictor)]
# 線形成分と、線形成分を除いた残差の散布図をつくる
plt.figure(figsize=(8, 6))
plt.scatter(X[:, model.model.exog_names.index(predictor)], res, alpha=0.5)
plt.plot(X[:, model.model.exog_names.index(predictor)], model.params[predictor] * X[:, model.model.exog_names.index(predictor)], color='red')
plt.xlabel('説明変数 %s' %(predictor))
plt.ylabel('線形成分を除いた残差')
plt.title('線形成分を除いた残差のプロット')
plt.show()
# statsmodelsのプロット関数を使って同様の散布図を描くことができる
#from statsmodels.graphics.regressionplots import plot_ccpr
#fig, ax = plt.subplots(figsize=(8, 6))
#plot_ccpr(model, 'X', ax=ax)
#plt.title('線形成分を除いた残差のプロット')
#plt.show()
実行結果は以下の通りです。どの乗数でも p 値 > 0.05 であり帰無仮説は棄却できません。従って予測モデルは線形であると判断します。

説明が冗長になりますが、検定ロジックの仕組みを理解するために、自前で F 統計量を構築し検定するコードを書いてみましょう。
# reg_test_ramsey_reset.py
# 回帰モデルの線形性をRamseyのRESET検定で検証する。
# F統計量を定義するコードをつくる
#
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.stats.diagnostic as smd
import matplotlib.pyplot as plt
import japanize_matplotlib
import scipy.stats as stats
def linear_reset(model,power=None,use_f=True):
# オリジナルモデルの説明変数
X = model.model.exog
# オリジナルモデルの決定係数
RSS_0 = np.sum(model.resid**2)
# 拡張モデルのために予測値のpower-乗を追加
y_hat = model.fittedvalues
if power == 2:
X_ext = np.column_stack([X, y_hat**power])
elif power == 3:
X_ext = np.column_stack([X, y_hat**(power-1), y_hat**power])
elif power == 4:
X_ext = np.column_stack([X, y_hat**(power-2), y_hat**(power-1), y_hat**power])
# 拡張モデルを適合
model_1 = sm.OLS(y, X_ext).fit()
RSS_1 = np.sum(model_1.resid**2)
# F統計量の定義
q = power- 1 # 追加された非線形項の数
k = X.shape[1] - 1 # 元のモデルのパラメータ数(定数項を含む)
n = X.shape[0] # 標本サイズ
F = ((RSS_0 - RSS_1) / q) / (RSS_1 / (n - k - q))
# F統計量の臨界値
df1 = power - 1 # 分子自由度(追加した説明変数の数)
df2 = n # 分母自由度(標本サイズ)
alpha = 0.05 # 有意水準
# 臨界値の計算
critical_value = stats.f.ppf(1 - alpha, df1, df2)
# 帰無仮説検証
if F > critical_value:
print(f"RESET検定 (乗数={power}): 帰無仮説は棄却される. F={F} critical_value={critical_value}")
else:
print(f"RESET検定 (乗数={power}): 帰無仮説は棄却されない. F={F} critical_value={critical_value}")
return F
# 標本を生成する
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 3 * X + np.random.normal(0, 1, 100) # Linear relationship with noise
# データフレームをつくる
data = pd.DataFrame({'X': X, 'y': y})
# モデルに定数項(切片項)を追加する
X = sm.add_constant(data['X'])
# 線形回帰モデルに適合させる
model = sm.OLS(data['y'], X).fit()
print(model.summary())
# 2乗から4乗までのRESET検定を実行する
# use_f=False カイ二乗検定を利用 use_f=True F検定を利用
reset_test = linear_reset(model, power=2, use_f=True)
reset_test_power3 = linear_reset(model, power=3, use_f=True)
reset_test_power4 = linear_reset(model, power=4, use_f=True)
# 説明変数と応答変数w抽出する
y = model.model.endog
X = model.model.exog
predictor = 'X'
# 予測値を求める
y_pred = model.fittedvalues
# 線形成分を除いた残差を求める
res = y - y_pred + model.params[predictor] * X[:, model.model.exog_names.index(predictor)]
# 線形成分と、線形成分を除いた残差の散布図をつくる
plt.figure(figsize=(8, 6))
plt.scatter(X[:, model.model.exog_names.index(predictor)], res, alpha=0.5)
plt.plot(X[:, model.model.exog_names.index(predictor)], model.params[predictor] * X[:, model.model.exog_names.index(predictor)], color='red')
plt.xlabel('説明変数 %s' %(predictor))
plt.ylabel('線形成分を除いた残差')
plt.title('線形成分を除いた残差のプロット')
plt.show()
実行結果は以下の通りです。どの乗数でも p 値 > 0.05 であり帰無仮説は棄却できません。従って予測モデルは線形であると判断します。

4. 誤差項の正規性の確認#
4.1. 残差プロットを確認#
残差の散布図、残差のヒストグラム、残差の QQ プロットを描画し目視で誤差項の特徴を把握することができます。
以下に比較のため、誤差項が正規分布に従う場合と従わない場合のコードとプロット結果を紹介します。
QQプロットとは
Q-Q (分位数-分位数) プロットは、指定したデータセットが特定の理論的分布(典型的には正規分布)に従っているかどうかを評価するためのツールです。理論的分布の分位数を横軸に、残差の分布の分位数を縦軸とした散布図を描きます。「補足説明 分位数」に分位数の定義を含めて基本事項をまとめておきました。
誤差項が正規分布に従う場合のサンプルコードとプロット
# reg_plot_qq_ok.py
# 正規分布に従うノイズを持つ場合の残差プロットを描く
#
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from scipy.stats import norm
import japanize_matplotlib
# 標本データ生成
np.random.seed(0)
X = np.random.rand(200)
# 正規分布に従うノイズを追加
y = 2 * X + 1 + np.random.normal(0, 0.2, 200)
# 回帰モデルの適合を行い残差を取得する
X = sm.add_constant(X) # 定数項を追加
model = sm.OLS(y, X).fit()
residuals = model.resid # 残差を取得
# グラフ作成のためのフィギュアを定義
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 残差プロット
axes[0, 0].scatter(model.fittedvalues, residuals, c='b', marker='o', edgecolor='b')
axes[0, 0].set_xlabel('予測値 (Fitted Values)')
axes[0, 0].set_ylabel('残差 (Residuals)')
axes[0, 0].axhline(y=0, color='r', linestyle='--')
axes[0, 0].set_title('残差プロット (Residual Plot)')
# 残差ヒストグラム
axes[0, 1].hist(residuals, bins=20, color='blue', alpha=0.7)
axes[0, 1].set_xlabel('残差 (Residuals)')
axes[0, 1].set_ylabel('頻度 (Frequency)')
axes[0, 1].set_title('残差ヒストグラム')
# QQプロット
sm.qqplot(residuals, line='s', ax=axes[1, 0])
axes[1, 0].set_title('QQプロット')
axes[1, 0].set_xlabel('理論分位数')
axes[1, 0].set_ylabel('標本分位数')
# ノイズプロット
# 正規分布のパラメータ
a = 0
b = 0.2
# プロット範囲
x = np.linspace(norm.ppf(0.01),norm.ppf(0.99), 200)
# 正規分布の確率密度関数 (PDF) のプロット
pdf = norm.pdf(x, loc=a, scale=b)
axes[1, 1].plot(x, pdf, 'r-', lw=2)
axes[1, 1].set_xlabel('x(1%->99%)')
axes[1, 1].set_ylabel('確率密度')
axes[1, 1].set_title('ノイズ(正規分布)')
plt.tight_layout()
plt.show()
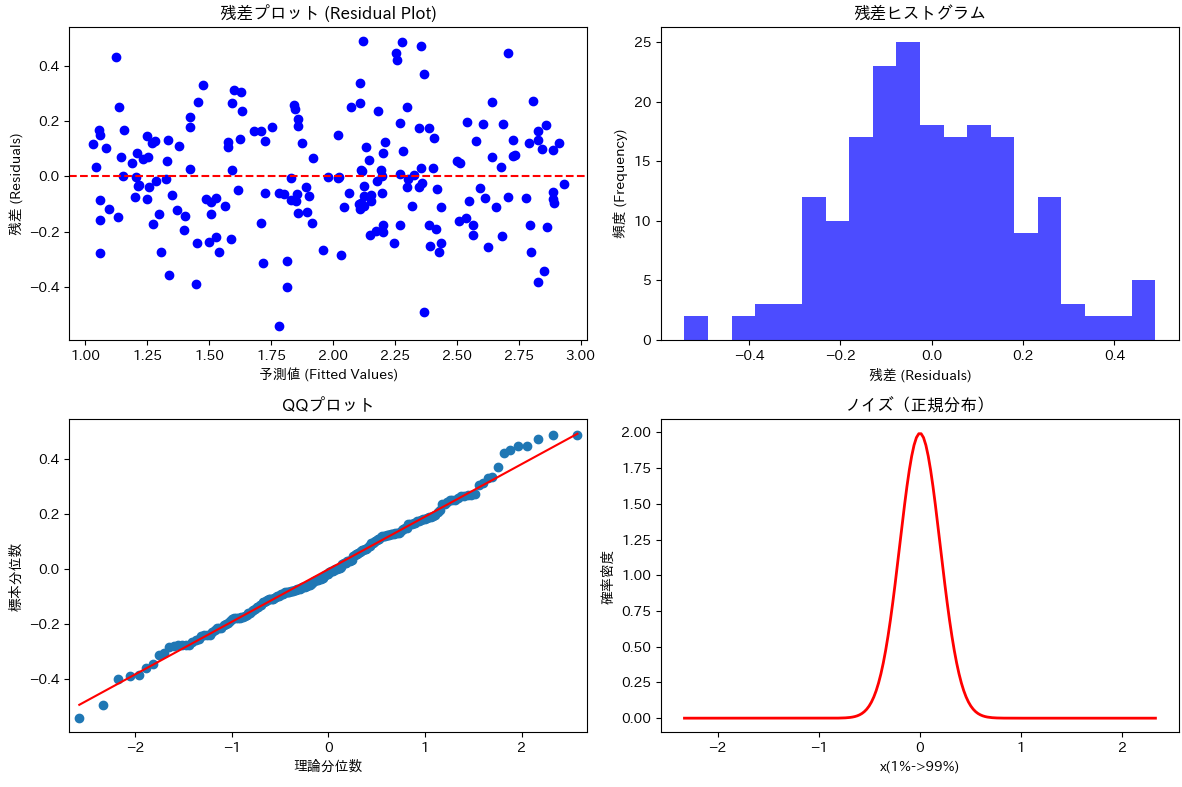
誤差項が正規分布に従わない場合のサンプルコードとプロット
# reg_plot_qq_ng.py
# 正規性を満たさない分布に従う誤差項を持つ場合の残差プロット
#
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from scipy.stats import gamma
import japanize_matplotlib
# 正規性を満たさない標本データ生成
np.random.seed(0)
X = np.random.rand(200)
# ガンマ分布を使い正規性を満たさないノイズを追加
shape, scale = 2., 1.
