第2章 確率と統計的推論
内容
人間社会の活動の結果として生じ複雑に変動する事象は、運動方程式を計算して出てくる答えのような精密な予測をすることはできません。しかし統計的推論という強力な技術の蓄積のおかげで事象の背後にある母集団の特徴を理解する道が開かれています。
1. 母集団と確率変数 本稿が想定する「母集団(Population) 」は、物理や工学の世界と同じく調査や実験を通じて値を得ることができることを前提としています。例えば「日本の全ての小学6年生の身長からなる集合」は調査によってデータを収集できるので母集団の例になります。さらに、集団の要素の数が相当に大きくなおかつ観測や調査方法の制約のため要素がとりうる値には散らばりがある(ランダム性がある)、という類の対象を想定しています。
一般に母集団の要素の数が膨大になれば調査や実験の対象を一定数以下に限定せざるを得ません。この限定の仕方に人為的、作為的な偏りが生じないように抽出された部分集団のことを無作為抽出標本(以下では簡単に「標本 」)と呼びます。標本のとりうる値全体が「標本空間 」です。そして標本を得るための調査や実験のことを本稿では「試行 」と呼ぶことにします。
母集団からn個の要素を観測する試行があったとしましょう。その要素が示す量が実数だとすれば標本空間はR n \mathbb{R}^n R n 母集団分布 」といいます。「ひとつの分布」とわざわざいう理由は、観測対象の要素が二つの変量をもっている場合、二変量を規定する分布がひとつ存在している、という考え方をするからです。
母集団の特徴を要約した定量的数値が「母数(Modulus) 」です。あるいは一般に母集団の特徴を決める量として「母集団のパラメータ 」という言葉もよく使われます。母集団 { x 1 , . . , x N } \{ x_1,..,x_N \} { x 1 , .. , x N } μ \mu μ 1 N ∑ i = 1 N x i \frac{1}{N} \sum _ {i=1} ^ N x _ i N 1 ∑ i = 1 N x i σ 2 \sigma ^2 σ 2 1 N ∑ i = 1 N ( x i − μ ) 2 \frac{1}{N} \sum _ {i=1} ^ N (x _ i - \mu) ^ 2 N 1 ∑ i = 1 N ( x i − μ ) 2 x i x _ i x i p i p _ i p i ∑ i = 1 M ( x i − μ ) k ⋅ p i \sum _ {i=1} ^ M (x _ i - \mu) ^ k \cdot p _ i ∑ i = 1 M ( x i − μ ) k ⋅ p i μ \mu μ モーメント(Moment) と呼称します。母集団の要素が連続的に分布している場合であればモーメントは次のように積分として定義します。∫ − ∞ ∞ ( x − μ ) k p ( x ) d x \int _{-\infty }^{\infty }(x-\mu )^{k}p(x)\,dx ∫ − ∞ ∞ ( x − μ ) k p ( x ) d x
一方、標本に対しても同様に特徴を要約した定量的数値を考えることができ、これを「統計量(Statistic) 」といいます。例えばモーメントを標本に対して同様に定義した統計量を標本モーメントといいます。
1.1. 確率変数 標本の無作為性は標本、さらには標本を集めた集合である標本空間 Ω \Omega Ω 事象(Event) 」と呼称します。標本は根源事象と呼ばれることもあります。「確率変数(Random variable) 」とは根源事象(標本)に対してその出現確率を対応づけた関数のことです。統計量を母集団分布に従う確率変数として扱うことには確率論の様々な知識を活用できるメリットがあります。
標本は独立同分布の確率変数の列 X = ( X 1 , X 2 , . . , X n ) X=(X_1,X_2,..,X_n ) X = ( X 1 , X 2 , .. , X n ) ( x 1 , x 2 , . . , x n ) ( x_1,x_2,..,x_n ) ( x 1 , x 2 , .. , x n ) X ‾ = ( X 1 + X 2 + . . . + X n ) / n \quad \overline{X}=(X_1+X_2+...+X_n)/n \quad X = ( X 1 + X 2 + ... + X n ) / n x ‾ = ( x 1 + x 2 + . . + x n ) / n \quad \overline{x}=(x_1+x_2+..+x_n)/n \quad x = ( x 1 + x 2 + .. + x n ) / n X ‾ \overline{X} X
一般に母数や母集団の特徴を決めるパラメータを直接計測することは困難です。なので、正しいと思われる「統計モデル 」をもとに統計量からそれらの値を推定する試みが仮説検定の大きな目的であると言えます。統計モデルという用語は時系列分析や機械学習への応用では「予測モデル 」と言われることもあるようです。
(少し長い注記)F \mathscr{F} F Ω \Omega Ω Ω , F , P \Omega,\mathscr{F},P Ω , F , P 参考1 )。確率の意味からはじまってファイナンス数理まで適度なページ数に収まっていて読み物としてもてうれしい構成の本です。F \mathscr{F} F F \mathscr{F} F
1. ∅ ∈ F 2. A ∈ F ⇒ A c ∈ F 3. { A n } n = 1 ∞ ⊂ F ⇒ ⋃ n = 1 ∞ A n ∈ F
\begin{equation}
\begin{aligned}
\text{1.} & \;\emptyset \in \mathscr{F} \\
\text{2.} & \; A \in \mathscr{F} \Rightarrow A ^c \in \mathscr{F} \\
\text{3.} & \; \{ A _ n\} _ {n=1} ^ \infty \subset \mathscr{F} \Rightarrow \bigcup _ {n=1} ^{\infty} A _ n \in \mathscr{F}
\end{aligned}
\end{equation}
1. 2. 3. ∅ ∈ F A ∈ F ⇒ A c ∈ F { A n } n = 1 ∞ ⊂ F ⇒ n = 1 ⋃ ∞ A n ∈ F
なかなか抽象的な概念なのですが、この定義から出発することで特殊な形の事象に対しても確率を積分計算により求めることできる大きなメリットがでてきます。また後の章で説明しますマルチンゲールという重要な概念の説明でも言及することになります。
一変量の確率変数
確率変数Xが離散的な場合(例えばサイコロの目の数)、値xをとる確率を関数として定めることで確率変数の性質は決まります。この関数をf X f_X f X 確率関数(あるいは確率質量関数,probability mass function,pmf) 」と呼びます。Xが従う「確率分布 」は確率関数により以下のように表現できます。
P ( a ≤ X ≤ b ) = ∑ a ≤ x ≤ b f X ( x )
\begin{equation}
P(a \le X \le b) = \sum_{a \le x \le b}f_X(x)
\end{equation}
P ( a ≤ X ≤ b ) = a ≤ x ≤ b ∑ f X ( x )
なお「Xが確率分布Pに従う」ことを慣習的に以下のように表記します。
X ∼ P
\begin{equation}
X \sim P
\end{equation}
X ∼ P
P ( X ≤ b ) \; P(X \le b)\; P ( X ≤ b ) (累積)確率分布関数(cumulative distribution function , cdf) と呼ぶことが多いので少し紛らわしい感じがしますね。 P ( X ≤ b ) = p \; P(X \le b)\;=p P ( X ≤ b ) = p パーセントポイント関数(the Percent-Point Function,ppf) と呼びます。この関数は分位関数(quantile function)あるいは逆累積分布関数(inverse cumulative distribution function,icdf)とも呼ばれ統計分析でよく使われる概念です。分位数については「補足説明 分位数 」にも少しまとめておきました。
一方、連続的な確率変数X(例えば身長や体重)に対しては、一点の出現確率はゼロになってしまうので代わりに区間の確率を積分形式で定めることで確率変数の性質は決まります。この被積分関数をf X f_X f X 確率密度関数( probability density function , pdf) 」と呼びます。確率密度関数を使い、X が従う「確率分布 」は以下のように表現できます。
P ( a ≤ X ≤ b ) = ∫ a b f X ( ω ) d ω
\begin{equation}
P(a \le X \le b) = \int_a^bf_X(\omega)d\omega
\end{equation}
P ( a ≤ X ≤ b ) = ∫ a b f X ( ω ) d ω
多変量の確率変数
サイコロとコインを同時に複数回投げる試行のように、標本の各要素を種類の異なる確率変数からなるベクトルとみなしたい場合があります。その場合標本の要素X t = ( X 1 t , . . , X n t ) \mathbb{X_t}= ( X_{1t},..,X_{nt} ) X t = ( X 1 t , .. , X n t ) 同時確率 (複数の変数の値を同時に決める意味で同時確率という)を与える確率質量関数f X ( x 1 , . . , x n ) f_X(x_1,..,x_n) f X ( x 1 , .. , x n ) X \mathbb{X} X A = A 1 × . . × A n : = { ( a 1 , . . , a n ) ∣ a 1 ∈ A 1 , . . , a N ∈ A n } A = A_1 \times..\times A_n:=\lbrace (a_1,..,a_n) \mid a_1 \in A_1,..,a_N \in A_n \rbrace A = A 1 × .. × A n := {( a 1 , .. , a n ) ∣ a 1 ∈ A 1 , .. , a N ∈ A n } f X ( x 1 , . . , x n ) f_X(x_1,..,x_n) f X ( x 1 , .. , x n )
P ( X ∈ A ) = ∑ x 1 ∈ A 1 . . . ∑ x n ∈ A n f X ( x 1 , . . , x n )
\begin{equation}
P(\mathbb{X} \in A) = \sum_{x_1 \in A_1}...\sum_{x_n \in A_n}f_X(x_1,..,x_n)
\end{equation}
P ( X ∈ A ) = x 1 ∈ A 1 ∑ ... x n ∈ A n ∑ f X ( x 1 , .. , x n )
なお以後 { X ∈ A } \lbrace \mathbb{X} \in A \rbrace { X ∈ A } { X 1 ∈ A 1 , . . , X n ∈ A n } \lbrace X_{1} \in A_1,..,X_{n} \in A_n \rbrace { X 1 ∈ A 1 , .. , X n ∈ A n }
一つの変数 X i X_i X i X i X_i X i 周辺分布 と呼びます。
P ( X 1 ∈ A 1 ) = ∑ x 1 ∈ A 1 ∑ x 2 ∈ R . . ∑ x n ∈ R f X ( x 1 , . . , x n )
\begin{equation}
P(X_1 \in A_1) = \sum_{x_1 \in A_1}\sum_{x_2 \in \mathbb{R}}..\sum_{x_n \in \mathbb{R}}f_X(x_1,..,x_n)
\end{equation}
P ( X 1 ∈ A 1 ) = x 1 ∈ A 1 ∑ x 2 ∈ R ∑ .. x n ∈ R ∑ f X ( x 1 , .. , x n )
工場ラインを流れる部品のサイズと重量を測定する試行のように標本要素が連続値の確率変数となる場合は、標本要素 X t = ( X 1 , . . . , X n ) \mathbb{X_t}= ( X_1,...,X_n ) X t = ( X 1 , ... , X n ) f X ( x 1 , . . , x n ) f_X(x_1,..,x_n) f X ( x 1 , .. , x n ) X t \mathbb{X_t} X t P ( X ∈ A ) = ∫ x 1 ∈ A 1 . . ∫ x n ∈ A n f X ( x 1 , . . , x n ) d x 1 . . d x n
\begin{equation}
P(\mathbb{X} \in A) = \int_{x_1 \in A_1}..\int_{x_n \in A_n}f_X(x_1,..,x_n)dx_1..dx_n
\end{equation}
P ( X ∈ A ) = ∫ x 1 ∈ A 1 .. ∫ x n ∈ A n f X ( x 1 , .. , x n ) d x 1 .. d x n
離散変数と同様周辺化、周辺分布を定義します。
P ( X 1 ∈ A 1 ) = ∫ x 1 ∈ A 1 ∬ R × . . × R f X ( x 1 , . . , x n ) d x 1 . . d x n
\begin{equation}
P(X_1 \in A_1) = \int_{x_1 \in A_1}\iint_{\mathbb{R} \times .. \times \mathbb{R}}f_X(x_1,..,x_n)dx_1..dx_n
\end{equation}
P ( X 1 ∈ A 1 ) = ∫ x 1 ∈ A 1 ∬ R × .. × R f X ( x 1 , .. , x n ) d x 1 .. d x n
条件付確率
確率変数 X 、確率変数 Y とするとき、Y ∈ B Y \in B Y ∈ B X ∈ A X \in A X ∈ A 条件付確率 は (同時確率 ÷ 周辺確率)として定義されます。
P ( X ∈ A ∣ Y ∈ B ) : = P ( X ∈ A , Y ∈ B ) P ( Y ∈ B )
\begin{equation}
P(X \in A| Y \in B) \;:= \; \frac{P(X \in A , Y \in B)}{P(Y \in B)}
\end{equation}
P ( X ∈ A ∣ Y ∈ B ) := P ( Y ∈ B ) P ( X ∈ A , Y ∈ B )
これに対応する条件付確率質量関数(連続値のときは確率密度関数)に関する定義式を以下のように表記します。
f X ∣ Y ( x ∣ y ) : = f X , Y ( x , y ) f Y ( y )
\begin{equation}
f_{X|Y}(x|y) \;:= \; \frac{f_{X,Y}(x,y)}{f_Y(y)}
\end{equation}
f X ∣ Y ( x ∣ y ) := f Y ( y ) f X , Y ( x , y )
また、f f f θ \theta θ f ( x ; θ ) f(x;\theta) f ( x ; θ )
確率変数に関する基本的な定義
確率変数に対しては頻出する重要な量がいくつかあるので以下に定義を書いておきます。 : = \;:= \; :=
【一変量確率変数】
確率変数Xを平均 μ \mu μ 期待値 E ( X ) E(X) E ( X ) 分散 V ( X ) V(X) V ( X ) { Y = y } \{Y=y\} { Y = y } 条件付き期待値 E ( X ∣ Y = y ) E(X|Y=y) E ( X ∣ Y = y )
Xが離散確率変数の場合:
E ( X ) : = ∑ x ∈ R : P ( x ) > 0 P ( x ) V ( X ) : = E ( ( X − μ ) 2 ) : = ∑ x ∈ R : P ( x ) > 0 ( x − μ ) 2 P ( x ) E ( X ∣ Y = y ) : = ∑ a a P ( X = a ∣ Y = y )
\begin{equation}
\begin{aligned}
E(X) & := \sum_{x\in R:P(x)>0}P(x) \\
V(X) & := E((X-\mu)^2) := \sum_{x\in R:P(x)>0}(x-\mu)^2P(x) \\
E(X|Y=y)\; & := \;\sum_a a P(X=a \mid Y=y)
\end{aligned}
\end{equation}
E ( X ) V ( X ) E ( X ∣ Y = y ) := x ∈ R : P ( x ) > 0 ∑ P ( x ) := E (( X − μ ) 2 ) := x ∈ R : P ( x ) > 0 ∑ ( x − μ ) 2 P ( x ) := a ∑ a P ( X = a ∣ Y = y )
Xが連続確率変数の場合:
E ( X ) : = ∫ − ∞ + ∞ x f X ( x ) d x V ( X ) : = E ( ( X − μ ) 2 ) : = ∫ − ∞ + ∞ ( x − μ ) 2 f X ( x ) d x E ( X ∣ Y = y ) : = ∫ − ∞ + ∞ x f X ∣ Y ( x ∣ y ) d x
\begin{equation}
\begin{aligned}
E(X) & := \int_{-\infty}^{+\infty}xf_X(x)dx \\
V(X) & := E((X-\mu)^2) := \int_{-\infty}^{+\infty}(x-\mu)^2f_{X}(x)dx \\
E(X|Y=y)\; & := \int_{-\infty}^{+\infty}xf_{X|Y}(x|y)dx
\end{aligned}
\end{equation}
E ( X ) V ( X ) E ( X ∣ Y = y ) := ∫ − ∞ + ∞ x f X ( x ) d x := E (( X − μ ) 2 ) := ∫ − ∞ + ∞ ( x − μ ) 2 f X ( x ) d x := ∫ − ∞ + ∞ x f X ∣ Y ( x ∣ y ) d x
【多変量確率変数】X = ( X , Y ) T \mathbb{X} = (X,Y)^T X = ( X , Y ) T ( μ X , μ Y ) T (\mu_X,\mu_Y)^T ( μ X , μ Y ) T X \mathbb{X} X E ( X ) E(\mathbb{X}) E ( X ) V ( X ) V(\mathbb{X}) V ( X ) C o v ( X ) Cov(\mathbb{X}) C o v ( X ) C o v ( X , Y ) Cov(X,Y) C o v ( X , Y ) ρ X Y \rho_{XY} ρ X Y
E ( X ) : = ( E ( X ) , E ( Y ) ) T V ( X ) : = ( V ( X ) , V ( Y ) ) T C o v ( X ) : = E [ ( X − E [ X ] ) ( X − E [ X ] ) T ] : = ( V ( X ) C o v ( X , Y ) C o v ( Y , X ) V ( Y ) )
\begin{equation}
\begin{aligned}
E(\mathbb{X}) &:= (E(X),E(Y))^T \\
V(\mathbb{X}) &:= (V(X),V(Y))^T \\
Cov(\mathbb{X}) & := E[(\mathbb{X} - E[\mathbb{X}])(\mathbb{X} - E[\mathbb{X}])^T] \\
& := \begin{pmatrix}
V(X) & Cov(X,Y) \\
Cov(Y,X) & V(Y)
\end{pmatrix}
\end{aligned}
\end{equation}
E ( X ) V ( X ) C o v ( X ) := ( E ( X ) , E ( Y ) ) T := ( V ( X ) , V ( Y ) ) T := E [( X − E [ X ]) ( X − E [ X ] ) T ] := ( V ( X ) C o v ( Y , X ) C o v ( X , Y ) V ( Y ) )
共分散 C o v ( X , Y ) Cov(X,Y) C o v ( X , Y ) C o v ( X , Y ) : = ∑ x ∈ R : P ( x ) > 0 ∑ y ∈ R : P ( y ) > 0 ( x − μ X ) ( y − μ Y ) P ( x , y )
\begin{equation}
Cov(X,Y) := \sum_{x\in R:P(x)>0}\sum_{y\in R:P(y)>0}(x-\mu_X)(y-\mu_Y)P(x,y)
\end{equation}
C o v ( X , Y ) := x ∈ R : P ( x ) > 0 ∑ y ∈ R : P ( y ) > 0 ∑ ( x − μ X ) ( y − μ Y ) P ( x , y )
X,Y が連続確率変数の場合の共分散は、
C o v ( X , Y ) : = ∬ − ∞ + ∞ ( x − μ X ) ( y − μ Y ) f X Y ( x , y ) d x d y
\begin{equation}
Cov(X,Y) := \iint_{-\infty}^{+\infty}(x-\mu_X)(y-\mu_Y)f_{XY}(x,y)dxdy
\end{equation}
C o v ( X , Y ) := ∬ − ∞ + ∞ ( x − μ X ) ( y − μ Y ) f X Y ( x , y ) d x d y
相関係数は、
ρ X Y : = C o v ( X , Y ) V ( X ) V ( Y )
\begin{equation}
\rho_{XY} := \frac{Cov(X,Y)}{\sqrt{V(X)}\sqrt{V(Y)}}
\end{equation}
ρ X Y := V ( X ) V ( Y ) C o v ( X , Y )
役に立つ知識
確率変数に関して知っておくと後々確率に関わる計算や定理をフォローするときに役立つ基本知識を解説無しにあげておきます。詳しくは確率の教科書を参照してください。
E ( X Y ) = E ( X ) E ( Y ) V ( X + Y ) = V ( X ) + V ( Y )
\begin{equation}
\begin{aligned}
E(XY) = E(X)E(Y) \\
V(X+Y) = V(X) + V(Y)
\end{aligned}
\end{equation}
E ( X Y ) = E ( X ) E ( Y ) V ( X + Y ) = V ( X ) + V ( Y )
上記加法性をつかうと、互いに独立でかつ同分布の確率変数列 X 1 , X 2 , . . X_1,X_2,.. X 1 , X 2 , .. μ \mu μ σ \sigma σ X ˉ = 1 n ( X 1 + . . . + X n ) \bar{X} = \frac{1}{n}(X_1+...+X_n) X ˉ = n 1 ( X 1 + ... + X n )
E ( X ˉ ) = σ V ( X ˉ ) = σ 2 n
\begin{equation}
\begin{aligned}
E(\bar{X}) = \sigma \\
V(\bar{X}) = \frac{\sigma^2}{n}
\end{aligned}
\end{equation}
E ( X ˉ ) = σ V ( X ˉ ) = n σ 2
V ( X ) = E ( X 2 ) − E ( X ) 2
\begin{equation}
\begin{aligned}
V(X) = E(X^2) - E(X)^2
\end{aligned}
\end{equation}
V ( X ) = E ( X 2 ) − E ( X ) 2
確率変数列X n , Y n X_n,Y_n X n , Y n
X n → P X , Y n → P Y ならば X n + Y n → P X + Y X n → P X , Y n → P Y ならば X n Y n → P X Y X n → P X , Y n → P Y , Y ≠ 0 ならば X n / Y n → P X / Y
\begin{equation}
\begin{aligned}
X _ n \rightarrow _ {P} X,Y _ n \rightarrow _ {P} Y \text{ならば} \quad X _ n + Y _ n \rightarrow _ {P} X+Y \\
X _ n \rightarrow _ {P} X,Y _ n \rightarrow _ {P} Y \text{ならば} \quad X _ n Y _ n \rightarrow _ {P} XY \\
X _ n \rightarrow _ {P} X,Y _ n \rightarrow _ {P} Y,Y \neq 0 \text{ならば} \quad X _ n / Y _ n \rightarrow _ {P} X / Y
\end{aligned}
\end{equation}
X n → P X , Y n → P Y ならば X n + Y n → P X + Y X n → P X , Y n → P Y ならば X n Y n → P X Y X n → P X , Y n → P Y , Y = 0 ならば X n / Y n → P X / Y
(連続写像定理)確率変数列 X n X_n X n g ( ) g() g ( )
X n → P X ならば g ( X n ) → P g ( X )
\begin{equation}
\begin{aligned}
X_n \rightarrow_{P} X \text{ならば} \quad g(X_n) \rightarrow_{P} g(X)
\end{aligned}
\end{equation}
X n → P X ならば g ( X n ) → P g ( X )
E ( Y ) = ∑ a ∈ A E ( Y ∣ X = a ) P ( X = a )
\begin{equation}
\begin{aligned}
E(Y) \;= \; \sum_{a\in A}E(\;Y\;|\;X = a \; )\;P(X = a )
\end{aligned}
\end{equation}
E ( Y ) = a ∈ A ∑ E ( Y ∣ X = a ) P ( X = a )
事象の集合計算
確率変数 X X X x x x A A A X X X t ( X ) t(X) t ( X ) t ( X ) t(X) t ( X ) t ( x ) t(x) t ( x ) B B B P ( A ∩ B ) = P ( A ) P(A \cap B) = P(A) P ( A ∩ B ) = P ( A ) X X X x x x A A A t ( X ) t(X) t ( X ) t ( x ) t(x) t ( x ) B B B
A = { ω : X ( ω ) = x } B = { ω : t ( X ( ω ) ) = t ( x ) }
\begin{equation}
\begin{aligned}
A &= \{ \omega : X(\omega) = x \} \\
B &= \{ \omega : t(X(\omega)) = t(x) \}
\end{aligned}
\end{equation}
A B = { ω : X ( ω ) = x } = { ω : t ( X ( ω )) = t ( x )}
B B B t ( X ) t(X) t ( X ) X ( ω ) = x X(\omega) = x X ( ω ) = x t ( X ( ω ) ) = t ( x ) t(X(\omega)) = t(x) t ( X ( ω )) = t ( x ) ω ∈ A \omega \in A ω ∈ A ω ∈ B \omega \in B ω ∈ B A ⊆ B A \subseteq B A ⊆ B A ∩ B = A A \cap B = A A ∩ B = A
補足説明 確率・統計 のなかで二項分布、正規分布など基本的かつ重要な確率分布の事例を掲載していますので適宜参照ください。
1.2. 大数の法則と中心極限定理 標本 X = ( X 1 , X 2 , . . , X n ) X = (X_1,X_2,..,X_n ) X = ( X 1 , X 2 , .. , X n ) X ‾ = ( X 1 + . . . + X n ) / n \overline{X}=(X_1+...+X_n)/n X = ( X 1 + ... + X n ) / n X ‾ \overline{X} X E ( X ‾ ) E(\overline{X}) E ( X ) μ \mu μ V ( X ‾ ) V(\overline{X}) V ( X ) σ 2 \sigma^2 σ 2 大数の法則 」とよぶ)は標本サイズ n が大きくなるにつれて標本平均 X ‾ \overline{X} X μ \mu μ
lim n → ∞ P ( ∣ X ‾ − μ ∣ < ϵ ) = 1 ϵ は正の任意の数
\begin{equation}
\begin{aligned}
\lim_{n \to \infty} P(∣\overline{X}-\mu∣ < \epsilon) = 1 \quad \epsilon \ \text{は正の任意の数}
\end{aligned}
\end{equation}
n → ∞ lim P ( ∣ X − μ ∣< ϵ ) = 1 ϵ は正の任意の数
あるいは用語的な表現では、X ‾ \overline{X} X μ \mu μ 確率収束 する、と言い以下のように表します。
X ‾ → P μ
\begin{equation}
\begin{aligned}
\overline{X} \quad \rightarrow_P \quad \mu
\end{aligned}
\end{equation}
X → P μ
X ‾ \overline{X} X 漸近正規性 」を有すると表現されます。
X ‾ \overline{X} X N ( μ , σ 2 / n ) N(\mu,\sigma^2/n) N ( μ , σ 2 / n ) 中心極限定理 」として知られています。標準化されたスケールで表すと
Z = X ‾ − μ σ / n とおいたとき
\begin{equation}
\begin{aligned}
Z = \frac{\overline{X}-\mu}{\sigma / \sqrt{n}}\quad \text{とおいたとき}
\end{aligned}
\end{equation}
Z = σ / n X − μ とおいたとき
lim n → ∞ P ( Z < z ) = ∫ − ∞ z 1 2 π e − x 2 2 d x
\begin{equation}
\begin{aligned}
\lim_{n \to \infty} P(Z < z) = \int_{-\infty}^{z}\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}} dx
\end{aligned}
\end{equation}
n → ∞ lim P ( Z < z ) = ∫ − ∞ z 2 π 1 e − 2 x 2 d x
あるいは用語的な表現では、Z Z Z 分布収束 する、と言い以下のように表します。
Z → d N ( 0 , 1 )
\begin{equation}
\begin{aligned}