y = 2 * X + 1 + np.random.gamma(shape, scale, 200)
# 回帰モデルの適合
X = sm.add_constant(X) # 定数項を追加
model = sm.OLS(y, X).fit()
residuals = model.resid # 残差を取得
# グラフの作成
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 残差プロット
axes[0, 0].scatter(model.fittedvalues, residuals, c='b', marker='o', edgecolor='b')
axes[0, 0].set_xlabel('予測値 (Fitted Values)')
axes[0, 0].set_ylabel('残差 (Residuals)')
axes[0, 0].axhline(y=0, color='r', linestyle='--')
axes[0, 0].set_title('残差プロット (Residual Plot)')
# 残差ヒストグラム
axes[0, 1].hist(residuals, bins=20, color='blue', alpha=0.7)
axes[0, 1].set_xlabel('残差 (Residuals)')
axes[0, 1].set_ylabel('頻度 (Frequency)')
axes[0, 1].set_title('残差ヒストグラム')
# QQプロット
sm.qqplot(residuals, line='s', ax=axes[1, 0])
axes[1, 0].set_title('QQプロット')
axes[1, 0].set_xlabel('理論分位数')
axes[1, 0].set_ylabel('標本分位数')
# ノイズプロット
# ガンマ分布のパラメータ
a = 2
b = 1
# プロット範囲をPPF(累積密度関数(CDF)の逆関数のこと)から求める
x = np.linspace(gamma.ppf(0.01, a=a, scale=b),gamma.ppf(0.99, a=a, scale=b), 200)
# ガンマ分布の確率密度関数 (PDF) のプロット
pdf = gamma.pdf(x, a=a, scale=b)
axes[1, 1].plot(x, pdf, 'r-', lw=2)
axes[1, 1].set_xlabel('x(1%->99%)')
axes[1, 1].set_ylabel('確率密度')
axes[1, 1].set_title('ノイズ(ガンマ分布)')
plt.tight_layout()
plt.show()
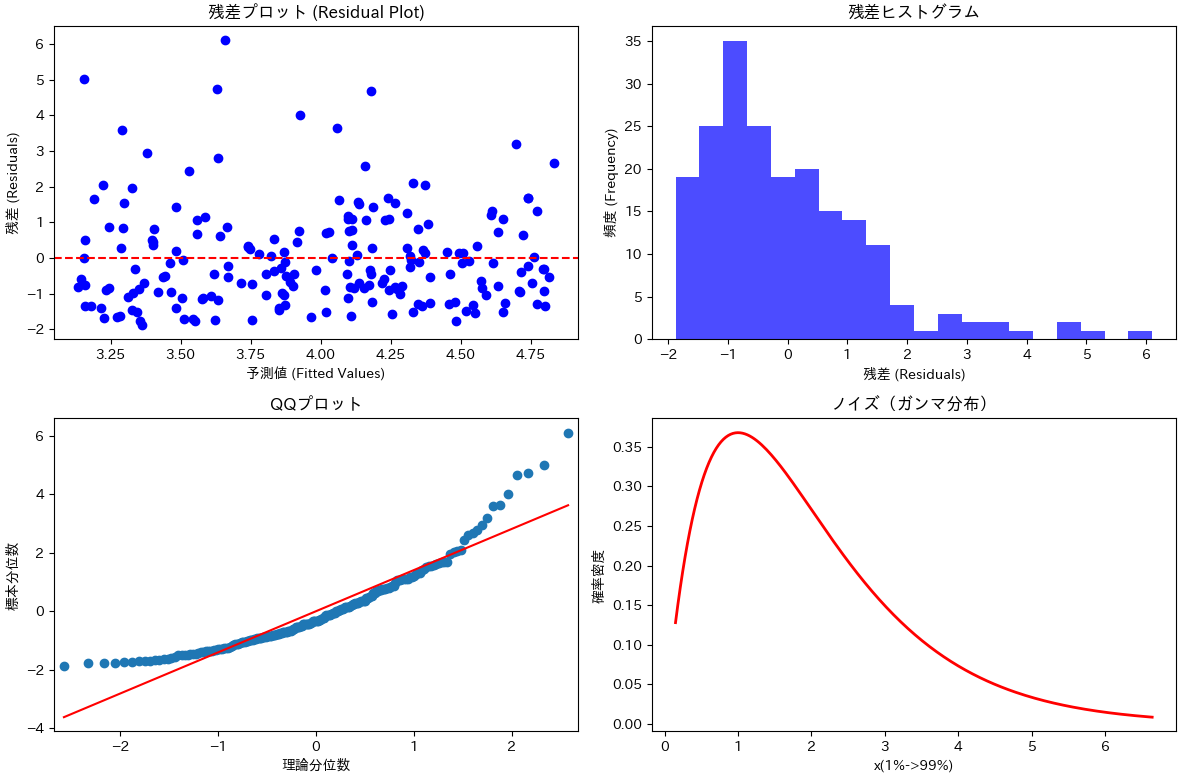
目視による確認は、誤差項が正規分布なのか、そうでないかなの見極めを早くしたいときに役立つでしょう。
4.2. シャピロ・ウィルク検定による確認#
シャピロ・ウィルク(Shapiro-Wilk)検定では順序統計量を使って計算される統計量 W を使います。これはデータが正規分布からどれだけ逸脱しているかを示す指標であり、0 から 1 の範囲の値をとります。 W が 1 に近い場合、データは正規分布に適合していると解釈できます。逆に、統計量が小さい場合、データは正規分布から逸脱している可能性が高いと考えられます。
をW 係数(検定の標本サイズに依存する係数)、観測データを昇順に並べ替えたものを 、 を観測データの平均値としたとき、W 統計量は次の式で与えられます。
係数 の求め方は簡単ではないようで(筆者は確認していません)、数表が用意されています。(URL Shapiro-Wilk表)
順序統計量の補足
標本を としたとき、X の順序統計量は X を昇順に並べなおしたデータから直接決定できる統計量です。
例1 標本サイズ n が奇数のとき、X の中央値は順序統計量である
X を昇順に並べなおしたデータ には中央値が存在するため定義に合致しています。
例2 標本サイズ n が偶数のとき、X の中央値は順序統計量ではない
n= 2mとすると、X を昇順に並べなおしたデータ に中央値はデータ中には存在せず定義に合致しません。
帰無仮説
帰無仮説(H0): 残差項は正規分布に従っている
対立仮説(H1): 残差項は正規分布に従っていない
検定結果として得られる p 値が 0.05 以下であれば帰無仮説を棄却し、残差項は正規分布に従っていないと判断できます。p 値が 0.05 を超える場合は帰無仮説は棄却されません。したがって判断は「残差項は正規分布に従っていないとは言えない」となります。仮説検定特有のなんだかぼんやりした言い回しに聞こえますが作業を前に進めるための理屈にはなっていると思います。
# reg_test_shapiro_wilk.py
# Shapiro-Wilk正規性検定
#
import numpy as np
import statsmodels.api as sm
import scipy.stats as stats
# 標本データ生成
np.random.seed(0)
X = np.random.rand(200)
y = 2 * X + 1 + np.random.normal(0, 0.2, 200)
# 回帰モデルの適合
X = sm.add_constant(X) # 定数項を追加
model = sm.OLS(y, X).fit()
residuals = model.resid # 残差を取得
# 残差の正規性を検定
shapiro_test = stats.shapiro(residuals)
print("残差正規性有りデータに対するShapiro-Wilk正規性検定 p-値 : {:.5f}".format(shapiro_test.pvalue))
if shapiro_test.pvalue < 0.05:
result = "=> 帰無仮説を棄却する: 正規性は認められない."
else:
result = "=> 帰無仮説を棄却できない: 正規性が無いとは言えない."
print(result)
#
# 正規性を満たさない標本データ生成
np.random.seed(0)
X = np.random.rand(200)
y = 2 * X + 1 + np.random.gamma(2, 1, 200) # 正規性を満たさないノイズを追加
# 回帰モデルの適合
X = sm.add_constant(X) # 定数項を追加
model = sm.OLS(y, X).fit()
residuals = model.resid # 残差を取得
# 残差の正規性を検定
shapiro_test = stats.shapiro(residuals)
print("残差正規性無しデータに対するShapiro-Wilk正規性検定 p-値 : {:.5f}".format(shapiro_test.pvalue))
if shapiro_test.pvalue < 0.05:
result = "=> 帰無仮説を棄却する: 正規性は認められない."
else:
result = "=> 帰無仮説を棄却できない: 正規性が無いとは言えない."
print(result)

ノイズが正規分布の場合には、p 値 > 0.05 であり帰無仮説は棄却されません。一方ノイズが正規分布ではない場合には p 値 < 0.05 であり帰無仮説は棄却されます。
5. 誤差項の等分散性の確認#
5.1. 残差プロットを確認#
等分散性を持たない誤差項があった場合、残差プロットを書いてみるとわかりやすくなる場合があります。結果の散布図を見るとドットの分布が右方向へ行くにしたがって広がっていることが見て取れますね。
# c4_check_homosce1.py
# 等分散性を持たないデータの残差プロットを描画する
#
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# ランダムなデータを生成
np.random.seed(0)
X = np.linspace(0, 10, 500) # 10を大きい数値にするほど等分散性の崩れが強くなる
y_true = 2 * X + 1
# 誤差項を生成(等分散性を崩す)
error = np.random.normal(0, 1 + 0.2*X, size=len(X))
y = y_true + error
# 線形回帰モデルのフィッティング
model = LinearRegression()
model.fit(X.reshape(-1, 1), y)
# 残差を計算
residuals = y - model.predict(X.reshape(-1, 1))
# 残差プロットの作成
plt.figure(figsize=(8, 6))
plt.scatter(X, residuals, c='blue', alpha=0.6)
plt.axhline(0, color='red', linestyle='--', linewidth=2)
plt.title("等分散性を持たない残差プロット")
plt.xlabel("X")
plt.ylabel("残差")
plt.show()
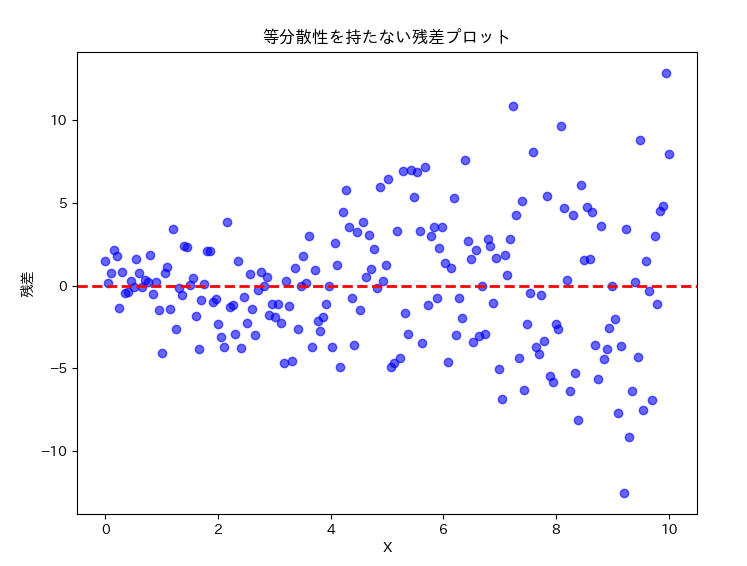
5.2. 検定による定量的確認#
複数グループの分散比較#
ここで紹介する検定方法は誤差項から観測データのグループを複数抽出して分散を比較することで等分散性の有無を検定します。
バートレット検定#
バートレット(Bartlett)検定は、各グループ(または条件)の誤差項の分散が正規分布に従っているという仮定のもとで等分散性を評価します。正規分布に近いデータに対してはより感度が高く、等分散性の崩れを検出しやすい傾向があります。検定統計量の式形は混み入っているので割愛します。
ルビーン検定#
ルビーン(Levene)検定は誤差項の分布に正規性の仮定を置かずに等分散性を評価します。したがって、Levene検定はより頑健で、正規分布から大きく外れるデータに対しても有効です。異常値が含まれている場合や非対称な分布のデータに対してはLevene検定が有用でしょう。検定統計量の式形は混み入っているので割愛します。
帰無仮説
帰無仮説(H0): 残差項のすべての標本は分散が等しい母集団からのものである
対立仮説(H1): 残差項には分散が異なる標本が含まれている
検定結果として得られるp値が0.05以下であれば帰無仮説を棄却し、残差項は等分散性を持たないと判断します。p値が0.05を超える場合は帰無仮説は棄却されません。判断は「残差項は等分散性を持たないとは言えない」となります。
以下に二つの検定方法を比較してみます。データとして等分散ではない誤差項を生成しています。