Z \quad \rightarrow_d \quad N(0,1)
\end{aligned}
\end{equation}
Z → d N ( 0 , 1 )
分布収束は法則収束 と呼ばれることもあります。元の集団が正規分布に従っていてもいなくても、標本サイズ(標本の要素数のこと) n が大きくなるにつれ標本平均の分布が正規分布に近づいていていくという事実はきわめて有用です。
大数の法則と中心極限定理について 補足説明 確率・統計 に補足していますので参照ください。
2. 統計的推論の基本知識 2.1. 推定の分類学 「推定(estimation) 」とは、統計量をもとに、正しいと考えられる統計モデルに基づいて母集団のパラメータ値を推測する試みです。この推測のために標本において定義した統計量を「推定量(estimator) 」とよびます。
「何を」推定するのか、そしてそれを「どのように」推定するのか、という観点で全然網羅的ではありませんが推定の技法の例を以下の表に整理してみました。
何を1
どのように1
どのように2
モデル例
点推定
パラメトリック
モーメント法
点推定
パラメトリック
最小二乗法
線形回帰モデル、ロジスティック回帰モデル、多項式回帰モデル、一般化線形モデル
点推定
パラメトリック
最尤法
線形回帰モデル、一般化線形モデル、一般化線形混合モデル
点推定
パラメトリック
ベイズ推定
階層ベイズモデル
点推定
パラメトリック
ロバスト推定
線形回帰モデル
点推定
パラメトリック
一般化モーメント法
資産価格モデル、動学的パネルデータモデル
点推定
ノンパラメトリック
カーネル密度推定
ガウスカーネル、エパネチニコフカーネル
区間推定
信頼区間
点推定の各種モデル
区間推定
ベイズ信頼区間
ベイズ推定のモデル
推定の対象を母数等、母集団のパラメータとするのが点推定、推定の確からしさを数値の幅をもって表現するのが区間推定です。この大別に基づいて以降の節は構成されます。
パラメトリック推定は、母集団の分布関数を具体的に仮定し、関数形を特定するためのパラメータを推定する手法です。分布関数は正規分布、二項分布、ポアソン分布等、用途に応じて実に様々な関数形が考案されています。一方、ノンパラメトリック分布は特定の関数形を用いず観測データから近似的な分布を構成し、観測数を増やすことで近似の精度を高めていく手法です。これらの手法の特徴と差異について後節で説明します。
ロバスト推定
2.2. 一致性、不偏性、有効性 一般に母集団全体を計測できない限り母数は不明なので「推定」という作業が必要となるわけです。そうすると推定量を計算して得られる推定値がもっともらしいものであることを定量的に測り推定作業の良し悪しを判断する尺度が必要となります。それが表題に現れる三つのキーワードです。
標本サイズが増大するにつれて推定量が真のパラメータに収束することを「統計的推定の一致性 」といい、そのような推定量を「一致推定量(Consistent estimator) 」と呼称します。前述のように母集団と標本の性質から大数の法則が成立するので標本平均 X ‾ \overline{X} X
標本平均はその期待値が母平均と一致しています。このように母集団の真のパラメータ値と標本の推定量の期待値が一致する場合、これを「不偏推定量(Unbiased estimator) 」と呼びます。また、母集団の真のパラメータ値と推定量の差異を「バイアス(bias) 」と呼びます。
一方、標本分散 V ( X ) = 1 n ∑ i n ( X i − X ‾ ) 2 V( X ) = \frac{1}{n}\sum_i^n(X _ i -\overline{X})^2 V ( X ) = n 1 ∑ i n ( X i − X ) 2 ( n − 1 ) n σ 2 \frac{(n-1)}{n}\sigma^2 n ( n − 1 ) σ 2 n → ∞ n \rightarrow \infty n → ∞ 証明はこちら )。このように、不偏推定量にはなっていないが標本サイズが大きくなるにつれ推定量の期待値が母集団の真のパラメータに収束する場合その推定量は「漸近不偏性(asymptotic unbiasedness) 」を有するといいます。
まとめると、標本サイズを n、z を母集団のパラメータ、Z ^ \hat{Z} Z ^
推定量 θ ^ \hat{\theta} θ ^ θ 0 \theta_0 θ 0
θ ^ → p θ 0 ( n → ∞ )
\hat{\theta} \; \underset{p}{\operatorname{\rightarrow}} \theta_0 \;\;(n \rightarrow \infty )
θ ^ p → θ 0 ( n → ∞ )
推定量 Z Z Z z z z
E ( Z ^ ) = z
E(\hat{Z}) = z
E ( Z ^ ) = z
推定量 Z Z Z z z z
E ( Z ^ ) → p z
E(\hat{Z}) \; \underset{p}{\operatorname{\rightarrow}} \;z
E ( Z ^ ) p → z
不偏推定量は分析のために非常に有用な性質ですが、不偏推定量Aに対して期待値ゼロの統計量Yを足したA+Bも不偏推定量になります。つまり、ひとつの母数に対してユニークに不偏推定量が決まるわけではない点注意が必要です。ある母数に対して複数の不偏推定量があったときに、選択の指針になるのが「有効性(efficiency) 」という概念です。有効性の尺度としては分散の大小を見ると良いといわれています。なおefficiencyは「効率性 」と訳されることもあります。
不偏推定量 X の有効性が高い := 分散 V ( X ) が小さい
上述した標本平均は母平均に対する最小の不偏推定量になっていることを証明できます。このような不偏推定量を「一様最小分散不偏推定量(Uniformly Minimum Variance Unbiased Estimator,UMVUE) 」、あるいは簡単に「有効推定量 」と呼びます。有効推定量が存在する場合の下限値も知られています。
クラメール-ラオ(Cramér-Rao)の不等式 θ \theta θ θ ^ \hat{\theta} θ ^
V ( θ ^ ) ≥ 1 I ( θ )
\begin{equation}
V(\hat{\theta}) \quad \ge \quad \frac{1}{I(\theta)}
\end{equation}
V ( θ ^ ) ≥ I ( θ ) 1
ここでは下限が存在するという事実だけを記載しておきます。フィッシャー情報量など詳細は統計学の教科書を参照してください。
漸近不偏性を有する推定量の分散がクラメール-ラオの下限値に収束するとき「漸近有効性(Asymptotic efficiency) 」を有するといいます。
漸近不偏性があれば大きな標本サイズでの推定の信頼性が高まると言えます。漸近有効性があれば大きな標本サイズでより小さな分散を得ることができます(つまり、より精度の高い推定ができる)。推定量の漸近性はそのような有用性を主張しています。
2.3. 点推定 「点推定(Point Estimation) 」は、母集団のパラメータに対して単一の値(真の値)を推定する方法です。一般的な点推定方法には、最尤推定や最小二乗推定などがあります。以下主要な推定手法と具体的な使用例を見ていきましょう。
モーメント法 モーメント法(Method of Moments,MM ) は母集団の統計モデルにおいて成立する k 次モーメント(k=1,2,..)の関係式は標本においても成立する(あるいはほぼ成立する)はず、とのもっともらしい考え方に基づいます。この関係式をモーメント条件式とよび、標本モーメントで置き換えたモーメント条件式を解いて得られるパラメータを母数の推定量とする方法です。
確率変数 X X X k k k モーメント条件式 と呼ぶことにします。
E ( X k ) − m k ( θ ) = 0
\begin{equation}
E(X^k) - m_k(\theta) = 0
\end{equation}
E ( X k ) − m k ( θ ) = 0
ここで、m k ( θ ) m_k(\theta) m k ( θ ) θ \theta θ
step1. 理論モーメントの導出:
統計モデルに基づいて、パラメータ θ \theta θ
E [ X 」 − m 1 ( θ ) = 0 E [ X 2 ] − m 2 ( θ ) = 0
\begin{equation}
\begin{aligned}
& E[X」- m_1(\theta) = 0\\
& E[X^2] - m_2(\theta) = 0
\end{aligned}
\end{equation}
E [ X 」 − m 1 ( θ ) = 0 E [ X 2 ] − m 2 ( θ ) = 0
step2. 標本モーメントの計算:
観測データ { x 1 , x 2 , … , x n } \{x_1, x_2, \ldots, x_n\} { x 1 , x 2 , … , x n }
s ^ 1 : = 1 n ∑ i = 1 n x i s ^ 2 : = 1 n ∑ i = 1 n x i 2
\begin{equation}
\begin{aligned}
&\hat{s}_1 := \frac{1}{n} \sum_{i=1}^n x_i \\
&\hat{s}_2 := \frac{1}{n} \sum_{i=1}^n x_i^2
\end{aligned}
\end{equation}
s ^ 1 := n 1 i = 1 ∑ n x i s ^ 2 := n 1 i = 1 ∑ n x i 2
step3. モーメント条件式の設定:
モーメント条件式を標本モーメントにより置き換えた方程式の解がパラメータの推定値 θ ^ \hat{\theta} θ ^
s ^ 1 − m 1 ( θ ^ ) = 0 s ^ 2 − m 2 ( θ ^ ) = 0
\begin{equation}
\begin{aligned}
&\hat{s}_1 - m_1(\hat{\theta}) = 0\\
&\hat{s}_2 - m_2(\hat{\theta}) = 0
\end{aligned}
\end{equation}
s ^ 1 − m 1 ( θ ^ ) = 0 s ^ 2 − m 2 ( θ ^ ) = 0
一般の次数では以下のように表現できます。
1 n ∑ i = 1 n x i k − m k ( θ ^ ) = 0
\begin{equation}
\frac{1}{n} \sum_{i=1}^n x_i^k - m_k(\hat{\theta}) = 0
\end{equation}
n 1 i = 1 ∑ n x i k − m k ( θ ^ ) = 0
step4. パラメータの推定:
モーメント条件式を解くことによってパラメータ θ \theta θ
理論モーメントと標本モーメントを一致させるだけなので、モーメント法の実装は比較的簡単です。また、多くの異なる分布やモデルに適用可能です。
一方、モーメント法による推定量は、標本サイズに依存するため、後述する最尤法(MLE)と比較して効率性が劣ることがあります。特に、標本サイズが小さい場合バイアスが大きくなることは否めません。さらに、そもそもモーメント条件式の解が存在しない、または一意でない場合がありますので適用する標本サイズに対する配慮が必要です。
モーメント法による推定の例
例として母集団分布がパラメータ a , b a,b a , b μ \mu μ σ 2 \sigma^2 σ 2
f ( x ) = { 1 b − a if a ≤ x ≤ b 0 otherwise
\begin{equation}
\begin{aligned}
f(x) = \begin{cases} \frac{1}{b-a} & \text{if } a \leq x \leq b \\
0 & \text{otherwise} \end{cases}
\end{aligned}
\end{equation}
f ( x ) = { b − a 1 0 if a ≤ x ≤ b otherwise
μ = a + b 2 , σ 2 = ( b − a ) 2 12
\begin{equation}
\mu = \frac{a+b}{2}, \quad \sigma^2 = \frac{(b-a)^2}{12}
\end{equation}
μ = 2 a + b , σ 2 = 12 ( b − a ) 2
標本モーメントは算術平均によりあらわされるので、標本を { X 1 , . . , X n } \{ X _ 1,..,X _ n\} { X 1 , .. , X n } s ^ 1 , s ^ 2 \hat{s}_1,\hat{s}_2 s ^ 1 , s ^ 2
s ^ 1 : = X ˉ = 1 n ∑ i = 1 n X i s ^ 2 : = 1 n ∑ i = 1 n ( X i − μ ^ ) 2
\begin{equation}
\begin{aligned}
\hat{s}_1 &:= \bar{X} = \frac{1}{n}\sum _ {i=1} ^ n X _ i \\
\hat{s}_2 &:= \frac{1}{n}\sum _ {i=1} ^ n (X _ i - \hat{\mu})^2
\end{aligned}
\end{equation}
s ^ 1 s ^ 2 := X ˉ = n 1 i = 1 ∑ n X i := n 1 i = 1 ∑ n ( X i − μ ^ ) 2
標本モーメントに対してモーメント条件式が成立すると考えるので a , b a,b a , b a ^ , b ^ \hat{a},\hat{b} a ^ , b ^
1 n ∑ i = 1 n X i − a ^ + b ^ 2 = 0 1 n ∑ i = 1 n ( X i − X ˉ ) 2 − ( b ^ − a ^ ) 2 12 = 0
\begin{equation}
\begin{aligned}
\frac{1}{n}\sum _ {i=1} ^ n X _ i - \frac{\hat{a}+\hat{b}}{2} = 0 \\
\frac{1}{n}\sum _ {i=1} ^ n (X _ i - \bar{X})^2 - \frac{(\hat{b}-\hat{a})^2}{12} = 0
\end{aligned}
\end{equation}
n 1 i = 1 ∑ n X i − 2 a ^ + b ^ = 0 n 1 i = 1 ∑ n ( X i − X ˉ ) 2 − 12 ( b ^ − a ^ ) 2 = 0
簡単な式変形とa ≤ μ ≤ b a \le \mu \le b a ≤ μ ≤ b
a ^ = X ˉ − 3 n ∑ i = 1 n ( X i − X ˉ 2 ) b ^ = X ˉ + 3 n ∑ i = 1 n ( X i − X ˉ 2 )
\begin{equation}
\begin{aligned}
\hat{a} &= \bar{X} - \sqrt{ \frac{3}{n}\sum _ {i=1} ^ n ( X _ i - \bar{X} ^ 2)} \\
\hat{b} &= \bar{X} + \sqrt{ \frac{3}{n}\sum _ {i=1} ^ n ( X _ i - \bar{X} ^ 2)}
\end{aligned}
\end{equation}
a ^ b ^ = X ˉ − n 3 i = 1 ∑ n ( X i − X ˉ 2 ) = X ˉ + n 3 i = 1 ∑ n ( X i − X ˉ 2 )
モーメント法の考え方はシンプルで強力ですが、金融・経済分野で使われる統計モデルでは、モーメント条件式を構成したとき、パラメータ数よりもモーメント条件式の数が多くなることがしばしばあります。これは過剰適合(Over indentification)と呼ばれ、ここであげたモーメント法のようにパラメータ数とモーメント条件式の数が等しいことを前提とする手法ではうまく対処できません。
そこでハンセン(1982年)は以下のようにモーメント条件式の考え方を大きく見直すことで、非常に多くの応用に適用できる手法を提案しました。これは一般化モーメント法(Generalized Method of Moments,GMM) とよばれています。 本書ではこの手法は取り扱わないため詳しくは計量経済学の教科書などを参照ください。
一般化モーメント法
モーメント条件式を統計量 g k ( X , θ ) : = X k − m k \ g _ k (X,\theta) := X^k - m_k g k ( X , θ ) := X k − m k
E [ g k ( X , θ ) ] = 0 w h e r e k = 1 , 2
\begin{equation}
E[g _ k (X,\theta)] = 0 \;\; where \; k=1,2
\end{equation}
E [ g k ( X , θ )] = 0 w h ere k = 1 , 2
古典的なモーメント法では各モーメント次数に対してこの方程式の右辺がゼロになることを要請するところが過剰適合の原因の根源でした。そこでこの対策としてモーメント条件式を以下のように緩和する見直しを行います。
モーメント条件式をつくる統計量 g k ( X , Θ ) g _ k ( X,\Theta ) g k ( X , Θ ) Θ = { θ 1 , . . , θ L } \Theta = \{\theta_1,..,\theta_L \} Θ = { θ 1 , .. , θ L } L < K L \lt K L < K
g k ( Θ ) : = E [ g k ( X , Θ ) ] w h e r e k = 1 , 2 , . . , K
\begin{equation}
\begin{aligned}
g _k ( \Theta ) & := E [ g _ k ( X,\Theta )] \;\; where \; k=1,2,..,K
\end{aligned}
\end{equation}
g k ( Θ ) := E [ g k ( X , Θ )] w h ere k = 1 , 2 , .. , K
g k {g_k} g k g ( Θ ) g(\Theta) g ( Θ )
g ( Θ ) : = ∑ k = 1 K g k ( Θ ) T w k ( Θ ) g k ( Θ )
\begin{equation}
\begin{aligned}
g( \Theta ) & := \sum _ {k=1} ^ K g _k( \Theta ) ^ T w _ k(\Theta) g _k( \Theta )
\end{aligned}
\end{equation}
g ( Θ ) := k = 1 ∑ K g k ( Θ ) T w k ( Θ ) g k ( Θ )
w k ( Θ ) w_k(\Theta) w k ( Θ ) このもとで、g ( Θ ) g(\Theta) g ( Θ ) Θ ^ \hat{\Theta} Θ ^
Θ ^ : = argmin Θ g ( Θ )
\begin{equation}
\begin{aligned}
\hat{ \Theta} & := \underset{\Theta}{\operatorname{argmin}} \; g( \Theta)
\end{aligned}
\end{equation}
Θ ^ := Θ argmin g ( Θ )
前述の一様分布に対するモーメント法の例は、重み係数が 1 で、各モーメント条件式がゼロになること、 g 1 = 0 , g 2 = 0 g_1 = 0,g_2 = 0 g 1 = 0 , g 2 = 0
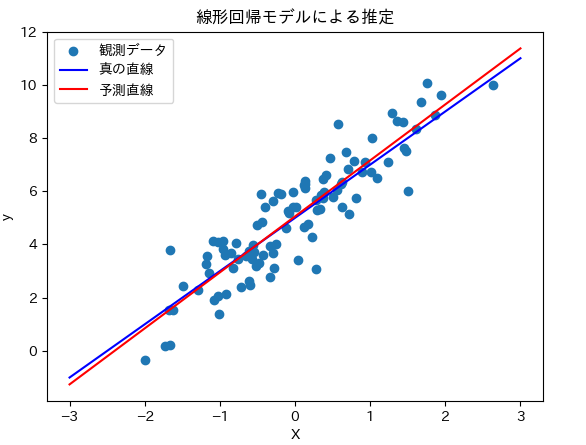
最小二乗法推定 最小二乗法推定(Ordinary Least Squares Estimation, OLSEあるいは単にLSE) は、観測データである実現値とモデルの予測値との誤差の二乗和を最小化するパラメータを母集団のパラメータの推定値とする手法です。幅広い予測モデルへ適用できるポピュラーな手法です。以下に線形回帰モデルを例とし、モデル式の切片と回帰係数を母集団のパラメータと考え最小二乗法により推定するプログラムを statsmodels のサンプルコードを紹介します。
#
# stat_estim_ols1.py
# テスト生成データを使い線形回帰モデルに対して最小二乗法推定を行う
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
import japanize_matplotlib
# サンプルデータ生成
np . random . seed ( 9876789 )
X0 = np . random . normal ( 0 , 0.9 , size = 100 ) # 正規分布に従った数値を観測データとして100個生成
y = 2 * X0 + 5 + np . random . randn ( 100 ) # 真の直線が傾き2、切片5になるよう係数を調整
# 線形回帰モデルクラス(OLS:Ordinary Least Squares)による最小二乗法推定
X = sm . add_constant ( X0 ) # 説明変数として定数項を第0列に挿入
res = sm . OLS ( y , X ) . fit () # 予測を実行
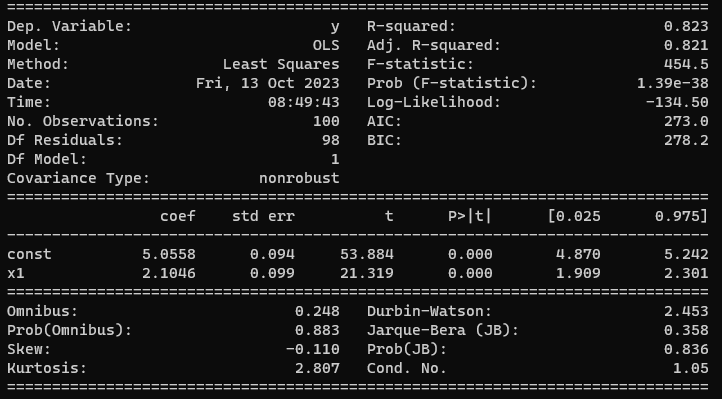
print ( res . summary ()) # パラメータ推定結果の表示
# 予測直線のパラメータを取得
intercept , slope = res . params
# プロット用のデータ
x_values = np . linspace ( - 3 , 3 , 100 ) # プロット用のX値(-2から2まで)
y_predicted = intercept + slope * x_values # 予測直線の式
Y = 2 * np . linspace ( - 3 , 3 , 100 ) + 5 # 真の直線の式
# プロット
plt . scatter ( X [:, 1 ], y , label = '観測データ' ) # サンプルデータ点の散布図
plt . plot ( x_values , Y , color = 'blue' , label = '真の直線' ) # 真の直線
plt . plot ( x_values , y_predicted , color = 'red' , label = '予測直線' ) # 予測直線
plt . xlabel ( 'X' )
plt . ylabel ( 'y' )
plt . legend ()
plt . title ( '線形回帰' )
plt . show ()
これを実行したときの処理結果レポート
レポートの各項目の意味については 補足説明 ソフトウェアを準備する に説明をつけているので参照ください。
回帰モデルにおける最小二乗法推定が非常によい性質を持っていることが知られています。これについては第3章で補足します。
最尤推定法 母集団分布の形 f ( x ; θ ) f(x;θ) f ( x ; θ ) θ \theta θ θ \theta θ f f f θ \theta θ μ \mu μ σ 2 \sigma^2 σ 2 最尤推定法(Maximum Likelihood Estimation, MLE) 」では、試行により標本 X の観測データ x = ( x 1 , . . . , x n ) x=(x_1,...,x_n) x = ( x 1 , ... , x n ) L ( θ ; x ) L(\theta;x) L ( θ ; x ) θ \theta θ
θ M L E = argmax θ L ( θ ; x )
\begin{equation}
\theta_{MLE}=\underset{\theta}{\operatorname{argmax}} \; L(\theta;x)
\end{equation}
θ M L E = θ argmax L ( θ ; x )
ここで arg max θ \underset{\theta}{\operatorname{\argmax}} θ arg max θ \theta θ θ \theta θ
母集団のパラメータが一つではなく複数の場合は多変量関数L ( θ 1 , . . . , θ m ) L(\theta_1,...,\theta_m) L ( θ 1 , ... , θ m )
最尤推定法の基本的なステップを示します。
step1. 尤度関数の設定:
まず、母集団のパラメータ θ \theta θ θ \theta θ L ( x ; θ ) L(x;\theta) L ( x ; θ ) 尤度関数(Likelihood Function) 」と呼びます。この関数は、与えられたパラメータに対して、観測データが得られる確率を与えるものであるため、母集団の確率密度関数(pdf)、あるいは離散型確率変数の時は確率質量関数、(pmf)の積として構成することができます。なお記述を短くするために以下の議論は連続型確率変数を前提とします。観測データをx = { x 1 , . . . , x n } x=\{x_1,...,x_n\} x = { x 1 , ... , x n } f X ( x i ; θ ) f_X(x_i;\theta) f X ( x i ; θ )
L ( θ ; x ) = f X ( x 1 ; θ ) f X ( x 2 ; θ ) . . . f X ( x n ; θ ) = ∏ i = 1 n f X ( x i ; θ )
\begin{equation}
L(\theta;x) = f _ X (x_1;θ)f _ X (x_2;θ)...f _ X (x_n;θ) = \prod_{i=1}^{n}f _ X (x_i;θ)
\end{equation}
L ( θ ; x ) = f X ( x 1 ; θ ) f X ( x 2 ; θ ) ... f X ( x n ; θ ) = i = 1 ∏ n f X ( x i ; θ )
例えば X X X
L ( μ , σ 2 ; x ) = 1 2 π σ 2 exp ( − ∑ i = 1 n ( x i − μ ) 2 2 σ 2 )
\begin{equation}
L(\mu,\sigma^2;x)= \frac{1}{\sqrt{2\pi\sigma^2}}\exp(-\frac{\sum_{i=1}^n(x_i-\mu)^2}{2\sigma^2})
\end{equation}
L ( μ , σ 2 ; x ) = 2 π σ 2 1 exp ( − 2 σ 2 ∑ i = 1 n ( x i − μ ) 2 )
step2. 対数尤度関数への変換:
尤度関数を対数変換して計算を簡単にし、数値的な見通しをよくすることができます。このステップにより、母集団分布関数の積が対数和に変換されます。
log L ( μ , σ 2 ; x ) = − n 2 log ( 2 π ) − n 2 log ( σ 2 ) − 1 2 σ 2 ∑ i = 1 n ( x i − μ ) 2
\begin{equation}
\log L(\mu,\sigma^2;x) = -\frac{n}{2}\log( 2\pi ) -\frac{n}{2}\log( \sigma^2 ) -\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2
\end{equation}
log L ( μ , σ 2 ; x ) = − 2 n log ( 2 π ) − 2 n log ( σ 2 ) − 2 σ 2 1 i = 1 ∑ n ( x i − μ ) 2
step3. argmaxの計算:
対数尤度関数を最大化するパラメータ θ \theta θ μ \mu μ σ 2 σ^2 σ 2 μ \mu μ μ \mu μ μ ^ \hat{\mu} μ ^
∂ ∂ μ log ( L ( μ , σ 2 ; x ) ) = 0
\begin{equation}
\frac{ \partial }{ \partial \mu} \log ( L ( \mu,\sigma^2;x) ) = 0
\end{equation}
∂ μ ∂ log ( L ( μ , σ 2 ; x )) = 0
μ \mu μ
− 1 σ 2 ∑ i = 1 n ( x i − μ ) = 0
\begin{equation}
-\frac{1}{\sigma^2}\sum_{i=1}^n(x_i-\mu) = 0
\end{equation}
− σ 2 1 i = 1 ∑ n ( x i − μ ) = 0
これを変形することで最尤推定値 μ ^ \hat{\mu} μ ^
μ ^ = 1 n ∑ i = 1 n ( x i )
\begin{equation}
\hat{\mu} = \frac{1}{n}\sum_{i=1}^n(x_i)
\end{equation}
μ ^ = n 1 i = 1 ∑ n ( x i )
同じように σ 2 \sigma^2 σ 2 σ 2 \sigma^2 σ 2 σ 2 ^ \hat{\sigma^2} σ 2 ^
∂ ∂ σ 2 log ( L ( μ , σ 2 ; x ) ) = 0
\begin{equation}
\frac{\partial }{\partial \sigma^2}\log (L(\mu,\sigma^2;x)) = 0
\end{equation}
∂ σ 2 ∂ log ( L ( μ , σ 2 ; x )) = 0
log ( p ) \log(p) log ( p )
− n 2 1 σ 2 + 1 ( σ 2 ) 2 ∑ i = 1 n ( x i − μ ) = 0
\begin{equation}
-\frac{n}{2}\frac{1}{\sigma^2}+\frac{1}{(\sigma^2)^2}\sum_{i=1}^n(x_i-\mu) = 0
\end{equation}
− 2 n σ 2 1 + ( σ 2 ) 2 1 i = 1 ∑ n ( x i − μ ) = 0
これを変形することで最尤推定値 σ 2 ^ \hat{\sigma^2} σ 2 ^
σ 2 ^ = 1 n ∑ i = 1 n ( x i − μ ) 2
\begin{equation}
\hat{\sigma^2} = \frac{1}{n}\sum_{i=1}^n(x_i-\mu)^2
\end{equation}
σ 2 ^ = n 1 i = 1 ∑ n ( x i − μ ) 2
step4. 推定されたパラメータの利用:
最尤推定法によって得られたパラメータの値を使用して、統計モデルの予測、推論、モデル適合度の評価などを行います。
科学技術計算用ライブラリ scipy を使って実際に最尤推定を行ってみましょう。まずscipyをインストールします。
以下は scipy の minimize 関数を活用した最尤推定のサンプルコードです。
# stat_estim_mle1.py
# 正規分布の平均を最尤推定する
#
import numpy as np
from scipy.stats import norm
from scipy.optimize import minimize
# 標本の生成
loc = 5 # 分布の平均値
scale = 2 # 分布の標準偏差
np . random . seed ( 0 )
data = np . random . normal ( loc = loc , scale = scale , size = 100 )
# 尤度関数から対数尤度関数へ変換
def negative_log_likelihood ( params , data ):
mu = params [ 0 ] # 推定したい平均
# norm.pdf 確率密度関数
# loc 平均値 scale 標準偏差
likelihood = norm . pdf ( data , loc = mu , scale = 1 )