# reg_test_homosce1.py
# 等分散性有無を判定するためのBartlett検定とLevene検定
#
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from sklearn.linear_model import LinearRegression
# ランダムなデータを生成
np.random.seed(0)
X = np.linspace(0, 10, 500)
y_true = 2 * X + 1
# 誤差項を生成(等分散性を崩す)
error = np.random.normal(0, 1 + 0.2*X, size=len(X))
y = y_true + error
# 線形回帰モデルのフィッティング
model = LinearRegression()
model.fit(X.reshape(-1, 1), y)
# 残差を計算
residuals = y - model.predict(X.reshape(-1, 1))
# Bartlettの等分散性検定を実行
group1 = residuals[:25]
group2 = residuals[25:]
statistic, p_value = stats.bartlett(group1, group2)
if p_value > 0.05:
print("Bartlett 検定: データは等分散ではないとはいえない (p-値 = {:.4f})".format(p_value))
else:
print("Bartlett 検定: データは等分散ではない (p-値 = {:.4f})".format(p_value))
# Leveneの等分散性検定を実行
group1 = residuals[:25]
group2 = residuals[25:]
statistic, p_value = stats.levene(group1, group2)
if p_value > 0.05:
print("Levene 検定: データは等分散ではないとはいえない (p-値 = {:.4f})".format(p_value))
else:
print("Levene 検定: データは等分散ではない (p-値 = {:.4f})".format(p_value))

両検定とも帰無仮説は棄却されました。
6. 誤差項の自己相関の確認#
6.1. コレログラム#
コレログラムは現時点から過去に向かって自己相関の強さを棒グラフで表現します。自己相関の有無を直観的に理解しやすくすぐれた可視化方法だと思います。以下のコードは自己相関の無いデータとあるデータを使って残差プロットとコレログラムを可視化します。 サンプルコードのなかで plot_acf 関数によって描画される自己相関関数(ACF)のコレログラムに重ねあわされた薄い色のハッチの領域があります。これはバートレットの公式と呼ばれる式により計算された標準偏差を用いた95%信頼区間を示しています。
自己相関の無いデータの可視化
# reg_plot_corr1a.py
# 自己相関を持たないデータに対する残差プロットとコレログラム
#
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.stats.diagnostic import acorr_ljungbox
import japanize_matplotlib
# ランダムな時系列データを生成(自己相関がない例)
np.random.seed(0)
n = 100 # データ点の数
t = np.arange(n)
# 誤差項に自己相関を持たせない
error = np.random.normal(0, 0.2, n)
# 真のモデル
true_model = 0.5 * np.sin(0.2 * t)
# ノイズを持つ観測データ
observed_data = true_model + error
# 残差プロット
residuals = observed_data - true_model
# ACFプロット(コレログラム)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].scatter(t, residuals, marker='o', color='b')
axes[0].axhline(0, color='red', linestyle='--', linewidth=2)
axes[0].set_title("残差プロット")
axes[0].set_xlabel("時間")
axes[0].set_ylabel("残差")
plot_acf(residuals, lags=20, ax=axes[1],alpha=0.05)
axes[1].set_title("残差のコレログラム")
axes[1].set_xlabel("ラグ(Lag)")
axes[1].set_ylabel("自己相関(ACF)")
plt.tight_layout()
plt.show()
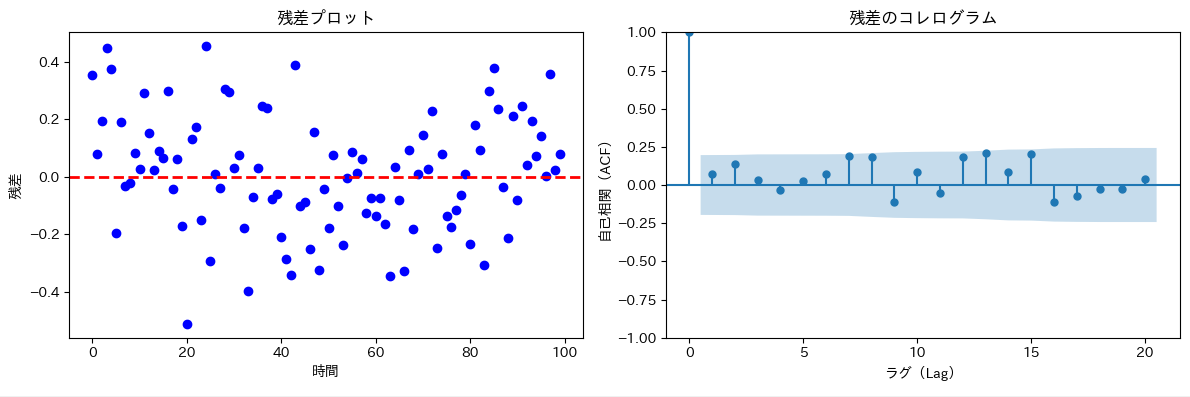
全てのACFが信頼区間の中に収まっており、このデータは自己相関が無いこと示唆しています。
自己相関のあるデータの可視化
# reg_plot_corr1b.py
# 自己相関を持つデータに対する残差プロットとコレログラム
#
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.stats.diagnostic import acorr_ljungbox
import japanize_matplotlib
# ランダムな時系列データを生成(自己相関を持つ例)
np.random.seed(0)
n = 100 # データ点の数
t = np.arange(n)
# 自己相関を持つ誤差項を生成
error = 0.7 * np.sin(0.1 * t) + np.random.normal(0, 0.2, n)
# 真のモデル
true_model = 0.5 * np.sin(0.2 * t)
# ノイズを持つ観測データ
observed_data = true_model + error
# 残差プロット
residuals = observed_data - true_model
# ACFプロット
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].scatter(t, residuals, marker='o', linestyle='-', color='b')
axes[0].axhline(0, color='red', linestyle='--', linewidth=2)
axes[0].set_title("残差プロット")
axes[0].set_xlabel("時間")
axes[0].set_ylabel("残差")
plot_acf(residuals, lags=20, ax=axes[1],alpha=0.05)
axes[1].set_title("残差のコレログラム")
axes[1].set_xlabel("ラグ(Lag)")
axes[1].set_ylabel("自己相関(ACF)")
plt.tight_layout()
plt.show()
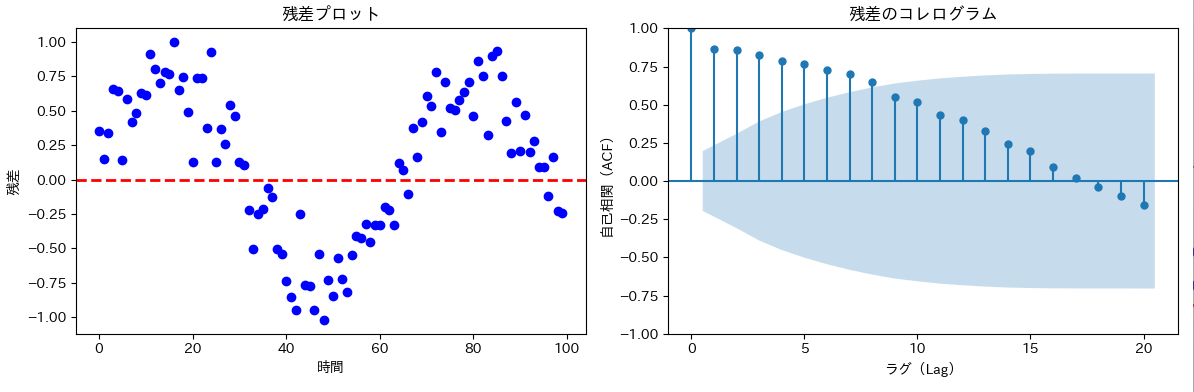
一部のACFが信頼区間からはずれており、このデータは自己相関があることを示唆しています。
6.2. 検定による定量的確認#
リュング・ボックス検定#
リュング・ボックス(Ljung-Box)検定は、以下の式で表されるLjung-Box統計量を用いて帰無仮説を判定します。
ここで、n は標本数、h はラグ数、 はラグ j での標本自己相関
帰無仮説
帰無仮説(H0): 残差項のラグ1からラグhまでの自己相関が全てゼロである
対立仮説(H1): 残差項のラグ1からラグhまでにひとつ以上ゼロではない自己相関がある
は自由度 h のカイ二乗分布に従うため、帰無仮説が成立すると仮定した場合、全てのラグでは の95%信頼区間を外れた(棄却域の)数値を、あるいはp値でいえば0.05以下の値を示します。
以下は自己相関を持つテストデータおよびに、自己相関を持たないテストデータをを用いてLjung-Box検定行うコードです。
# reg_test_ljungbox.py
# 自己相関の有無を検定する
#
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.stats.diagnostic import acorr_ljungbox
#
# ランダムな時系列データを生成(自己相関がない例)
#
np.random.seed(0)
n = 100 # データ点の数
t = np.arange(n)
# 誤差項に自己相関を持たせない
error = np.random.normal(0, 0.2, n)
# 真のモデル
true_model = 0.5 * np.sin(0.2 * t)
# ノイズを持つ観測データ
observed_data = true_model + error
# 残差プロット
residuals = observed_data - true_model
# Ljung-Box検定
lags = 20 # ラグ数
df = acorr_ljungbox(residuals, lags=lags)
print("自己相関の無いデータを使った時のLjung-Box検定")
print(df)
#
# ランダムな時系列データを生成(自己相関を持つ例)
#
np.random.seed(0)
n = 100 # データ点の数
t = np.arange(n)
# 自己相関を持つ誤差項を生成
error = 0.7 * np.sin(0.1 * t) + np.random.normal(0, 0.2, n)
# 真のモデル
true_model = 0.5 * np.sin(0.2 * t)
# ノイズを持つ観測データ
observed_data = true_model + error
# 残差プロット
residuals = observed_data - true_model
# Ljung-Box検定
lags = 20 # ラグ数
df = acorr_ljungbox(residuals, lags=lags)
print("自己相関の有るデータを使った時のLjung-Box検定")
print(df)
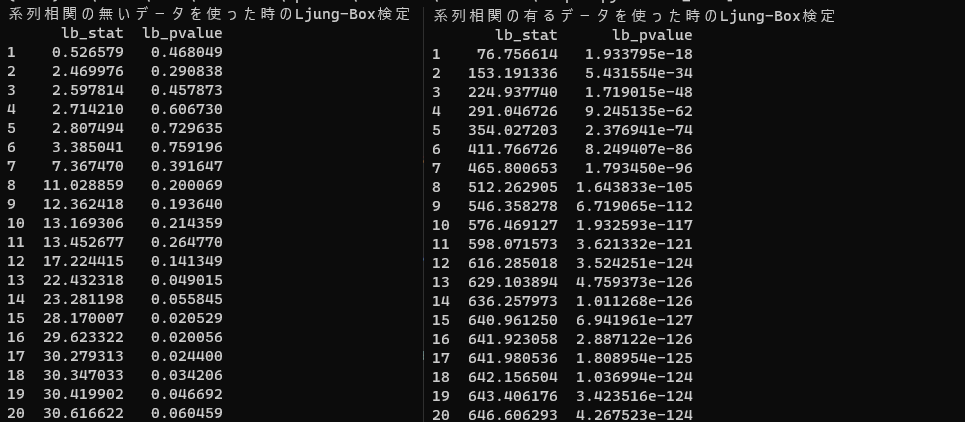
結果を見ると右側の自己相関のあるテストデータに関しては確かにすべてのラグで有意水準を下回るp値を示しています。したがって帰無仮説は棄却され自己相関が存在すると結論できます。