log_likelihood = np . log ( likelihood )
return - np . sum ( log_likelihood )
# 最適化を用いて最尤推定を行う
initial_guess = [ 0.0 ] # 初期値
result = minimize ( negative_log_likelihood , initial_guess , args = ( data ,))
mu_mle = result . x [ 0 ] # 最尤推定された平均
print ( f "ランダム生成した標本の平均値: { loc } 最尤推定された平均: { mu_mle : .2f } " )
最尤推定が示す重要な性質
最尤推定は、先にあげた推定における重要な三つの条件(一致性、不偏性、有効性)を含め、以下のように優れた特徴を示すことが知られています。
一致性
最尤推定量 θ ^ \hat{\theta} θ ^ θ ^ \hat{\theta} θ ^ θ 0 \theta_0 θ 0
θ ^ → p θ 0 ( n → ∞ )
\hat{\theta} \; \underset{p}{\operatorname{\rightarrow}} \theta_0 \;\;(n \rightarrow \infty )
θ ^ p → θ 0 ( n → ∞ )
一致性のための正則性条件
パラメータ空間がコンパクトであり、最尤推定量は有限となること。
尤度関数が識別可能である、言い換えれば異なるパラメータが異なる確率分布を生成すること。
標本対数尤度関数 1 n log L n ( θ ) \frac{1}{n} \log L_n(\theta) n 1 log L n ( θ ) E [ log L ( θ ) ] E[\log L(\theta)] E [ log L ( θ )]
真のパラメータで連続的に最大化されること。lim θ → θ 0 1 n log L n ( θ ) = 1 n log L n \lim_{\theta \to \theta_0} \frac{1}{n} \log L_n(\theta) = \frac{1}{n} \log L_n lim θ → θ 0 n 1 log L n ( θ ) = n 1 log L n
尤度関数 L n ( θ ) L_n(\theta) L n ( θ ) θ \theta θ
漸近正規性
漸近正規性(Asymptotic Normality)とは、以下に記す正則性条件のもとで、標本サイズが大きくなるにつれて、最尤推定量の分布が正規分布に近づく性質を指します。
n ( θ ^ − θ 0 ) → d N ( 0 , I − 1 ( θ 0 ) )
\begin{equation}
\sqrt{n} (\hat{\theta} - \theta_0) \xrightarrow{d} N(0, I^{-1}(\theta_0))
\end{equation}
n ( θ ^ − θ 0 ) d N ( 0 , I − 1 ( θ 0 ))
漸近正規性のための正則性条件
- 対数尤度関数が一階および二階微分可能であり、真のパラメータ周りで適切な近似が可能であること。0 0 0_0 0 0 𝐼 ( θ 0 ) − 1 𝐼(\theta_0)^{-1} I ( θ 0 ) − 1
この正則性条件は、真のパラメータの周りで正規分布に従うための条件であり、尤度関数の滑らかさやスコア関数の正則性が必要となります。
この事実は、最尤推定量が大きな標本サイズにおいて、平均 θ \theta θ I − 1 ( θ ) / n I^{-1}(\theta) / n I − 1 ( θ ) / n
漸近不偏性
漸近不偏性は、十分大きな標本サイズで推定量が不偏性を示すとみなせることを主張します。つまり、
lim n → ∞ E [ θ ^ ] = θ 0
\lim_{n \to \infty} E[\hat{\theta}] = \theta_0
n → ∞ lim E [ θ ^ ] = θ 0
一般に最尤推定量は、不偏推定量にはなりませんが、正則性条件の下で漸近不偏性を満足することを証明することができます。
この事実は、前出の漸近正規性からの帰結です。
n ( θ ^ − θ 0 ) → d N ( 0 , I ( θ 0 ) − 1 )
\sqrt{n} (\hat{\theta} - \theta_0) \xrightarrow{d} N\left(0, I(\theta_0)^{-1}\right)
n ( θ ^ − θ 0 ) d N ( 0 , I ( θ 0 ) − 1 )
従って、
θ ^ ≃ θ 0 + 1 n Z
\hat{\theta} \simeq \theta_0 + \frac{1}{\sqrt{n}} Z
θ ^ ≃ θ 0 + n 1 Z
ここで、 Z ∼ N ( 0 , I ( θ 0 ) − 1 ) Z \sim N(0, I(\theta_0)^{-1}) Z ∼ N ( 0 , I ( θ 0 ) − 1 )
期待値をとれば、
E [ θ ^ ] ≃ E [ θ 0 + 1 n Z ] = θ 0 + 1 n E [ Z ]
E[\hat{\theta}] \simeq E\left[\theta_0 + \frac{1}{\sqrt{n}} Z\right] = \theta_0 + \frac{1}{\sqrt{n}} E[Z]
E [ θ ^ ] ≃ E [ θ 0 + n 1 Z ] = θ 0 + n 1 E [ Z ]
n → ∞ n \rightarrow \infty n → ∞
E [ θ ^ ] → θ 0
E[\hat{\theta}] \rightarrow \theta_0
E [ θ ^ ] → θ 0
漸近有効性
Cramér-Raoの不等式は、不偏推定量の分散には下限値が存在することを示すものです。
V ( θ ^ ) ≥ 1 I ( θ 0 )
\begin{equation}
V(\hat{\theta}) \quad \ge \quad \frac{1}{I(\theta_0)}
\end{equation}
V ( θ ^ ) ≥ I ( θ 0 ) 1
先に示した漸近不偏性は、最尤推定量の分散が下限値へ収束する、漸近有効性を有することを主張しています。
n → ∞ then V ( θ ^ ) → 1 I ( θ 0 )
\begin{equation}
n \rightarrow \infty \;\text{then}\; V(\hat{\theta}) \quad \rightarrow \quad \frac{1}{I(\theta_0)}
\end{equation}
n → ∞ then V ( θ ^ ) → I ( θ 0 ) 1
十分統計量
まず最尤推定に関わる重要な統計量である「十分統計量」、そして十分統計量に関する重要な定理を紹介しておきます。
【十分統計量の定義】
標本 X の統計量 T = t ( X ) T=t(X) T = t ( X ) T T T t ( x ) t(x) t ( x ) X X X x x x P θ ( X = x ∣ t ( X ) = t ( x ) ) P _ \theta (X=x \mid t(X)=t(x)) P θ ( X = x ∣ t ( X ) = t ( x )) θ \theta θ T T T θ \theta θ T T T θ \theta θ
Tが十分統計量であることを式で表現すると、
⟺ P θ ( X = x ∣ t ( X ) = t ( x ) ) = P ( X = x ∣ t ( X ) = t ( x ) ) ⟺ f X ∣ T ( x ∣ t ( x ) ; θ ) = f X ∣ T ( x ∣ t ( x ) )
\begin{equation}
\begin{aligned}
& \Longleftrightarrow P_ \theta (X=x\mid t(X)=t(x))=P(X=x\mid t(X)=t(x)) \\
& \Longleftrightarrow f_{X|T}(x|t(x);\theta) = f_{X|T}(x|t(x))
\end{aligned}
\end{equation}
⟺ P θ ( X = x ∣ t ( X ) = t ( x )) = P ( X = x ∣ t ( X ) = t ( x )) ⟺ f X ∣ T ( x ∣ t ( x ) ; θ ) = f X ∣ T ( x ∣ t ( x ))
十分統計量は観測データから母数 θ \theta θ
例として母集団分布がベルヌーイ分布の場合の十分統計量を考えてみましょう。
独立したベルヌーイ試行を n 回繰り返す試行の標本を X = ( X 1 , X 2 , … , X n ) X=(X_1, X_2, \ldots, X_n) X = ( X 1 , X 2 , … , X n )
f X ( x i ; p ) = p x i ( 1 − p ) 1 − x i
\begin{equation}
f_X(x_i; p) = p^{x_i} (1-p)^{1-x_i}
\end{equation}
f X ( x i ; p ) = p x i ( 1 − p ) 1 − x i
標本 X X X t ( X ) = ∑ i = 1 n X i t(X) = \sum_{i=1}^n X_i t ( X ) = ∑ i = 1 n X i X X X t ( X ) t(X) t ( X ) p p p L ( p ; X ) L(p;X) L ( p ; X )
P p ( X = x ) = ∏ i = 1 n p x i ( 1 − p ) 1 − x i = p ∑ i = 1 n x i ( 1 − p ) n − ∑ i = 1 n x i = p t ( x ) ( 1 − p ) n − t ( x ) = p t ( x ) ( 1 − p ) n − t ( x ) 1 ( t ( X ) = t ( x ) ) = P p ( X = x , t ( X ) = t ( x ) )
\begin{equation}
\begin{aligned}
P _ p (X=x) &= \prod_{i=1}^n p^{x_i} (1-p)^{1-x_i} \\
&= p^{\sum_{i=1}^n x_i} (1-p)^{n - \sum_{i=1}^n x_i} \\
&= p^{t(x)} (1-p)^{n - t(x)} \\
&= p^{t(x)} (1-p)^{n - t(x)} \mathbf{1}(t(X)=t(x)) \\
&= P _ p (X=x,t(X)=t(x))
\end{aligned}
\end{equation}
P p ( X = x ) = i = 1 ∏ n p x i ( 1 − p ) 1 − x i = p ∑ i = 1 n x i ( 1 − p ) n − ∑ i = 1 n x i = p t ( x ) ( 1 − p ) n − t ( x ) = p t ( x ) ( 1 − p ) n − t ( x ) 1 ( t ( X ) = t ( x )) = P p ( X = x , t ( X ) = t ( x ))
上記で 1 ( t ( X ) = t ( x ) ) \mathbf{1}(t(X)=t(x)) 1 ( t ( X ) = t ( x )) t ( X ) = t ( x ) t(X) = t(x) t ( X ) = t ( x ) x i x_i x i t ( X ) t(X) t ( X )
条件付分布の定義から、
P p ( X = x ∣ t ( X ) = t ( x ) ) = P p ( X = x , t ( X ) = t ( x ) ) P p ( t ( X ) = t ( x ) ) = P p ( X = x ) P p ( t ( X ) = t ( x ) )
\begin{equation}
\begin{aligned}
P _ p (X = x | t(X) = t(x)) &= \frac{P _ p (X = x, t(X) = t(x))}{P _ p (t(X) = t(x))} \\
&= \frac{P _ p (X = x )}{P _ p (t(X) = t(x))}
\end{aligned}
\end{equation}
P p ( X = x ∣ t ( X ) = t ( x )) = P p ( t ( X ) = t ( x )) P p ( X = x , t ( X ) = t ( x )) = P p ( t ( X ) = t ( x )) P p ( X = x )
分母の P p ( t ( X ) = t ( x ) ) P _ p (t(X) = t(x) ) P p ( t ( X ) = t ( x ))
P p ( t ( X ) = t ( x ) ) = ( n t ( x ) ) p t ( x ) ( 1 − p ) n − t ( x )
\begin{equation}
P _ p (t(X) = t(x)) = \binom{n}{t(x)} p^{t(x)} (1-p)^{n-t(x)}
\end{equation}
P p ( t ( X ) = t ( x )) = ( t ( x ) n ) p t ( x ) ( 1 − p ) n − t ( x )
これを用いると、条件付き分布は次のように書けます。
P p ( X = x ∣ t ( X ) = t ( x ) ) = p t ( x ) ( 1 − p ) n − t ( x ) 1 ( t ( X ) = t ( x ) ) ( n t ( x ) ) p t ( x ) ( 1 − p ) n − t ( x ) = 1 ( t ( X ) = t ( x ) ) ( n t ( x ) )
\begin{equation}
\begin{aligned}
P_p(X = x | t(X) = t(x)) &= \frac{p^{t(x)} (1-p)^{n - t(x)} \mathbf{1}(t(X)=t(x)) }{\binom{n}{t(x)} p^{t(x)} (1-p)^{n-t(x)}} \\
&= \frac{\mathbf{1}(t(X)=t(x))}{\binom{n}{t(x)}}
\end{aligned}
\end{equation}
P p ( X = x ∣ t ( X ) = t ( x )) = ( t ( x ) n ) p t ( x ) ( 1 − p ) n − t ( x ) p t ( x ) ( 1 − p ) n − t ( x ) 1 ( t ( X ) = t ( x )) = ( t ( x ) n ) 1 ( t ( X ) = t ( x ))
これは、パラメータ p p p t ( X ) = ∑ i = 1 n X i t(X) = \sum_{i=1}^n X_i t ( X ) = ∑ i = 1 n X i p p p
次の因子分解定理は、十分統計量を見つけるための方法を与えてくれます。
Fisher-Neymanの因子分解定理
X の確率密度関数(離散的な場合には確率質量関数)を f X ( x ; θ ) f_X(x ;\theta) f X ( x ; θ ) T T T θ \theta θ
f X ( x 1 , . . , x n ; θ ) = g ( t ( x ) ; θ ) h ( x )
\begin{equation}
f_X(x_1,..,x_n;\theta) = g(t(x); \theta) h(x)
\end{equation}
f X ( x 1 , .. , x n ; θ ) = g ( t ( x ) ; θ ) h ( x )
証明は補足説明 確率・統計 を参照ください。
パラメータ θ \theta θ
最小十分統計量
統計量 T を パラメータ θ \theta θ θ \theta θ T = h ( U ) T = h(U) T = h ( U )
このような都合のよい T が存在するのであれば明らかに いろいろな十分統計量を探さずとも最初から T を使うことが効率的です。
【最小十分統計量を見つける方法】
f X ( x ; θ ) f_X (x;θ) f X ( x ; θ ) t ( X ) t(X) t ( X )
任意の二つの観測データ x と y について,T ( x ) = T ( y ) T (x) = T (y) T ( x ) = T ( y ) f X ( x ; θ ) / f X ( y ; θ ) f_X(x;θ) / f _X (y;θ) f X ( x ; θ ) / f X ( y ; θ ) θ \theta θ
T ( x ) = T ( y ) ⟺ f X ( x ; θ ) / f X ( y ; θ ) がθに依存しない ⟺ L ( θ ; x ) / L ( θ ; y ) がθに依存しない
\begin{equation}
\begin{aligned}
& T (x) = T (y) \\
\Longleftrightarrow & f_X(x;θ) / f _X (y;θ) \;\; \text{がθに依存しない} \\
\Longleftrightarrow & L(θ;x) / L (θ;y) \;\; \text{がθに依存しない}
\end{aligned}
\end{equation}
⟺ ⟺ T ( x ) = T ( y ) f X ( x ; θ ) / f X ( y ; θ ) が θ に依存しない L ( θ ; x ) / L ( θ ; y ) が θ に依存しない
証明は専門の確率論の教科書を参照ください。この事実を用いて最小十分統計量を見つけることができます。
尤度比を使用して最小十分統計量を見つける手順:
観測データ x x x L ( θ ; x ) L(\theta; x) L ( θ ; x )
2つの異なる値 x 1 x_1 x 1 x 2 x_2 x 2
L ( θ ; x 1 ) L ( θ ; x 2 )
\begin{equation}
\frac{L(\theta; x_1)}{L(\theta; x_2)}
\end{equation}
L ( θ ; x 2 ) L ( θ ; x 1 )
尤度比が θ \theta θ θ \theta θ x x x
この同値クラスを定義する統計量が最小十分統計量です。
例:母集団分布が正規分布の場合
仮に X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X 1 , X 2 , … , X n μ \mu μ σ 2 \sigma^2 σ 2 N ( μ , σ 2 ) N(\mu, \sigma^2) N ( μ , σ 2 )
L ( μ , σ 2 ; x ) = ( 1 2 π σ 2 ) n exp ( − 1 2 σ 2 ∑ i = 1 n ( X i − μ ) 2 )
\begin{equation}
L(\mu, \sigma^2; x) = \left(\frac{1}{\sqrt{2 \pi \sigma^2}}\right)^n \exp\left(-\frac{1}{2\sigma^2} \sum_{i=1}^n (X_i - \mu)^2\right)
\end{equation}
L ( μ , σ 2 ; x ) = ( 2 π σ 2 1 ) n exp ( − 2 σ 2 1 i = 1 ∑ n ( X i − μ ) 2 )
2つのサンプル x 1 x_1 x 1 x 2 x_2 x 2
L ( μ , σ 2 ; x 1 ) L ( μ , σ 2 ; x 2 ) = exp ( − 1 2 σ 2 [ ∑ i = 1 n ( x 1 i − μ ) 2 − ∑ i = 1 n ( x 2 i − μ ) 2 ] ) = exp ( − 1 2 σ 2 [ ∑ i = 1 n x 1 i 2 − ∑ i = 1 n x 2 i 2 + 2 μ ( ∑ i = 1 n x 1 i − ∑ i = 1 n x 2 i ) ] )
\begin{equation}
\begin{aligned}
\frac{L(\mu, \sigma^2; x_1)}{L(\mu, \sigma^2; x_2)} &= \exp\left(-\frac{1}{2\sigma^2} \left[\sum_{i=1}^n (x_{1i} - \mu)^2 - \sum_{i=1}^n (x_{2i} - \mu)^2\right]\right) \\
&= \exp\left(-\frac{1}{2\sigma^2} \left[ \sum_{i=1}^n x_{1i}^2 - \sum_{i=1}^n x_{2i}^2 + 2 \mu( \sum_{i=1}^n x_{1i} - \sum_{i=1}^n x_{2i} )\right]\right)
\end{aligned}
\end{equation}
L ( μ , σ 2 ; x 2 ) L ( μ , σ 2 ; x 1 ) = exp ( − 2 σ 2 1 [ i = 1 ∑ n ( x 1 i − μ ) 2 − i = 1 ∑ n ( x 2 i − μ ) 2 ] ) = exp ( − 2 σ 2 1 [ i = 1 ∑ n x 1 i 2 − i = 1 ∑ n x 2 i 2 + 2 μ ( i = 1 ∑ n x 1 i − i = 1 ∑ n x 2 i ) ] )
尤度比がパラメータ μ \mu μ
∑ i = 1 n x 1 i = ∑ i = 1 n x 2 i
\begin{equation}
\sum_{i=1}^n x_{1i} = \sum_{i=1}^n x_{2i}
\end{equation}
i = 1 ∑ n x 1 i = i = 1 ∑ n x 2 i
従って、μ \mu μ ∑ i = 1 n X i \sum_{i=1}^n X_{i} ∑ i = 1 n X i
また、尤度比がパラメータ σ 2 \sigma^2 σ 2
∑ i = 1 n x 1 i = ∑ i = 1 n x 2 i and ∑ i = 1 n x 1 i 2 = ∑ i = 1 n x 2 i 2
\begin{equation}
\sum_{i=1}^n x_{1i} = \sum_{i=1}^n x_{2i} \;\;\text{and}\;\; \sum_{i=1}^n x_{1i}^2 = \sum_{i=1}^n x_{2i}^2
\end{equation}
i = 1 ∑ n x 1 i = i = 1 ∑ n x 2 i and i = 1 ∑ n x 1 i 2 = i = 1 ∑ n x 2 i 2
従って、σ 2 \sigma^2 σ 2 ( ∑ i = 1 n X i , ∑ i = 1 n X i 2 ) (\sum_{i=1}^n X_{i},\sum_{i=1}^n X_{i}^2) ( ∑ i = 1 n X i , ∑ i = 1 n X i 2 )
十分統計量 t ( X ) t(X) t ( X ) P ( X ∣ T ) P(X|T) P ( X ∣ T ) θ \theta θ t ( X ) t(X) t ( X ) θ \theta θ t ( X ) t(X) t ( X )
θ M L E = argmax θ L T ( θ ; x ) = argmax θ h ( x ) g ( t ( X ) , θ )
\begin{equation}
\theta_{MLE}= \underset{\theta}{\operatorname{argmax}} \; L_T(\theta;x) = \underset{\theta}{\operatorname{argmax}} \; h(x)\,g(t(X),\theta )
\end{equation}
θ M L E = θ argmax L T ( θ ; x ) = θ argmax h ( x ) g ( t ( X ) , θ )
最小十分統計量を使い最尤推定する
母集団分布が前出のベルヌーイ分布の場合を例とします。
ベルヌーイ分布の尤度関数は次の通りです:
L ( θ ; X ) = ∏ i = 1 n θ X i ( 1 − θ ) 1 − X i
\begin{equation}
L(\theta; X) = \prod_{i=1}^n \theta^{X_i} (1 - \theta)^{1 - X_i}
\end{equation}
L ( θ ; X ) = i = 1 ∏ n θ X i ( 1 − θ ) 1 − X i
因子分解定理により、尤度関数は次の形に因子分解できます:
L ( θ ; X ) = θ ∑ i = 1 n X i ( 1 − θ ) n − ∑ i = 1 n X i
\begin{equation}
L(\theta; X) = \theta^{\sum_{i=1}^n X_i} (1 - \theta)^{n - \sum_{i=1}^n X_i}
\end{equation}
L ( θ ; X ) = θ ∑ i = 1 n X i ( 1 − θ ) n − ∑ i = 1 n X i
尤度比を作ります。
L ( μ , σ 2 ; x 1 ) L ( μ , σ 2 ; x 2 ) = θ ∑ i = 1 n x 1 i ( 1 − θ ) n − ∑ i = 1 n x 1 i θ ∑ i = 1 n x 2 i ( 1 − θ ) n − ∑ i = 1 n x 2 i = ( θ 1 − θ ) ∑ i = 1 n x 1 i − ∑ i = 1 n x 2 i
\begin{equation}
\begin{aligned}
\frac{L(\mu, \sigma^2; x_1)}{L(\mu, \sigma^2; x_2)} &= \frac{\theta^{\sum_{i=1}^n x_{1i}} (1 - \theta)^{n - \sum_{i=1}^n x_{1i}}}{\theta^{\sum_{i=1}^n x_{2i}} (1 - \theta)^{n - \sum_{i=1}^n x_{2i}}} \\
&= (\frac{\theta}{1-\theta})^{\sum_{i=1}^n x_{1i}-\sum_{i=1}^n x_{2i}}
\end{aligned}
\end{equation}
L ( μ , σ 2 ; x 2 ) L ( μ , σ 2 ; x 1 ) = θ ∑ i = 1 n x 2 i ( 1 − θ ) n − ∑ i = 1 n x 2 i θ ∑ i = 1 n x 1 i ( 1 − θ ) n − ∑ i = 1 n x 1 i = ( 1 − θ θ ) ∑ i = 1 n x 1 i − ∑ i = 1 n x 2 i
尤度比がパラメータ θ \theta θ
∑ i = 1 n x 1 i = ∑ i = 1 n x 2 i
\begin{equation}
\sum_{i=1}^n x_{1i} = \sum_{i=1}^n x_{2i}
\end{equation}
i = 1 ∑ n x 1 i = i = 1 ∑ n x 2 i
従って、θ \theta θ ∑ i = 1 n X i \sum_{i=1}^n X_{i} ∑ i = 1 n X i
最小十分統計量 t ( X ) = ∑ i = 1 n X i t(X) = \sum_{i=1}^n X_i t ( X ) = ∑ i = 1 n X i
L ( θ ; t ( X ) ) = θ t ( X ) ( 1 − θ ) n − t ( X )
\begin{equation}
L(\theta; t(X)) = \theta^{t(X)} (1 - \theta)^{n - t(X)}
\end{equation}
L ( θ ; t ( X )) = θ t ( X ) ( 1 − θ ) n − t ( X )
尤度関数を最大化するために、対数尤度関数を考えます:
log L ( θ ; t ( X ) ) = t ( X ) log θ + ( n − t ( X ) ) log ( 1 − θ )
\begin{equation}
\log L(\theta; t(X)) = t(X) \log \theta + (n - t(X)) \log (1 - \theta)
\end{equation}
log L ( θ ; t ( X )) = t ( X ) log θ + ( n − t ( X )) log ( 1 − θ )
対数尤度関数の θ \theta θ
d d θ log L ( θ ; t ( X ) ) = t ( X ) θ − n − t ( X ) 1 − θ = 0
\begin{equation}
\frac{d}{d\theta} \log L(\theta; t(X)) = \frac{t(X)}{\theta} - \frac{n - t(X)}{1 - \theta} = 0
\end{equation}
d θ d log L ( θ ; t ( X )) = θ t ( X ) − 1 − θ n − t ( X ) = 0
これを解くと、最尤推定量 $\hat{\theta}$ は次のようになります:
θ ^ = t ( X ) n = ∑ i = 1 n X i n
\begin{equation}
\hat{\theta} = \frac{t(X)}{n} = \frac{\sum_{i=1}^n X_i}{n}
\end{equation}
θ ^ = n t ( X ) = n ∑ i = 1 n X i
小標本サイズでの留意点 最尤推定法(MLE)が大きな標本サイズにおいて「漸近的に良い性質を持つ」ことがわかりました。これは逆に言えば、標本サイズが小さいケースに対して最尤推定を適用する際には、バイアスや分散の影響等を考慮しておく必要があることを意味しています。
これらの影響に対しては、パラメータに制約を課すことで過度な推定バイアスを防ぐ「正則化」、事前情報を用いてパラメータの不確実性を軽減する「ベイズ推定法」、小標本での分散や信頼区間評価のための「ブートストラップ法」、等の対策を活用することが考えられます。
ベイズ推定法 最尤推定法をはじめこれまでに述べた点推定法は「頻度主義 」という前提にたっています。頻度主義の立場では母集団の特徴を定めるパラメータはある定められた値をもち、観測データは確率的に変動すると考えます。推定値は観測データの統計量から導出される(最小二乗法推定)、あるいは観測データがあらわれる確率を最大化するパラメータとして算出されます(最尤推定法)。ベイズ推定法(Bayesian Estimation) は逆に母集団のパラメータは確率的にしか値を知ることができない不可知性(Uncertainty)、不確実性をもったものと考えます。そして今パラメータに対してもっている不確実性をパラメータの「事前分布(Prior distribution) 」として表現し、これを新しい観測データによってアップデートすることでパラメータの不確実性を減じていくというアプローチをとります。このアップデートされた分布をパラメータの「事後分布(Posteriori distribution) 」と呼びます。ポイントは事前分布をどのように定めるのかとアップデートの方法です。なお分布と名のつく用語がいくつも出てきましたが、事前分布とは母集団の分布関数とは異なる概念でありパラメータ自体の分布を決定する確率分布であることを再度強調しておきます。
事前分布の決定手法:
事前分布を適切に決定することは、ベイズ推定の結果に大きな影響を与えるため、慎重に選択する必要があります。以下に事前分布を決定する一般的な方法を示します
事前知識の利用: 事前分布はパラメータについての既存の知識や信念に基づいて設定されることがあります。ドメインの専門知識や関連する研究から得られた情報を利用して、事前分布を決定します。
非情報事前分布(Non-Informative Prior):特定の情報を反映しない分布を利用します。例えば、一様分布はわかりやすい例。