一方左側の自己相関のないテストデータに関しては部分的に有意水準を上回るp値を示すラグが存在しています。それゆえ帰無仮説は棄却できません。結論は「自己相関が存在するとはいえない」となります。
ダービン・ワトソン検定#
ダービン・ワトソン(Durbin-Watson)検定は時系列モデルを対象とし誤差項の自己相関の有無を検定する手法です。 基本的な考え方は回帰モデル の誤差項 が自己相関を持つとします. つまり と表記したときに, であることを検定します。
検定統計量は以下の式で与えられます。
回帰係数 の推定値は Yule-Walker 方程式より となるので、標本サイズNが大きければ であることが計算により示されます。したがって、ρ が 0(自己相関がない)であれば dw は 2 になります。dw は常に 0 ~ 4 の間の値をとります。dw が 0 に近づくほど、正の自己相関が強いことを示唆します。 一方 4 に近づくほど、負の自己相関が強いことを示唆します。
帰無仮説
金融・経済での時系列分析においては正の自己相関有無を議論することが多いと思われます。このため以下のような帰無仮説を設定します。
帰無仮説(H0): 全ての残差項で非正値の自己相関を示す
対立仮説(H1): 正の自己相関を示す残差項が存在する
ダービン・ワトソン表を参照すると dw の臨界値(上限臨界値 du、下限臨界値 dl )がわかるので両者を比較することで帰無仮説の検証を行うことができます。
以下のコードは標本サイズ N = 100、1 次の回帰モデルに対して自己相関の無い標本データ、有る標本データに対しダービン・ワトソン(Durbin-Watson)検定を行い結果を表示します。
参考4 ダービン・ワトソン表 (real-statistics.com)
標本データを描画するプログラム
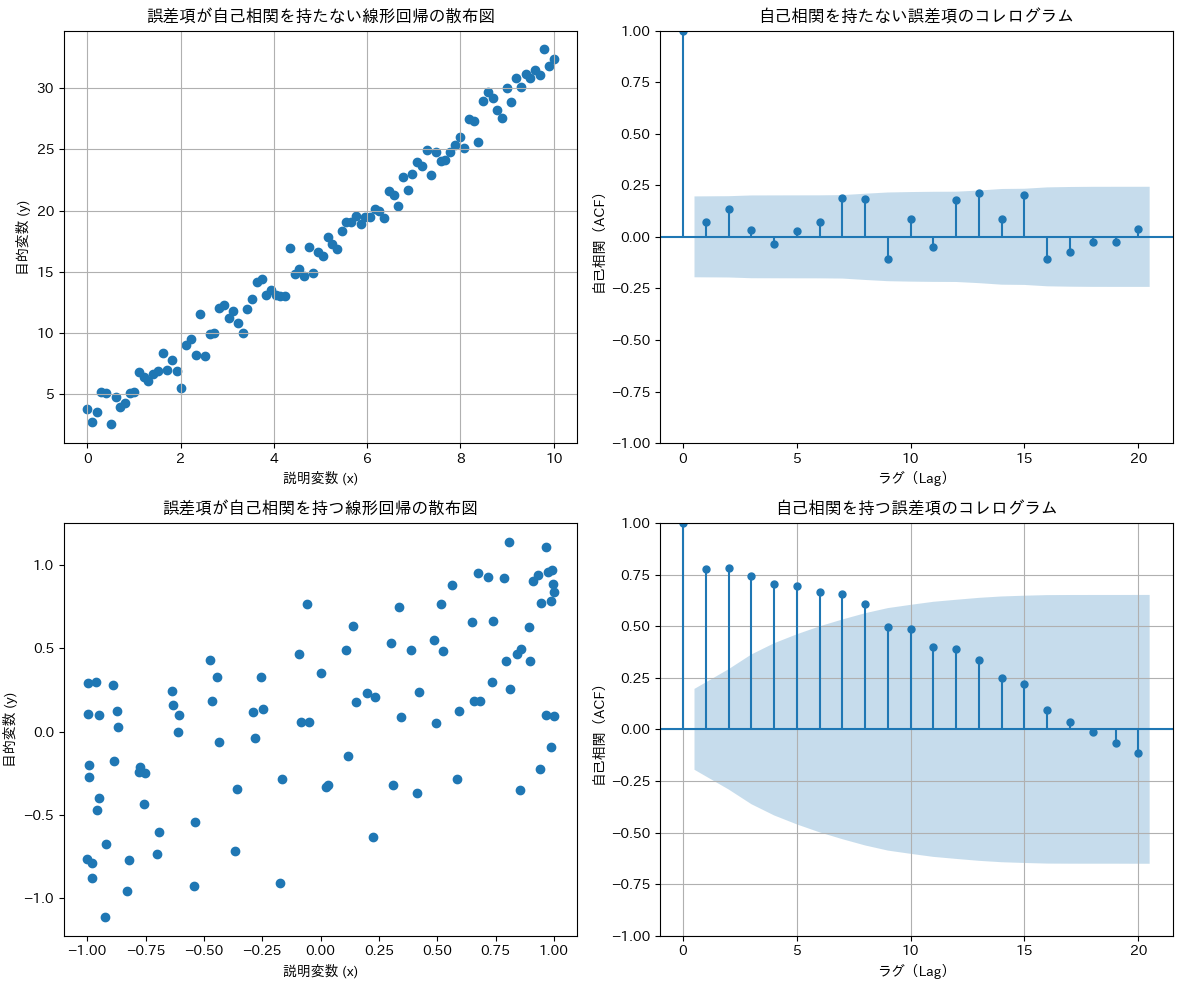
# reg_plot_correl1.py
# 自己相関を散布図とコレログラムで可視化する
#
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
import japanize_matplotlib
np.random.seed(0)
n = 100 # 標本サイズ
intercept = 2.0
slope = 3.0
error_std_dev = 1.0
x = np.linspace(0, 10, n) # 説明変数
error = np.random.normal(0, error_std_dev, n) # 誤差項
y = intercept + slope * x + error # 目的変数
# 2x2 subplots
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# Subplot 1: Scatter plot of the data
axes[0][0].scatter(x, y, label='Data Points')
axes[0][0].set_title('誤差項が自己相関を持たない線形回帰の散布図')
axes[0][0].set_xlabel('説明変数 (x)')
axes[0][0].set_ylabel('目的変数 (y)')
axes[0][0].grid(True)
# コレログラム描画
plot_acf(error, lags=20, ax=axes[0][1])
axes[0][1].set_title("自己相関を持たない誤差項のコレログラム")
axes[0][1].set_xlabel("ラグ(Lag)")
axes[0][1].set_ylabel("自己相関(ACF)")
np.random.seed(0)
error_std_dev = 0.2
n = 100 # データ点の数
t = np.arange(n)
explanatory_data = np.sin(0.2 * t)
# 自己相関を持つ誤差項を生成
error = 0.5 * np.sin(0.1 * t) + np.random.normal(0, error_std_dev, n)
# 真のモデル
true_model = 0.5 * explanatory_data
# ノイズを持つ観測データ
observed_data = true_model + error
# Subplot 2: Scatter plot of the data
axes[1][0].scatter(explanatory_data, observed_data, label='Data Points')
axes[1][0].set_xlabel('説明変数 (x)')
axes[1][0].set_ylabel('目的変数 (y)')
axes[1][0].set_title('誤差項が自己相関を持つ線形回帰の散布図')
# Subplot 4: Correlogram (Autocorrelation Plot) for Error Terms
plot_acf(error, lags=20, ax=axes[1][1])
axes[1][1].set_title("自己相関を持つ誤差項のコレログラム")
axes[1][1].set_xlabel("ラグ(Lag)")
axes[1][1].set_ylabel("自己相関(ACF)")
axes[1][1].grid(True)
# Adjust layout
plt.tight_layout()
# Show the plots
plt.show()
ダービン・ワトソン検定を実行するプログラム
# reg_test_durbin_watson1.py
# Durbin-Watson検定
#
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.stattools import durbin_watson
"""
DW統計表の5%点下限臨界値dlを下回る場合正の相関,上限臨界値duを上回る場合は負の相関を示す。
独立パラメータ数 k = 1,標本サイズ n= 100ではdl = 1.654 du = 1.694
"""
dl = 1.654
du = 1.694
print("#==================================================================")
print("# ランダムな時系列データを生成(自己相関を持たない例)")
print("#==================================================================")
np.random.seed(0)
n = 100 # 標本サイズ
error_std_dev = 1.0
t = np.arange(n)
explanatory_data = np.sin(0.2 * t) # 説明変数
error = np.random.normal(0, error_std_dev, n) # 誤差項に自己相関を持たせない
true_model = 0.5 * explanatory_data # 真のモデル 自由度 k = 1
observed_data = true_model + error # ノイズを持つ観測データ
# OLS Regression
# 説明変数に定数項を追加
explanatory_variable_with_const = sm.add_constant(explanatory_data)
dependent_variable = observed_data
# 単回帰モデルの構築
model = sm.OLS(dependent_variable, explanatory_variable_with_const)
# モデルの適合
res = model.fit()
# 回帰分析の結果を表示
print(res.summary())
# Durbin-Watson検定
residuals = observed_data - true_model
dw_statistic = durbin_watson(residuals)
k = 1 # 説明変数の個数
# Compare the dw and dw table critical value
if dw_statistic < dl :
print(f"帰無仮説を棄却する: 自己相関が残差項に現れている. durbin_watson統計量 = {dw_statistic:.4f}")
elif dl <= dw_statistic and dw_statistic <= du:
print(f"帰無仮説を棄却できない: なにも判断できない. durbin_watson統計量 = {dw_statistic:.4f}")
elif du < dw_statistic:
print(f"帰無仮説を棄却できない: おそらく自己相関は無い. durbin_watson統計量 = {dw_statistic:.4f}")
print(" ")
print("#==================================================================")
print("# ランダムな時系列データを生成(自己相関を持つ例)")
print("#==================================================================")
np.random.seed(0)
n = 100 # 標本サイズ
error_std_dev = 0.2
t = np.arange(n)
explanatory_data = np.sin(0.2 * t) # 説明変数
error = 0.5 * np.sin(0.1 * t) + np.random.normal(0, error_std_dev, n) # 自己相関を持つ誤差項を生成
true_model = 0.5 * explanatory_data # 真のモデル 自由度 k = 1
observed_data = true_model + error # ノイズを持つ観測データ
# OLS Regression
# 説明変数に定数項を追加
explanatory_variable_with_const = sm.add_constant(explanatory_data)
dependent_variable = observed_data
# 単回帰モデルの構築
model = sm.OLS(dependent_variable, explanatory_variable_with_const)
# モデルの適合
res = model.fit()
# 回帰分析の結果を表示
print(res.summary())
# Durbin-Watson検定
residuals = observed_data - true_model
dw_statistic = durbin_watson(residuals)
if dw_statistic < dl :
print(f"帰無仮説を棄却する: 自己相関が残差項に現れている. durbin_watson統計量 = {dw_statistic:.4f}")
elif dl <= dw_statistic and dw_statistic <= du:
print(f"帰無仮説を棄却できない: なにも判断できない. durbin_watson統計量 = {dw_statistic:.4f}")
elif du < dw_statistic:
print(f"帰無仮説を棄却できない: おそらく自己相関は無い. durbin_watson統計量 = {dw_statistic:.4f}")
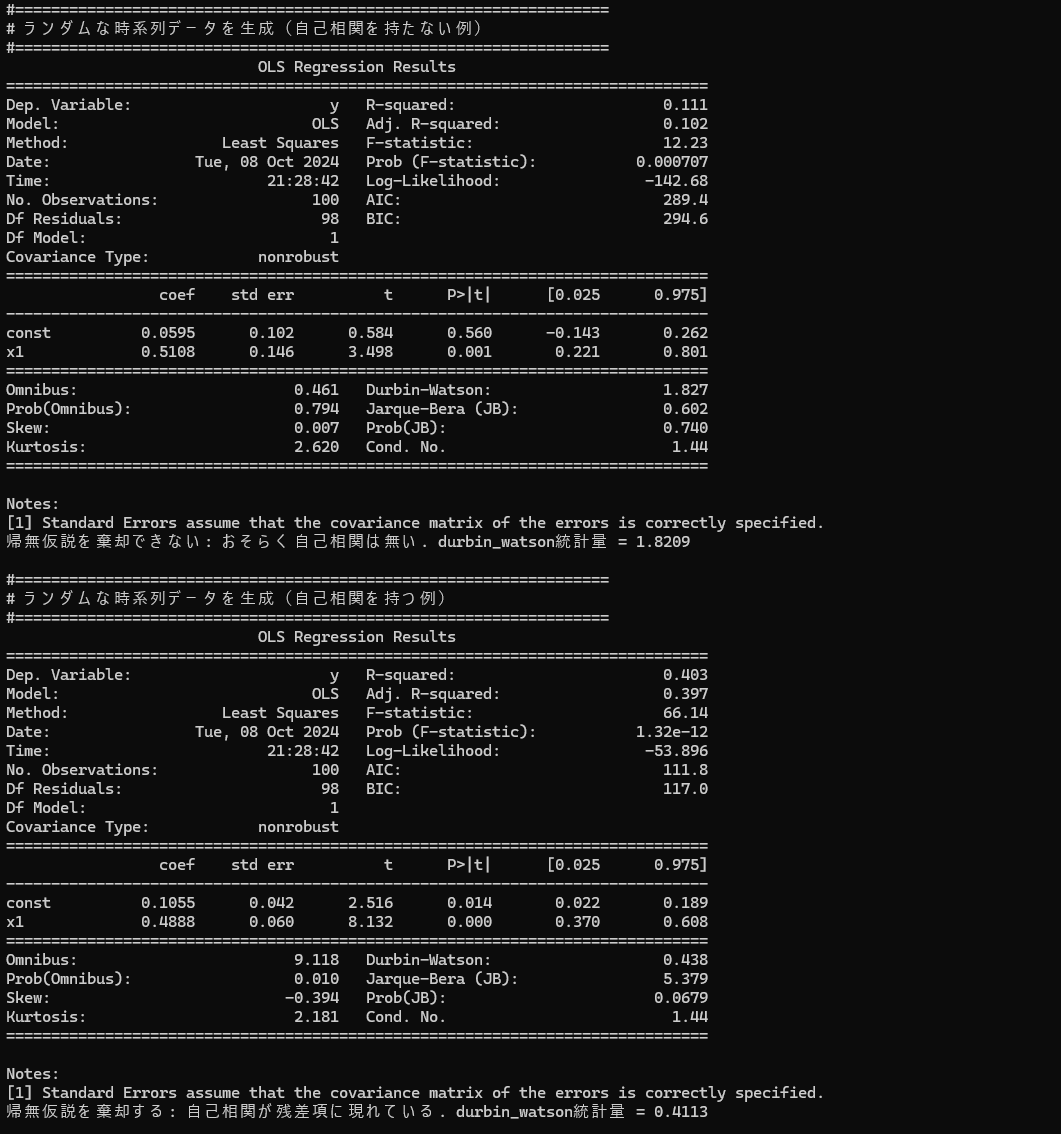
実行した結果、標本データの自己相関性をDurbin-Watson検定により確認することができました。
7. 説明変数の独立性の確認#
多重共線性とは?
多重共線性(Multicollinearity)は、回帰分析において説明変数間に高い相関があるときに発生する現象です。例えば下記のような問題を引き起こすため、対象とするデータに対して多重共線性の有無をチェックしてから次のステップに進むことが安全でしょう。
-
係数の不安定性:
説明変数の係数の推定値が不安定になる。標本サイズが小さい場合に微小な変化が係数の大きな変動を引き起こす可能性がある。 -
説明変数の解釈が困難:
説明変数の効果を独立に解釈することが難しくなる。つまり、どの説明変数が目的変数にどの程度の影響を与えているのかを明確にできない。 -
統計的有意性の問題:
説明変数の係数の統計的有意性を判断することが難しくなる。係数の t 値や p 値が信頼性の指標として不適切になる。 -
予測の精度低下:
モデルの予測精度を低下させる可能性がある。モデルが過剰に複雑になり、未知のデータに適合しなくなることがある。
多重共線性への対策:
-
相関係数を確認し必要性の少ない変数を削除する:
二変数の相関、あるいは多変数間の相関をチェックします。そして相関が高い説明変数のうちモデルに実際に必要のないものを削除します。 -
主成分分析(PCA)により独立な説明変数群へ変換する:
主成分分析を使用して、元の説明変数から新しい線形結合を生成し、これらの主成分を代わりに使用します。主成分は互いに無相関であるため、多重共線性の問題を回避できます。
7.1 相関係数を確認する#
- 説明変数が 2 個の場合
回帰モデルの相関行列を計算して可視化します。
- 説明変数が 3 個以上の場合
分散拡大係数(variance inflation factor, VIF)を計算して可視化します。VIF は、回帰係数の分散が予測変数間の相関の影響でどれくらい膨らんでいるかを示す指標です。計算式は以下のようになります。
は 番目の変数に対する分散拡大係数。
はi番目の予測変数を目的変数とし、他のすべての予測変数を説明変数とした回帰モデルの決定係数です。
VIF計算の流れ:
-
回帰モデルの適合
番目の変数を目的変数とし、他の予測変数を説明変数として、重回帰分析を行います。 -
の計算
回帰モデルから 値を取得します。この は、他の予測変数によって説明されるi番目の変数の分散の割合を表します。
解釈:
一般的に、VIF が 5 を超える場合は多重共線性の可能性を無視できず、 10 を超える場合は多重共線性の疑いが強いと考えられます。VIFが 1 、つまり がゼロの場合は、3.1.2項で記述したように予測変数間に相関がないことを示すものです。VIF の背後にある考え方は、 が 1 に近い場合、i 番目の変数が他の予測変数によってほぼ完璧に予測できることを示し、その係数の推定に大きな標準誤差が生じるため、VIF が大きくなるというものです。
Califolnia 住宅データにおける多重共線性を調べる例
scikit-learn が用意している California 住宅データのロード関数を用いて標本データを作ります。そして statsmodels の VIF 計算用関数を用いて VIF を求めてみます。
使用するデータの内容
| カラム名 | 説明 |
|---|---|
| median_income | 世帯収入中央値 |
| housing_median_age | 住宅築年数中央値 |
| total_rooms | 全部屋数 |
| total_bedrooms | 寝室数 |
| population | ブロック内人口 |
| households | ブロック内世帯数 |
| latitude | ブロック中心緯度 |
| longitude | ブロック中心経度 |
# reg_check_vif1.py
# California住宅データを例としたVIF可視化
#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.datasets import fetch_california_housing
import japanize_matplotlib
# California 住宅データをpandasデータフレームへロードする
california_housing = fetch_california_housing()
print(california_housing.DESCR)
columns = california_housing.feature_names
data = np.c_[california_housing.data, california_housing.target]
df = pd.DataFrame(data, columns=columns + ['MedHouseVal'])
# 例として使用するカラムをデータフレームから抽出する
selected_features = ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population','AveOccup','Longitude']
tick_labels_jp = ["世帯収入", "住宅築年数", "全部屋数","寝室数", "ブロック内人口", "平均世帯人数","ブロック中心経度"]
selected_df = df[selected_features]
# 抽出したカラムからVIFを計算する
vif_results = pd.DataFrame()
vif_results['Variable'] = selected_features
vif_results['VIF'] = [variance_inflation_factor(selected_df.values, i) for i in range(selected_df.shape[1])]
# VIFをバーチャートでプロットする
plt.figure(figsize=(8, 5))
plt.bar(vif_results['Variable'], vif_results['VIF'], color='skyblue',tick_label=tick_labels_jp)
plt.title('VIF (California Housing Data)')
plt.xlabel('説明変数')
plt.ylabel('VIF')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
このプログラムを実行すると以下のチャートが表示されます。
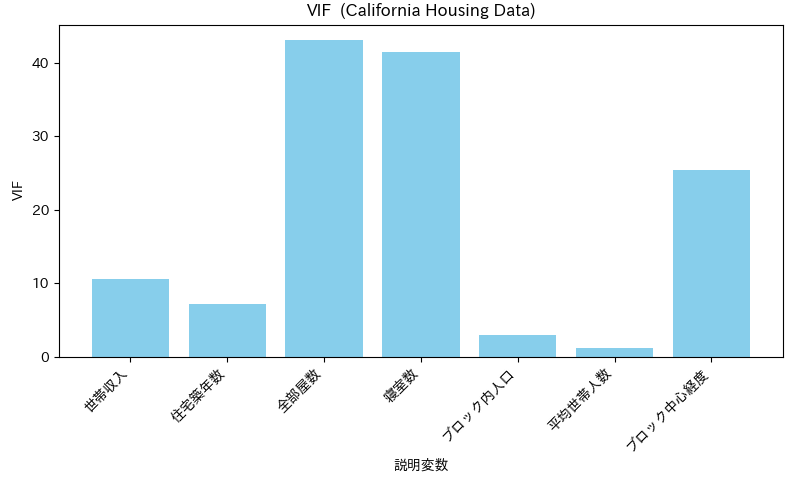
この結果を見ると、世帯収入(MedInc)、全部屋数(total_rooms)、寝室数(total_bedrooms)、ブロック中心経度(longitude)が高いVIF値を示しています。Californiaの住宅事情では世帯収入と地理特性の相関(海岸近くは高所得層が多い等)や、そもそも相関が強いと思われるデータ(寝室数、部屋数、価格)があり結果に不自然さを感じません。一般には多重共線性を生む要因になりそうな以下のようなポイントをいくつかあげておきます。
- 冗長なデータ そもそも全部屋数と寝室数の間に高い相関が出そうなことは明らかなので、データに冗長な情報が含まれていれば多重共線性の問題が発生する可能性があります。
- 地理的関係 経度などの地理的特徴に関連する変数も、空間的関係により多重共線性を示す場合があります。 たとえば、経度が似ている地域は住宅の特徴も似ている可能性があり、その特徴に関連する変数間の相関が高くなります。
- 計量尺度が違うデータの混在 大きなスケールの変数が存在すると、モデルがそれらの変数により多くの重みを割り当て、変数がより影響力があるように見え、多重共線性の問題が悪化する可能性があります。
- 相関を持つデータを介して間接的に影響を受ける 相関を示すデータ A,B に対して、別のデータ C が A と相関を持つ場合、 C と B は一見関係ないように見えたとしても相関が発生する可能性があります。
7.2 主成分分析を利用#
主成分分析 (PCA) は、回帰分析における多重共線性に対処する手法として使用できます。 PCA は、相関のある変数のセットを、主成分と呼ばれる新しい相関のない変数のセットに変換する次元削減手法です。 PCA を使用して多重共線性を評価し、回避する方法は次のとおりです。
多重共線性の強さを評価する:
- データの準備
- 平均を減算し、標準偏差で割ることにより、説明変数を標準化します。
- PCA 実行
- 標準化された説明変数に対して PCA を実行します。
- PCA は主成分を生成します。各成分は元の説明変数の線形結合です。
- 固有値と固有ベクトル計算
- 標準化された説明変数の共分散行列の固有値と固有ベクトルを計算します。
- 固有値は、各主成分によって説明される分散を表します。
- 固有ベクトルは、元の変数空間の主成分の方向を表します。
- 主成分を選択
- 固有値を調べて、寄与率(その成分が持つ分散値の割合)が大きい主成分のみを保持します。
- 大きい順に寄与率を累計し 70% ~ 80% までの主成分を保持することが良いと言われています。
多重共線性を回避する:
- 主成分による回帰:
- 保持された主成分を、元の説明変数の代わりに回帰モデルの新しい説明変数として使用します。
- 主成分が直交している (相関がない) ため、多重共線性の問題が軽減されます。
- 結果の解釈:
- 主成分に関して回帰係数を解釈します。
- 主成分は元の変数の組み合わせであるため、解釈が簡単ではない可能性があることに注意してください。