経験的ベイズ法(Empirical Bayes): 過去のデータからパラメータの事前分布を決める方法です。対象となる統計モデルに対する尤度関数を選択する、そして最尤推定法を使用して観測データから事前分布のパラメータを推定します。事前分布は通常は特定の確率分布(例: ベータ分布、指数分布)を仮定し、その分布のパラメータを観測データから推定します。
感度分析: ベイズ推定では事前分布に対する感度分析を行うことが一般的です。事前分布のパラメータを変化させて結果の感受性を評価し、選択した事前分布が結果にどれだけ影響を与えるかを調査します。
事前分布のアップデート:
ベイズの更新式は、ベイズの定理に基づいて尤度関数と事前分布から事後分布を計算する式であり、次のように表されます:
事後分布 = 尤度関数 × 事前分布 / 正規化定数
これを式で書くと以下のように表現できます:
P ( θ ∣ x ) = P ( x ∣ θ ) ⋅ P ( θ ) P ( x )
\begin{equation}
P(θ∣x)= \frac{P(x∣θ)⋅P(θ)}{P(x)}
\end{equation}
P ( θ ∣ x ) = P ( x ) P ( x ∣ θ ) ⋅ P ( θ )
ここで、各項の意味は以下の通り:P ( θ ∣ x ) P(θ∣x) P ( θ ∣ x ) P ( x ∣ θ ) P(x∣θ) P ( x ∣ θ ) P ( θ ) P(θ) P ( θ ) P ( x ) P(x) P ( x ) 周辺尤度(marginal likelihood) 」とも呼ばれています。
MAP推定法により事後分布の統計量をえる
MAP(Maximum A Posteriori)推定法 は、計算量の問題で事後分布自体を求めることが難しい場合、かわりに事後分布内で最も確率密度が高い(最も尤もらしい)パラメータの値を求める手法です。これは事後分布の「ピーク」に対応します。MAP 推定値は事後分布から得られる一つの統計値であり、パラメータの不確実性を考慮する点推定の手法といえます。
MAP 推定値を以下の式で表します:
θ M A P = argmax θ P ( θ ∣ x )
\begin{equation}
\theta_{MAP}=\underset{\theta}{\operatorname{argmax}} \; P(\theta∣x)
\end{equation}
θ M A P = θ argmax P ( θ ∣ x )
ここで、各記号の意味は次の通り:θ M A P \theta_{MAP} θ M A P θ \theta θ P ( θ ∣ x ) P(θ∣x) P ( θ ∣ x ) θ \theta θ
右辺をベイズの更新式で置き換えたとき正規化定数の部分はθ \theta θ
argmax θ P ( θ ∣ x ) = argmax θ P ( x ∣ θ ) ⋅ P ( θ ) P ( x ) = argmax θ P ( x ∣ θ ) ⋅ P ( θ )
\begin{align}
\underset{\theta}{\operatorname{argmax}} \; P(θ∣x) &= \underset{\theta}{\operatorname{argmax}} \; \frac{P(x∣θ)⋅P(θ)}{P(x)} \\
&= \underset{\theta}{\operatorname{argmax}} \; P(x∣θ)⋅P(θ)
\end{align}
θ argmax P ( θ ∣ x ) = θ argmax P ( x ) P ( x ∣ θ ) ⋅ P ( θ ) = θ argmax P ( x ∣ θ ) ⋅ P ( θ )
例えば事前分布がθ \theta θ
うまい決め方のひとつとして「共役事前分布(Conjugate Prior) 」をあげておきます。
これは尤度関数と事後分布が同じ関数の形になるように事前分布を決める方法です。
例えば母集団の観測データ X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X = { x 1 , x 2 , … , x n } θ \theta θ N ( θ , σ 2 ) N(\theta,\sigma^2) N ( θ , σ 2 ) θ \theta θ θ \theta θ μ 0 \mu _ 0 μ 0 σ 0 2 \sigma_0^2 σ 0 2
P ( θ ∣ X ) ∝ exp ( − 1 2 σ 2 ∑ i = 1 n ( x i − θ ) 2 ) × exp ( − 1 2 σ 0 2 ( θ − μ 0 ) 2 )
\begin{equation}
P \left( \theta | X \right) \propto \exp \left( -\frac{1}{2 \sigma ^ 2} \sum _ {i=1} ^ n (x _ i - \theta) ^ 2 \right) \times \exp\left( -\frac{1}{2\sigma _ 0 ^ 2} (\theta - \mu _ 0) ^ 2 \right)
\end{equation}
P ( θ ∣ X ) ∝ exp ( − 2 σ 2 1 i = 1 ∑ n ( x i − θ ) 2 ) × exp ( − 2 σ 0 2 1 ( θ − μ 0 ) 2 )
両辺の対数をとることで、
log P ( θ ∣ X ) = − 1 2 σ 2 ∑ i = 1 n ( x i − θ ) 2 − 1 2 σ 0 2 ( θ − μ 0 ) 2 + C
\begin{equation}
\log P \left( \theta | X \right) = - \frac {1} { 2 \sigma ^ 2 } \sum _ {i=1} ^ n ( x _ i - \theta ) ^ 2 - \frac {1}{ 2 \sigma _ 0 ^ 2 } ( \theta - \mu _ 0 ) ^ 2 + C
\end{equation}
log P ( θ ∣ X ) = − 2 σ 2 1 i = 1 ∑ n ( x i − θ ) 2 − 2 σ 0 2 1 ( θ − μ 0 ) 2 + C
ここで C C C θ \theta θ log P ( θ ∣ X ) \log P(\theta | X) log P ( θ ∣ X ) θ \theta θ − 1 -1 − 1
− log P ( θ ∣ X ) = 1 2 σ 2 ∑ i = 1 n ( x i − θ ) 2 + 1 2 σ 0 2 ( θ − μ 0 ) 2 + C ′
\begin{equation}
-\log P(\theta | X) = \frac{1}{2\sigma^2} \sum_{i=1}^n (x_i - \theta)^2 + \frac{1}{2\sigma_0^2} (\theta - \mu_0)^2 + C'
\end{equation}
− log P ( θ ∣ X ) = 2 σ 2 1 i = 1 ∑ n ( x i − θ ) 2 + 2 σ 0 2 1 ( θ − μ 0 ) 2 + C ′
ここで C ′ C' C ′ θ \theta θ θ \theta θ
d d θ ( − log p ( θ ∣ X ) ) = 1 σ 2 ∑ i = 1 n ( x i − θ ) + 1 σ 0 2 ( θ − μ 0 )
\begin{equation}
\frac{d}{d\theta} \left( -\log p(\theta | X) \right) = \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \theta) + \frac{1}{\sigma_0^2} (\theta - \mu_0)
\end{equation}
d θ d ( − log p ( θ ∣ X ) ) = σ 2 1 i = 1 ∑ n ( x i − θ ) + σ 0 2 1 ( θ − μ 0 )
式を変形していけば以下のようになります。
1 σ 2 ∑ i = 1 n ( x i − θ ) + 1 σ 0 2 ( θ − μ 0 ) = 0
\begin{equation}
\frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \theta) + \frac{1}{\sigma_0^2} (\theta - \mu_0) = 0
\end{equation}
σ 2 1 i = 1 ∑ n ( x i − θ ) + σ 0 2 1 ( θ − μ 0 ) = 0
1 σ 2 ∑ i = 1 n x i − n σ 2 θ + 1 σ 0 2 θ − μ 0 σ 0 2 = 0
\begin{equation}
\frac{1}{\sigma^2} \sum_{i=1}^n x_i - \frac{n}{\sigma^2} \theta + \frac{1}{\sigma_0^2} \theta - \frac{\mu_0}{\sigma_0^2} = 0
\end{equation}
σ 2 1 i = 1 ∑ n x i − σ 2 n θ + σ 0 2 1 θ − σ 0 2 μ 0 = 0
( n σ 2 + 1 σ 0 2 ) θ = 1 σ 2 ∑ i = 1 n x i + μ 0 σ 0 2 従って、 θ M A P = 1 σ 2 ∑ i = 1 n x i + μ 0 σ 0 2 n σ 2 + 1 σ 0 2
\begin{equation}
\left( \frac{n}{\sigma^2} + \frac{1}{\sigma_0^2} \right) \theta = \frac{1}{\sigma^2} \sum_{i=1}^n x_i + \frac{\mu_0}{\sigma_0^2}
\end{equation}
従って、
\begin{equation}
\theta _ {MAP}= \frac{\frac{1}{\sigma^2} \sum_{i=1}^n x_i + \frac{\mu_0}{\sigma_0^2}}{\frac{n}{\sigma^2} + \frac{1}{\sigma_0^2}}
\end{equation}
( σ 2 n + σ 0 2 1 ) θ = σ 2 1 i = 1 ∑ n x i + σ 0 2 μ 0 従って、 θ M A P = σ 2 n + σ 0 2 1 σ 2 1 ∑ i = 1 n x i + σ 0 2 μ 0
正規分布のように解析的な計算により MAP 推定値を得ることができる母数の分布としては他に二項分布(事前分布はベータ分布)、ポアソン分布(事前分布はガンマ分布)等の指数型分布族に属する分布が知られています。
このほかにマルコフ連鎖モンテカルロ法(MCMC)と呼ばれる機械学習や予測で使われる非常に興味深い技法がありますがここでは踏み込みません。ここでは医療統計の記載が充実した書籍を参考としてあげておきます(参考2 )。
2.4. 区間推定 不確実性の認識と信頼度:統計的推定行為には不確かさがある という前提にたちます。その不確かさを測る指標として「信頼度(信頼水準) 」を事前に設定します。一般的には95%や99%などが使われるようです。推定対象パラメータをP a r a m Param P a r am ∣ P a r a m ∣ < v \hspace{0.3em} |Param|<v \hspace{0.3em} ∣ P a r am ∣ < v 2 v 2v 2 v 信頼区間 」と呼びます。信頼区間を決定することを一般に区間推定 といいます。
信頼区間の計算:
以下に主要な区間推定の方法をあげておきます。
Zスコアによる推定: X X X
Z = X − μ σ
\begin{equation}
Z = \frac{X-\mu}{\sigma}
\end{equation}
Z = σ X − μ
ここで X は観測データ、μ は母集団の平均、σ は母集団の標準偏差です。X ‾ \overline{X} X
Z = X ‾ − μ σ / n
\begin{equation}
Z = \frac{\overline{X}-\mu}{\sigma/\sqrt{n}}
\end{equation}
Z = σ / n X − μ
この式の分母に現れる量を標準誤差(Standard Error, SE) とよびます。
S E = σ n
\begin{equation}
SE = \frac{\sigma}{\sqrt{n}}
\end{equation}
SE = n σ
観測データ X X X z c o n f z_{conf} z co n f
P ( − z c o n f ≤ X ‾ − μ S E ≤ + z c o n f ) = α
\begin{equation}
P(-z_{conf} \ \le\ \frac{\overline{X}-\mu}{SE} \ \le\ +z_{conf}) \ =\ \alpha
\end{equation}
P ( − z co n f ≤ SE X − μ ≤ + z co n f ) = α
Pの括弧内の論理式は以下と同値
P ( X ‾ − z c o n f ⋅ S E ≤ μ ≤ X ‾ + z c o n f ⋅ S E ) = α
\begin{equation}
P(\overline{X}-z_{conf}\cdot SE \ \le\ \mu \ \le\ \overline{X}+z_{conf}\cdot SE) \ =\ \alpha
\end{equation}
P ( X − z co n f ⋅ SE ≤ μ ≤ X + z co n f ⋅ SE ) = α
つまり信頼区間の推定値は標本平均からずれの下限、上限として以下のように求められます。
下限 = X ‾ − z c o n f ⋅ S E \overline{X}-z_{conf}\cdot SE X − z co n f ⋅ SE X ‾ + z c o n f ⋅ S E \overline{X}+z_{conf}\cdot SE X + z co n f ⋅ SE
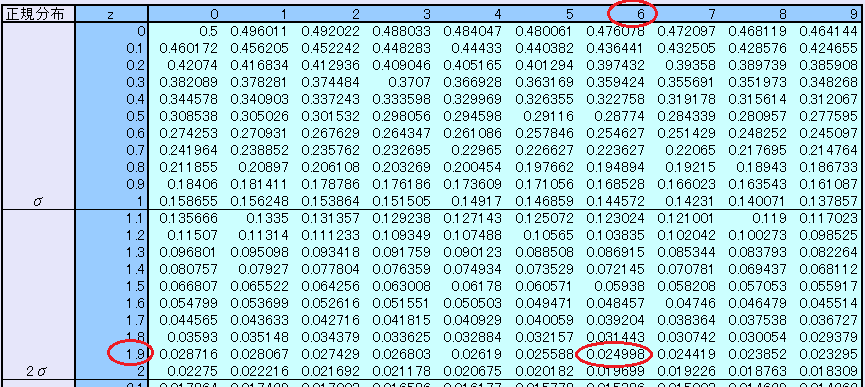
具体的な数値は公開されているZ分布表(例:産総研のZ分布表 )を利用することで容易に信頼区間の推定値を得ることができます。
上図で左側の赤丸はZスコアの小数点1位までの数字が「1.9」であることを示します。上方の赤丸は小数点2位の数字が「6」であることを示します。1.9 の横軸と6の縦軸の交点の数字「0.024998」が信頼度を示します。すなわちZ<=1.96となる確率が約 0.25% であることを示しています。信頼度の設定を正あるいは負どちらかに限定することを片側推定といい、正負両方設定した場合を両側推定と呼ぶ習慣があるので信頼度5%での両側推定の信頼区間は |Z|<=1.96 ということになります。
言葉の使い方
Tスコアによる推定:
Z スコアによる推定は母分散が既知であることを前提としています。またnが小さくなるほど推定の誤差は増えていきます。Tスコアによる推定はこのようなZスコアが適用できないケースにも対応できるため実務ではよく使われています。
T スコアの背後にある考え方は、母集団の平均に関する統計的な推定を行う際に、標本サイズの大きさが小さい場合に生じる不確かさ(標本誤差)を補正することです。
不明な母分散 σ 2 \sigma^2 σ 2 標本不偏分散 」 s 2 s^2 s 2 標本標準偏差 」と呼ばれることがあります。少し紛らわしい言葉の使い方のように感ずるのですが。
s : = 1 n − 1 ∑ i n ( x i − X ‾ ) 2
\begin{equation}
s := \sqrt{\frac{1}{n-1}\sum_i^n(x_i-\overline{X})^2}
\end{equation}
s := n − 1 1 i ∑ n ( x i − X ) 2
日次の株価 P t P_t P t ボリンジャーバンド としてよく知られています。また、株価収益率 R t + 1 : = ( P t + 1 − P t ) / P t R_{t+1} := (P_{t+1} - P_t)/P_t R t + 1 := ( P t + 1 − P t ) / P t ヒストリカルボラタリティ と呼ばれ、株価の値動きの大きさを示す指標としてよく使われています。