- 差異の評価の説明:
- 保持された主成分によって説明される分散のパーセンテージを評価します。
- データ内の重要な情報を捕捉するために十分な量の分散が保持されていることを確認します。
考慮事項:
- 解釈可能性の喪失:
主成分は元の説明変数の組み合わせであるため、PCA は解釈可能性の喪失につながる可能性があります。 - データ変換:
PCA は線形性を前提としているため、すべての種類のデータに適しているわけではありません。 - 次元削減:
PCA は次元削減にも使用でき、データの分散の大部分を維持しながらモデル内の予測子の数を削減します。
PCA を使用して多重共線性に対処すると、特に相関性の高い説明変数を扱う場合に、回帰モデルの安定性と解釈可能性を向上させることができます。
Califolnia 住宅データに対する主成分分析を試す例
以下の例では scikit-learn が用意している主成分分析の関数を用いてみましょう。
例 1 は主成分を寄与率の順に並べどれが保持すべき主成分を評価します。また結果の主成分の相関行列を計算して各成分間に相関が無い(ほとんどない)を確認します。
例 2 、例 3 は主成分の解釈のため元の説明変数が主成分に対してどれだけの荷重を与えているかを資格化します。
# pca_variance_ratio.py
#
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import japanize_matplotlib
# California 住宅データをpandasデータフレームへロードする
california_housing = fetch_california_housing()
X = california_housing.data # Independent variables
y = california_housing.target # Target variable
# 特徴量を標準化する
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 主成分分析(PCA)を実行する
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# 分散合計値に占める割合を求める
explained_variance_ratio = pca.explained_variance_ratio_
# 各主成分の寄与率をプロットする
plt.figure(figsize=(8, 6))
plt.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio, alpha=0.5, align='center')
plt.ylabel('分散の寄与率')
plt.xlabel('主成分')
plt.title('各主成分の寄与率(分散合計値に占める割合)')
plt.show()
# 主成分をデータフレーム化する
pca_df = pd.DataFrame(X_pca, columns=[f'PC{i+1}' for i in range(X_pca.shape[1])])
# 主成分の相関行列を計算する
correlation_matrix = pca_df.corr()
# 主成分の相関行列の値を表示する
print("主成分の相関行列:")
print(correlation_matrix)
このプログラムを実行すると以下のチャートが表示されます。チャートを見ると主成分5までとればほぼ90%収まっているので十分と思えます。
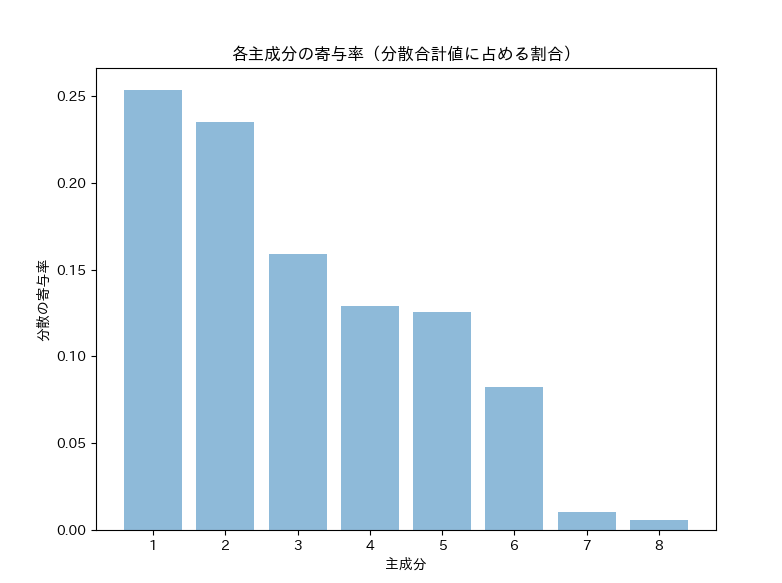
以下は共分散行列の値です。

# pca_loads_expla.py
#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
import japanize_matplotlib
# California 住宅データをpandasデータフレームへロードする
california_housing = fetch_california_housing()
X = california_housing.data # Independent variables
feature_names = california_housing.feature_names # Feature names
# 説明変数を標準化する
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 主成分分析(PCA)を実行する
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# 主成分に対する元の説明変数の負荷量(loadings)を求める
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
# 負荷量をデータフレーム化する
loadings_df = pd.DataFrame(loadings, columns=[f'PC{i+1}' for i in range(len(pca.components_))],
index=feature_names)
# 各説明変数ごとに主成分への負荷量をプロットする
plt.figure(figsize=(10, 6))
loadings_df.plot(kind='bar', ax=plt.gca())
plt.title('各説明変数ごとに主成分への負荷量をプロットする')
plt.ylabel('負荷量')
plt.xlabel('元の説明変数')
plt.xticks(rotation=45, ha='right')
plt.legend(loc='upper left', bbox_to_anchor=(1.0, 1.0))
plt.tight_layout()
plt.show()
このプログラムを実行すると以下のチャートが表示されます。
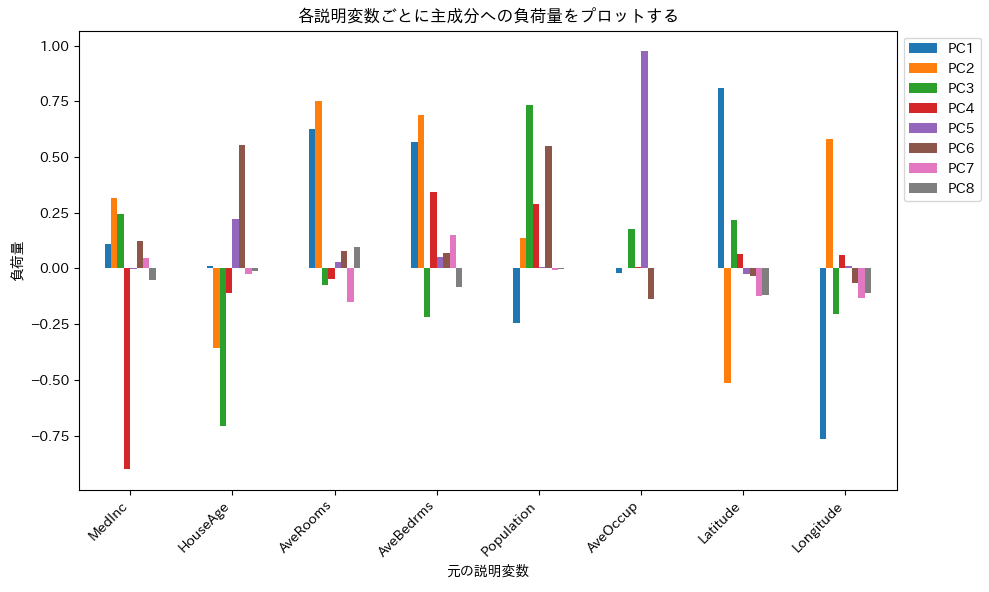
# pca_loads_pc.py
#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
import japanize_matplotlib
# California 住宅データをpandasデータフレームへロードする
california_housing = fetch_california_housing()
X = california_housing.data # Independent variables
feature_names = california_housing.feature_names # Feature names
# 説明変数を標準化する
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 主成分分析(PCA)を実行する
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# 主成分に対する元の説明変数の負荷量(loadings)を求める
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
# 負荷量をデータフレーム化する
loadings_df = pd.DataFrame(loadings, columns=[f'PC{i+1}' for i in range(len(pca.components_))],
index=feature_names)
# 各主成分ごとに元の説明変数からの寄与率をプロットする
loadings_transposed = loadings_df.T
# Plot loadings for each principal component
plt.figure(figsize=(10, 6))
loadings_transposed.plot(kind='bar', ax=plt.gca())
plt.title('各主成分ごとに元の説明変数からの負荷量をプロットする')
plt.ylabel('負荷量')
plt.xlabel('主成分')
plt.xticks(rotation=0)
plt.legend(loc='upper left', bbox_to_anchor=(1.0, 1.0))
plt.tight_layout()
plt.show()
このプログラムを実行すると以下のチャートが表示されます。
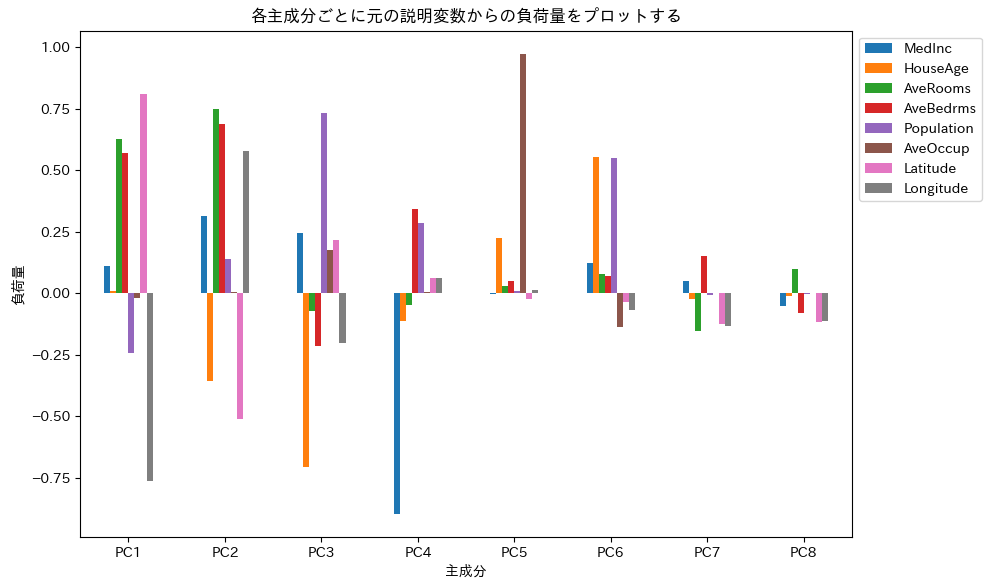
8. 一般化線形モデル#
本章冒頭で紹介しました最小二乗法推定を使う線形回帰モデルは、基本的で応用の広い手法です。しかしながら保険や資産取引などの金融系データ、あるいは消費や雇用などの経済系データは、一般に非定常性や自己相関、ボラティリティの変動などの特徴を示すものがあるため、1節で想定した古典的な線形回帰モデルだけでは十分対応できません。そこでこの節では、正規分布以外の分布を扱うことができる一般化線形モデルについて補足しようと思います。
John Nelder と Robert Wedderbur(1972年)は、線形回帰モデルの概念を拡張した一般化線形モデル(Generalized Linear Model,GLM)を提案しました。古典的線形回帰モデルでは、説明変数と応答変数の関係が線形であることが求められます。これに対し、GLMでは、リンク関数という概念を導入することにより、線形性を一部緩和した関係をモデル化することを可能としています。また、古典的線形回帰モデルは、目的変数が連続的であり、正規分布に従うことを前提としています。これに対してGLMでは、目的変数の性質に応じて、異なる確率分布(例えば、二項分布、ポアソン分布、ガンマ分布など)を使用できるように設計されています。
例えば金融・経済領域でいえば、保険のリスク管理、収益の予測、雇用や消費動向指数など 対象とするデータが、非負であったり、右側に歪んでいたり、等分散性を有していなかったりと、複雑な性質を持つ事象が多々存在しています。GLMは正規分布を前提とする古典的線形回帰モデルでは扱いが困難であったそのような事象群の取り扱いを可能にしたことが大きな特徴となっています。
8.1. モデルの定義#
一般化線形モデルは、次の3つの要素で構成されています。
確率分布族
目的変数 の確率分布は、指数族分布に従うと仮定します。
ここで、
:確率変数 Y の観測値
:分布を特徴づけるパラメータであり、自然パラメータまたはカノニカルパラメータと呼ばれます
:データのみに依存する関数であり、基底測度(base measure)と呼ばれる
:既知のパラメータ関数
:Yの既知の統計量であり、fの式形からT はの十分統計量になっている
:正規化関数(対数正規化項)と呼ばれ、分布を積分可能にするための項
指数分布族の性質については「補足説明 確率・統計」にまとめていますので適宜参照ください。
線形予測子
説明変数 を用いて、次の線形予測子を定義します
ここで、 は推定するパラメータのベクトルです。
リンク関数
線形回帰では、目的変数 そのものが説明変数の線形結合で表されますが、GLMではリンク関数を使って、説明変数の線形結合と目的変数 の期待値 を結びつけます。
gの逆関数を使えば は次のように表されます:
線形回帰ではその式形から、説明変数の値によっては目的変数 は負の値を取る可能性があります。そのため、売上や失業率といった本来的に正値の情報は直接的に扱うことができません。そのようなケースでよくやるのが元の目的変数を対数変換し、それを線形回帰モデルで表すことです。
これから類推して、上出の線形予測子の定義に誤差項を追加し、リンク関数を直接目的変数に適用するのではまずいのだろうか、とふと思うのですがこの考えはうまくないようです。
また、GLMの定義式には明確なメリットがあります。GLMは指数型分布族を前提としています。この場合、目的変数の期待値にリンク関数を適用し線形予測子と結びつけることで、いろいろな計算がパズルの答えのようにうまくはまる設計になっています。
8.2. パラメータの推定#
GLMでは最尤推定法を用いてパラメータの推定を行います。
尤度関数の定義
目的変数 の観測データ に対して、尤度関数 を定義します:
ここで、 は 番目の観測値に対するパラメータであり、リンク関数を用いて以下のように表されます:
対数尤度関数の導出
尤度関数の対数を取って、対数尤度関数 を定義します:
最適化
対数尤度関数を最大化することによって、最適なパラメータ を推定します。これには、対数尤度関数の微分を利用します:
この方程式を解くことで、最適なパラメータの推定値 を得ることができます。具体的には、ニュートン法や確率的勾配降下法などの最適化アルゴリズムを用いて解決します。また、オープンソースの科学技術計算用パッケージ scipy は、最尤推定計算をサポートしたクラスをサポートしていますのでこれを使うことで容易に最尤推定を行うことができるのでお勧めです。
この最適化のプロセスをガンマ分布を例として具体的にフォローしてみます。 ガンマ分布は、金融および経済分野で、非負データや右に歪んでいたり、右側にロングテイルな、等の特徴をもつデータを扱う場合に多く使用されます。例えば、保険のリスク管理、信用リスクモデル、待ち時間のモデリング、収益の予測、取引コストのモデル化などを例としてあげることができます。これらの例では、データが正の範囲にあり、分布が非対称な形状を持つ場合が多いため、ガンマ分布がその特性をうまく捉えることができます。
ガンマ分布の確率密度関数は以下の式で表されます。
ここで、
: 観測値
: スケールパラメータ(平均を含むモデル化したい部分)
: 形状パラメータ(ガンマ分布の広がりを表す)
: ガンマ関数
スケールパラメータ は回帰モデルにおける説明変数 によってモデル化されると仮定します。
回帰モデルを次のように定義します。
は説明変数のベクトル、 は回帰係数のベクトルです。
各観測値 に対するガンマ分布の確率密度関数を使い、全体の尤度関数は以下のように表されます。
この式を展開すると次のようになります。
対数尤度関数を求めます。
最尤推定の問題は次のように定式化されます。
尤度を最大化するために、 と に関する尤度関数の偏微分(勾配)を計算し、その勾配がゼロになる点を見つけます。この勾配を使って、パラメータを推定します。
これらの勾配をゼロにすることで、最尤推定値 と を得ます。
以下に scipy の最尤推定クラスを使って回帰モデルを推定するコードを紹介します。
# reg_calc_glm_mle.py
# ガンマ分布に従うGLMに対する最尤推定
import numpy as np
import pandas as pd
from scipy.optimize import minimize
from scipy.stats import gamma
# データの生成
np.random.seed(42)
n_samples = 100
X = np.random.randn(n_samples, 2) # 2つの説明変数を持つ
beta_true = np.array([0.5, -1.0]) # 真の係数
eta = X @ beta_true # 線形予測子
mu = np.exp(eta) # ガンマ分布に対する指数リンク関数
shape_param = 2.0 # ガンマ分布の形状パラメータ(k)
y = gamma.rvs(shape_param, scale=mu / shape_param, size=n_samples) # 応答変数
# 真の係数、平均、分散の表示
print("真の回帰係数:", beta_true)
print("真の平均:", mu.mean())
print("真の分散:", (mu**2 / shape_param).mean())
# 対数尤度関数の定義
def log_likelihood(beta, X, y, shape_param):
eta = X @ beta # 線形予測子
mu = np.exp(eta) # 指数リンク関数を使用
# ガンマ分布の負の対数尤度
ll = -np.sum(gamma.logpdf(y, a=shape_param, scale=mu / shape_param))
return ll
# 初期値の設定
beta_init = np.zeros(X.shape[1])
# 最適化による推定
result = minimize(log_likelihood, beta_init, args=(X, y, shape_param))
# 結果の表示
beta_est = result.x
print("推定された回帰係数:", beta_est)
# 主要な母数(平均、分散など)の計算
eta_est = X @ beta_est
mu_est = np.exp(eta_est) # 推定された平均
var_est = mu_est**2 / shape_param # ガンマ分布の分散
print("推定された平均:", mu_est.mean())
print("推定された分散:", var_est.mean())

8.3. 例:信用供与額の算定#
例として、ドイツにおける個人の信用リスクデータにGLMを適用してみます。このデータはKaggleにサインアップしてダウンロードすることができます。このデータは数値データとカテゴリーデータが混在しており、GLMを試してみるのに好都合です。
カラム情報を整理しておきましょう。
-
Age:年齢(数字): 借り手の年齢(数値)を示します。年齢は信用リスク評価において重要な要因です。
-
Sex:性別(テキスト): 借り手の性別を示します。値は「male」または「female」として表されます。
-
Job:職業(数値): 借り手の職業を示す数値コードです。具体的には次の通りです。 0:熟練していない非居住者、1:熟練していない居住者、2: 熟練職、3: 高度熟練職
-
Housing:住宅(テキスト): 借り手の住宅状況を示します。値は「own」「rent」「free」のいずれかです。
-
Saving accounts:貯蓄口座(テキスト): 借り手の貯蓄口座の状況を示します。値は「little」「moderate」「quite rich」「rich」として表されます。
-
Checking account:当座預金口座(数字): 借り手の当座預金口座の残高を示す数値で、マーク(DM)で表示されます。
-
Credit amount:クレジット金額(数値): 借り手が申し込んでいる信用の金額を示します。こちらもドイツマーク(DM)で表示されます。
-
Duration:期間(数値): クレジット契約の期間を示し、月数で表されます。
-
Purpose:目的(テキスト): 借り手が資金を使用する目的を示します。値は「car」「furniture/equipment」「radio/TV」「domestic appliances」「repairs」「education」「business」「vacation/others」のいずれかです。
'Credit amount'を目的変数、その他のカラムを説明変数とします。
モデルはstatsmodels.api.GLMを使用します。モデルの性能評価とユーティリティとしてscikit-learnを使いますので、事前に準備してください。インストールの方法はscikit-learnサイトを参照ください。
このサンプルコードでは、データを訓練用8割、テスト用2割に分割しています。モデルの学習を訓練データで行い、テストデータを使って、説明変数をインプットし、'Credit amount'を予測してみます。そして予測の性能評価指標として平均二乗誤差(MSE)と決定係数()を算出します。また、交差検証のコードを追加しています。交差検証(Cross-Validation)は学習モデルの性能を評価し、過学習(overfitting)や過少学習(underfitting)を防ぐための手法です。モデルが新しいデータに対してどれだけうまく一般化するか(汎化性能)を検証するのが主な目的です。
# reg_plot_glm_credit.py
#
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
import japanize_matplotlib
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import KFold
"""
german_credit_data.csv
Kaggle (https://www.kaggle.com/datasets/uciml/german-credit)よりデータをダウンロードできる。
1. **Age**:年齢(数字): 借り手の年齢(数値)を示します。年齢は信用リスク評価において重要な要因です。
2. **Sex**:性別(テキスト): 借り手の性別を示します。値は「male」または「female」として表されます。
3. **Job**:職業(数値): 借り手の職業を示す数値コードです。具体的には以下の通りです:
- 0: 熟練していない非居住者
- 1: 熟練していない居住者
- 2: 熟練職
- 3: 高度熟練職
4. **Housing**:住宅(テキスト): 借り手の住宅状況を示します。値は「own」「rent」「free」のいずれかです。
5. **Saving accounts**:貯蓄口座(テキスト): 借り手の貯蓄口座の状況を示します。値は「little」「moderate」「quite rich」「rich」として表されます。