H v : = 1 n − 1 ∑ i = t − n t ( R i − R ‾ ) 2 ∗ m a r k e t _ d a y s ∗ 100
\begin{equation}
H_v := \sqrt{\frac{1}{n-1}\sum_{i=t-n}^t(R_i-\overline{R})^2}*\sqrt{market\_days}*100
\end{equation}
H v := n − 1 1 i = t − n ∑ t ( R i − R ) 2 ∗ ma r k e t _ d a ys ∗ 100
上記で、market_days は市場の年間営業日数を表し、例えば250日等の数字を指定します。
標準誤差の式が σ / n \sigma/\sqrt{n} σ / n ∑ i n ( x i − X ‾ ) 2 / n \sum_i^n(x_i-\overline{X})^2/n ∑ i n ( x i − X ) 2 / n ( n − 1 ) σ 2 / n (n-1)\sigma^2/n ( n − 1 ) σ 2 / n σ 2 \sigma^2 σ 2 E ( s 2 ) E(s^2) E ( s 2 ) σ 2 \sigma^2 σ 2
標本標準偏差(s / n s/\sqrt{n} s / n Tスコア です。
T = X ‾ − μ s / n
\begin{equation}
T = \frac{\overline{X}-\mu}{s/\sqrt{n}}
\end{equation}
T = s / n X − μ
ここでX ‾ \overline{X} X
Tスコアが従うT分布の信頼区間の推定値は標本平均からずれの下限、上限として以下のように求められます。信頼度をα、これを実現する区間幅をt c o n f t_{conf} t co n f
下限 = X ‾ − t c o n f ⋅ s / n \overline{X}-t_{conf}\cdot s/\sqrt{n} X − t co n f ⋅ s / n X ‾ + t c o n f ⋅ s / n \overline{X}+t_{conf}\cdot s/\sqrt{n} X + t co n f ⋅ s / n
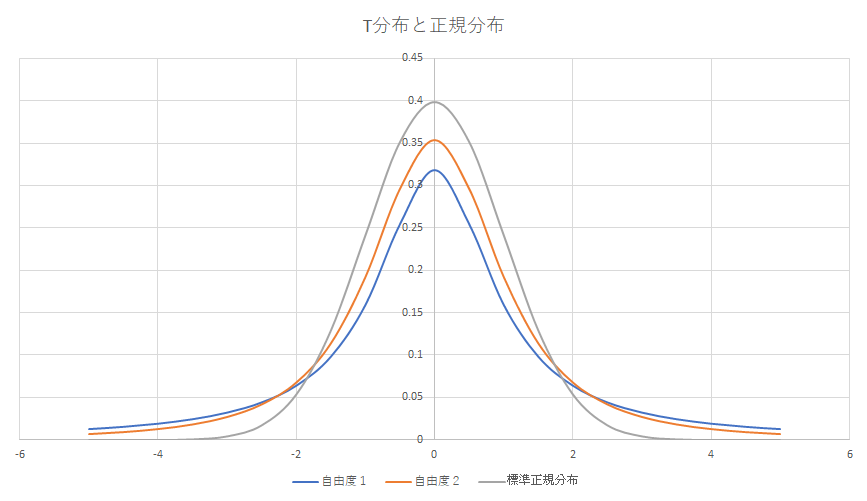
上図は比較のため T 分布の自由度1、2のグラフと標準正規分布のグラフを excel を使って書いてみました。T 分布は T.DIST 関数、正規分布は NORM.DIST 関数で計算したものを散布図で容易にグラフ化にできます。自由度は標本サイズ(=標本あたりの観測データ数)から1を引いた数として定義されるため、自由度1のグラフは標本サイズ = 2 のときに適用されます。
参考
- Z分布表 産総研有機基準物研究グループ
- T分布表 産総研有機基準物研究グループ
3. 統計的に有意であるとは 統計の世界ではある命題の真偽を判定するために計画された実験や調査があったとして、その命題を肯定する結果が偶然に出現したとは考えにくい場合、命題が真であると考え「統計的に有意な 」結果が得られたと言明します。ここに出てきた「偶然に出現したとは考えにくい」を判定する基準を数値化し「有意水準(significance_level) 」あるいは「危険率 」と呼称します。これを指すのにしばしば記号αを用いられます。有意水準は実験や調査の内容に応じて決められるべき数値ですが以下のようなとらえ方がよく行われているようです。
「 100% 正しい」、も「 100% 間違っている」も無い世界で真偽を定義するアイデアとして、便宜的な感じがしつつも便利には違いないと思います。
3.1 帰無仮説 目的とする母集団の特徴を知るということを統計の手法では真偽を判定できる命題の形で表現します。仮説した統計モデルの正しさを検証する等、真偽を証明したい命題を対立仮設と呼びます。これに対して、その命題が偽であると仮定することを「帰無仮説(Null Hypothesis) 」を設定するといいます。そして試行から得られたデータをもとに帰無仮説を肯定する結果が出現する確率を計算します。それがあらかじめ定めた有意水準(例えば 5% )以下であれば、帰無仮説を棄却(否定)する,つまり帰無仮説の反対を主張するもともとの命題(「対立仮説 」と呼ばれる)が真であると判定します。
少し言い換えると帰無仮説は対象とする命題が偶然に成立することはさほど珍しいことではないと主張します。しかしその前提で計算してみると極めて稀にしか成立しない事象であることが判明したとします。するともっともらしい結論とは、帰無仮説は誤りであり対象とする命題が成り立つことは偶然ではなく必然だろうとする判断です。
まわりくどい感じもするのですが、「仮説」が正しくないことを証明するためには反例がひとつでも見つかればOKなので、背理法に従ったこの考え方は合理的であるといえます。ただし帰無仮説が棄却されなかった場合何がわかったのかというと、「対立仮説が正しいとはいえない」であって「対立仮説は誤っている」ではない、ということに注意が必要です。
このようにして得られた試行結果をもとに帰無仮説が真であることを証明する作業を「検定(Test) 」と呼称します.具体的な手順として帰無仮説を証明するための定量的指標をまず定めます.これを「検定統計量(test statistic) 」とよびます.帰無仮説が成立すると仮定したうえで標本に対する検定統計量を算出し、その出現確率が有意水準を下回るのであれば、帰無仮説を棄却する。そうでなければ対立仮説を受容します。
3.2. 超能力は存在するか? 参考3の「推計学のすすめ」という本に記載されていた題材がおもしろっかたのでこれを補強して帰無仮説を説明してみましょう。
唐突だけれどサイコロ投げという行為を通じて「超能力は存在する」という命題をたてその真偽を判定したいと私は考えました。これを証明するための実験としてサイコロを1000回振って念じて偶数を出現させる試行を行おうと思います。
母集団は無限に続くサイコロ投げ、標本は一定回数投げて出た目の集合とする。帰無仮説(H0)は「超能力は存在しない」、対立仮説(H1)は「超能力は存在する」。有意水準を 5% と設定します。
検定統計量は、念じて偶数を出現させた回数(例えば、偶数の出現回数)を用います。帰無仮説の下では超能力が存在しないと仮定されているため、偶数が出現する確率は通常のサイコロの確率(1/2)と同じであると仮定します。
検定のステップ:
試行の結果:
帰無仮説の判定:
P ( X ≥ k ) = 1 − ∑ i = 0 k − 1 ( n i ) ⋅ p i ⋅ ( 1 − p ) n − i
\begin{equation}
P(X \ge k) = 1- \sum_{i=0}^{k-1} \left(
\begin{array}{c}
n \\
i
\end{array}
\right)
\cdot p^i \cdot (1-p)^{n-i}
\end{equation}
P ( X ≥ k ) = 1 − i = 0 ∑ k − 1 ( n i ) ⋅ p i ⋅ ( 1 − p ) n − i
P ( X ≥ k ) P(X \ge k) P ( X ≥ k ) ( n k ) \left(\begin{array}{c}n \\ k \\ \end{array} \right) ( n k ) n C k = n ! k ! ( n − k ) ! _nC_k= \frac{n!}{k!(n-k)!} n C k = k ! ( n − k )! n !
ExcelのBINOM.DIST関数あるいはscipyのbinom.cdf関数など、二項分布の確率分布関数をサポートするツールで計算すると約0.358%を得ます。これは有意水準5%をかなり下回るので偶数の目が出た回数542回は偶然に出現するとは考えられず、結論として帰無仮説は棄却され、「超能力は存在する」と推定できます。
有意水準との比較に使われたP ( X ≥ k ) P(X \ge k) P ( X ≥ k ) p値 と呼びます。
蛇足ですが有意水準に対応する偶数出現数を計算すると526という数字が出ます。この程度のばらつきは何回か試行するとなんとなく容易に出現しそうな気もするのですが実際にはありえないほどレアということです。
3.3. 手法の一般化 手法の一般化: Z検定 上述した Excel の BINOM.DIST 関数が二項分布をどういうアルゴリズムで出力しているのか筆者は知りませんが、一般に検定統計量が現実的な時間では計算できない場合もあるでしょう。そのような場合であっても中心極限定理が成り立つ条件さえ満たせていれば検定統計量が従う分布として正規分布を使うことができます。二項分布の場合では、分布の期待値 E 、分散 V はそれぞれ np、np(1-p) であること、さらに二項分布は標本サイズ n が大きい場合期待値 np、分散 np(1-p) の正規分布の確率密度関数へ近似することが古くからド・モアブル=ラプラスの極限定理として知られています。
X ∼ 1 2 π n p ( 1 − p ) exp ( − ( k − n p ) 2 2 n p ( 1 − p ) )
\begin{equation}
X \quad \sim \quad \frac{1}{\sqrt{2\pi np(1-p)}}\exp(-\frac{(k-np)^2}{2np(1-p)})
\end{equation}
X ∼ 2 πn p ( 1 − p ) 1 exp ( − 2 n p ( 1 − p ) ( k − n p ) 2 )
したがって二項分布に従う統計量をXとしたとき標本サイズが大きければ
Z = X − n p n p ( 1 − p )
\begin{equation}
Z \quad = \quad \frac{X-np}{\sqrt{np(1-p)}}
\end{equation}
Z = n p ( 1 − p ) X − n p
は近似的に標準正規分布に従います。この式と標準正規分布表をつかって前述のP(X>=k)を算出してみると0.40%というけっこう近い値が出てきます。離散分布の二項分布を連続分布の正規分布で近似する際に現る差異を補正するために定数0.5を上記Zの定義式分子に加えることを連続補正 といいます。連続補正によりZの定義式分子をX+0.5-npで置き換えると近似はもっと良くなり約0.362%という値がでてきます。
平均と分散があらかじめわかっている正規分布に従うZスコアを統計量として使用する検定手法はZ検定(Z-test) と呼ばれます.この事例では母集団(=サイコロを振って出た目の列)の平均と分散が既知であったためうまい具合にZ検定を適用することができました.
X ‾ \overline{X} X μ \mu μ σ \sigma σ
Z = X ‾ − μ σ / n
\begin{equation}
Z \quad = \quad \frac{\overline{X}-\mu}{\sigma / \sqrt{n}}
\end{equation}
Z = σ / n X − μ
Z 検定の適用シーン
標本平均の母集団平均との比較(1標本の検定):μ \mu μ μ 0 \mu_0 μ 0 μ − μ 0 = 0 \mu - \mu_0=0 μ − μ 0 = 0
母集団の平均の比較(2標本の検定):μ 0 , μ 1 \mu_0,\mu_1 μ 0 , μ 1 μ 0 − μ 1 = 0 \mu_0-\mu_1=0 μ 0 − μ 1 = 0
母集団の比率の比較:
標本サイズが大きいケースへの適用:
手法の一般化: T 検定 残念ながら現実の応用場面では母集団の平均、分散が既知であることはまれです.そのため母集団の分布は正規分布であるが平均、分散は不明であるという前提での検定手法が一般によく用いられる「T検定 」です.T 検定では前出の T スコアを検定統計量として使用する手法です.
T = X ‾ − μ S / n
\begin{equation}
T \quad = \quad \frac{\overline{X}-\mu}{S / \sqrt{n}}
\end{equation}
T = S / n X − μ
ここでS 2 S^2 S 2 S / n S / \sqrt{n} S / n
T検定の適用シーンはZ検定と同様です。
1標本検定の場合は母集団の平均μ 0 \mu_0 μ 0 μ − μ 0 = 0 \mu - \mu_0=0 μ − μ 0 = 0
2標本検定の場合は、ふたつの母集団の平均の差を検定します。母集団の平均の値自体は問わず、分散は不明という前提となります。Z検定のときと同じく標本平均の差μ 0 − μ 1 = 0 \mu_0 - \mu_1=0 μ 0 − μ 1 = 0
3.4. 棄却域とP値: 棄却域(Rejection Region) :臨界値(critical value) 」とよびます。
P 値(P-value) :
4. 推定の性能を測る指標 仮説検定では命題の真偽が便宜的であるだけに、帰無仮説 H 0 H_0 H 0 H 0 H_0 H 0 H 1 H_1 H 1
表中4つの主要な要素が含まれます:
帰無仮説を棄却する:
帰無仮説を棄却しない:
試行により得られた観測データの構成比率は推定作業の性能(成績)を評価する指標となります。以下は主要な指標です。
正解率(Accuracy) :真の陽性、真の陰性が正しく判定された観測データの割合
A c c u r a c y = T P + T N T P + T N + F P + F N
\begin{equation}
Accuracy = \frac{TP + TN} {TP + TN + FP + FN}
\end{equation}
A cc u r a cy = TP + TN + FP + FN TP + TN
適合率(精度)(Precision) :陽性と判定された観測データのうち、真は陽性である割合
P r e c i s i o n = T P T P + F P
\begin{equation}
Precision = \frac{TP} {TP + FP}
\end{equation}
P rec i s i o n = TP + FP TP
再現率(感度)(Recall) :真は陽性の観測データのなかで、正しく陽性と判定された割合
R e c a l l = T P T P + F N
\begin{equation}
Recall = \frac{TP} {TP + FN}
\end{equation}
R ec a ll = TP + FN TP
F1スコア(F1 Score) :適合率と再現率の調和平均で、対立仮説のバランスを示す指標。
F 1 − s c o r e = 2 ∗ ( 適合率 ∗ 再現率 ) / ( 適合率 + 再現率 )
\begin{equation}
F1-score = 2 * (\text{適合率} * \text{再現率}) / (\text{適合率} + \text{再現率})
\end{equation}
F 1 − score = 2 ∗ ( 適合率 ∗ 再現率 ) / ( 適合率 + 再現率 )
第一種過誤と第二種過誤は表中トレードオフの位置になっているため同時に減らすことはできません。統計の標準的な考え方では検定の誤りを減らすためにはまず適合率(精度)を向上させます。第一種の過誤となる確率 α \alpha α 1 − β 1-\beta 1 − β
次に株価予測モデルの有効性を検定する作業を考えてみましょう。有効な株価モデルとは「上昇すると予測した株価が実際に上昇する」、上昇的中率が高いモデルであると考えることにします。
「(H 0 H_0 H 0 H 1 H_1 H 1
上昇予測数に対する上昇的中数の割合の分布を測定し検証した結果帰無仮説が棄却されたなら予測モデルは有効だ!と判定する、という流れです。下表でいえば観測データのなかで ( T P + F P ) (TP+FP) ( TP + FP ) F P / ( F P + T N ) FP/(FP+TN) FP / ( FP + TN )
補足説明 補足説明 確率・統計 補足説明 ソフトウェアを準備する