6. **Checking account**:当座預金口座(数字): 借り手の当座預金口座の残高を示す数値で、マーク(DM)で表示されます。
7. **Credit amount**:クレジット金額(数値): 借り手が申し込んでいる信用の金額を示します。こちらもドイツマーク(DM)で表示されます。
8. **Duration**:期間(数値): クレジット契約の期間を示し、月数で表されます。
9. **Purpose**:目的(テキスト): 借り手が資金を使用する目的を示します。値は「car」「furniture/equipment」「radio/TV」「domestic appliances」「repairs」「education」「business」「vacation/others」のいずれかです。
"""
# CSVファイルの読み込み
df = pd.read_csv('german_credit_data.csv')
# ラベル無しの0 列を削除
df = df.drop(columns=['Unnamed: 0'])
# 列の削除(影響度の有無を確認するため)
#df = df.drop(columns=[])
# カテゴリデータの列をリスト化
categorical_columns = ['Sex', 'Job', 'Housing', 'Saving accounts', 'Checking account','Purpose']
# OneHotEncodingを使ってカテゴリデータをエンコード
encoder = OneHotEncoder(drop='first')
encoded = encoder.fit_transform(df[categorical_columns]).toarray()
# エンコードされたデータフレームを新たなデータフレームに変換
encoded_df = pd.DataFrame(encoded, columns=encoder.get_feature_names_out(categorical_columns))
# エンコードされたカテゴリーデータをもとのデータフレームと結合
df = df.drop(columns=categorical_columns) # 元のカテゴリーデータを削除
df = pd.concat([df, encoded_df], axis=1)
# 'Age,Duration,Credit amountを正規化する
min_value = df['Age'].min()
max_value = df['Age'].max()
df['Age'] = (df['Age'] - min_value) / (max_value - min_value)
min_value = df['Duration'].min()
max_value = df['Duration'].max()
df['Duration'] = (df['Duration'] - min_value) / (max_value - min_value)
min_value = df['Credit amount'].min()
max_value = df['Credit amount'].max()
df['Credit amount'] = (df['Credit amount'] - min_value) / (max_value - min_value)
# 説明変数と目標変数('Credit amount')の分割
X = df.drop(columns=['Credit amount'])
y = df['Credit amount']
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定数項を追加
X_train_const = sm.add_constant(X_train)
X_test_const = sm.add_constant(X_test)
# stasmodelsの一般化線形モデルを使い学習
glm_model = sm.GLM(y_train, X_train_const, family=sm.families.Gaussian())
glm_results = glm_model.fit()
# 交差検証のための設定
kf = KFold(n_splits=5, shuffle=True, random_state=42)
mse_scores = []
r2_scores = []
best_model = None
best_results = None
best_r2 = float('-inf')
best_mse = float('-inf')
best_params = None
# 交差検証
for train_index, test_index in kf.split(X):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
# 定数項を追加
X_train_const = sm.add_constant(X_train)
X_test_const = sm.add_constant(X_test)
# GLMモデルの学習
glm_model = sm.GLM(y_train, X_train_const, family=sm.families.Gaussian())
glm_results = glm_model.fit()
# 予測
# 各説明変数の回帰係数を取得
coefficients = glm_results.params
y_pred = glm_model.predict(coefficients,exog=X_test_const)
y_test_array = y_test.values
# 評価指標の計算
mse = mean_squared_error(y_test_array, y_pred)
r2 = r2_score(y_test, y_pred)
mse_scores.append(mse)
r2_scores.append(r2)
#print(f'MSE: {mse}')
#print(f'R^2 Score: {r2}')
# 最良のモデルの更新
if r2 > best_r2:
best_model = glm_model
best_results = glm_results
best_params = glm_results.params
best_mse = mse
best_r2 = r2
# 結果の表示
# モデルの要約結果を表示
print(best_results.summary())
print(f'Mean MSE: {np.mean(mse_scores)}')
print(f'Mean R^2 Score: {np.mean(r2_scores)}')
print(f'R^2 Best score: {best_r2:.2f}')
print(f'Mean Squared Error (MSE): {best_mse:.2f}')
# 各説明変数の回帰係数を取得
coefficients =best_params
# 相関の大きさでソート
sorted_coefficients = coefficients.reindex(coefficients.sort_values(ascending=True).index)
# 係数をバーチャートで可視化
plt.figure(figsize=(10, 6))
sorted_coefficients.plot(kind='barh', color='skyblue')
plt.title('ドイツ人の信用供与額に影響を与える要因')
plt.xlabel('説明変数の係数値')
plt.ylabel('説明変数')
plt.grid(True)
# マージンを調整してラベルが切れないようにする
plt.tight_layout()
plt.show()
結果のバーチャートは以下のようになりました。
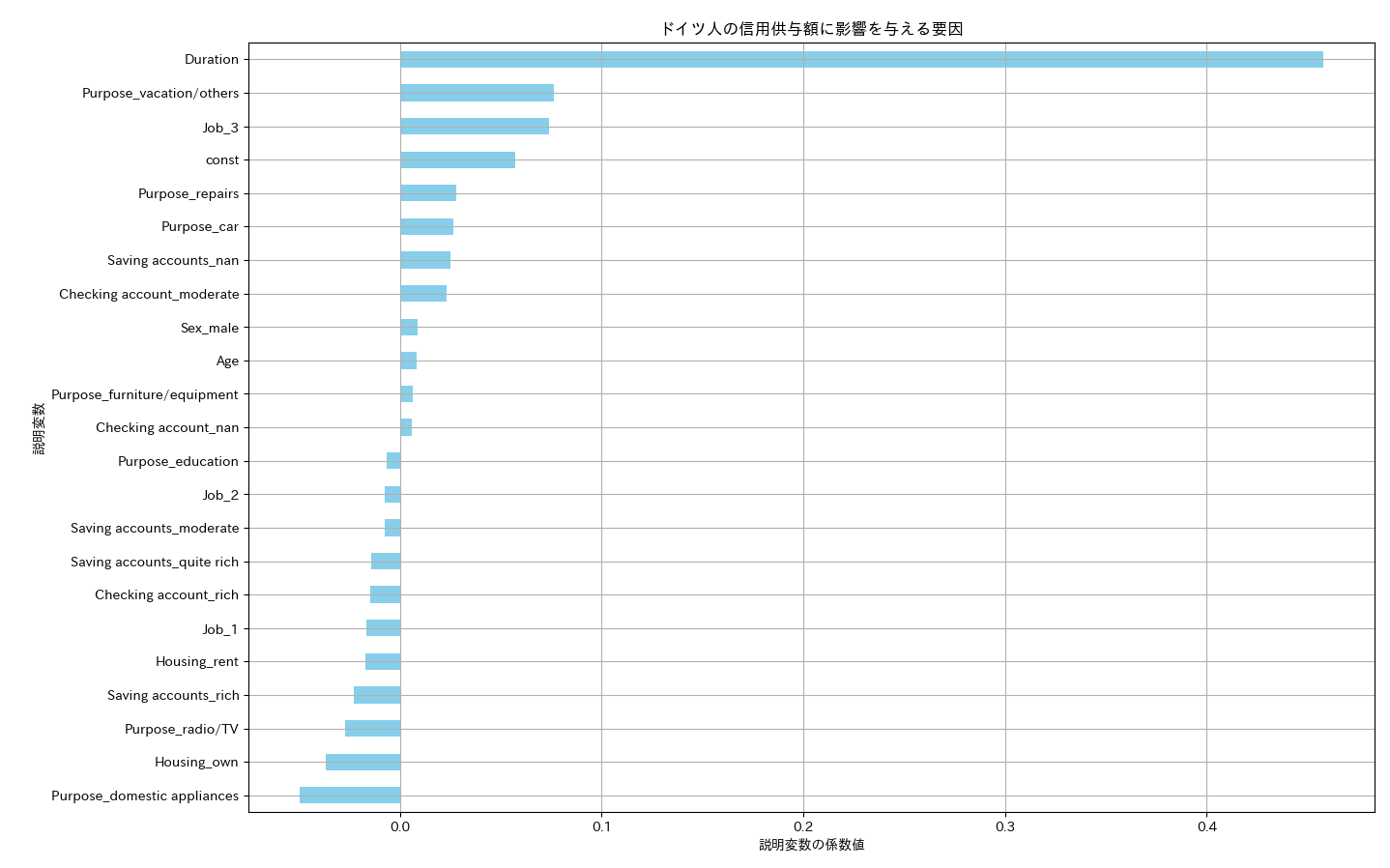
以下は、学習結果レポートと性能評価指標の値です。
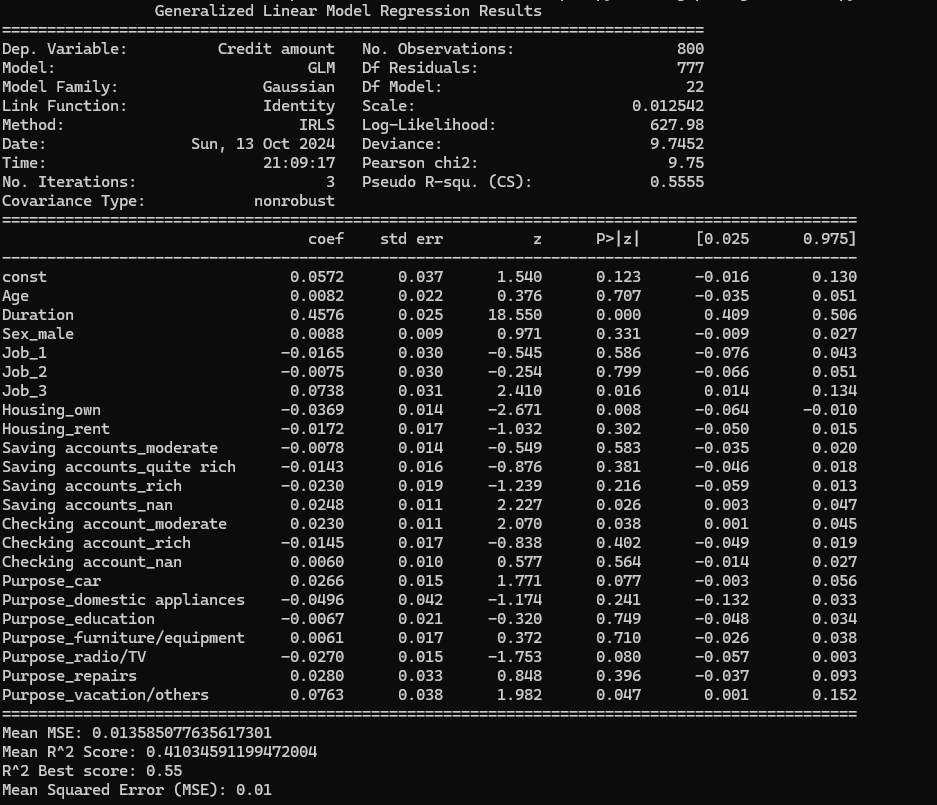
結果についていくつかコメントしておきます。 決定係数()のスコアがベストで 0.55 でということなので何かいろいろ工夫することでモデルの性能は向上するかもしれません。
バーチャートの結果を見ますと、圧倒的に、「契約期間」が信用供与額に大きな影響を与えています。鶏卵的説明になってしまいますが、そもそも信用が高くないと長期の融資は受けられない、と解釈できます。では、Purposeのvacation/othersの影響度が高いのは何故でしょう? ドイツでは欧米の通例で日本と比べて長いバケーションをとります。長いバケーションにお金を使うことのできる人は信用度が高い、と解釈することもできそうです。他にも違和感のある影響度があるのですが、それなりの解釈ができるので、なにか日本とドイツの文化的な差異を感じ取ることができて、少なからず興味深い試行であったと思います。
8.4. 時系列適用は要注意#
本稿では主に金融・経済領域の時系列データ予測に関心を向けています。一般化線形モデルを時系列分析に適用するためには少なからず注意が必要と言われています。ここでは主な考慮事項を補足します。
自己相関の考慮
時系列データでは、データ点同士が時間的に依存する「自己相関」が存在することが多いです。GLMは通常、独立した観測を前提としていますが、時系列データではこの前提が破れます。自己相関を考慮するためには、自己回帰(AR)成分を組み込むか、誤差項に対して時間依存性を導入する必要があります。具体的には、ARIMAモデルや状態空間モデルを活用するなどして、自己相関をモデル化します。自己相関を考慮した時系列を扱う技法を第4章で取り扱います。
非定常性への対応
時系列データはしばしば非定常であり、平均や分散が時間とともに変化することがあります。GLMは非定常な事象へ適用するためには、データを差分化して定常化する、あるいはトレンドや季節性を明示的にモデルに組み込むといった対処が必要となってきます。対処策の一つとしてとして、GLMとともに時間依存成分を考慮したベイズ推定を活用する方法を第4章で取り上げようと思います。
非線形性への対応
GLMは一般に線形関係を前提としていますが、時系列データには非線形な関係が存在することが多いです。非線形性を捉えるためには、GLMの代わりに非線形なモデル(例えば、GAM: Generalized Additive Model)を使用する、もしくは多項式やスプラインを説明変数として組み込むことで、モデルの柔軟性を高めることができます。本稿ではこれらの手法については特に言及しませんので適切な教科書・文献を参照ください。