第1章 株式投資と数理の関わり#
1. 数理的手法の入り口#
株取引の世界では、数理的手法が日常的に活用されています。専門家が高度な数学と専用のツールを駆使する一方、個人投資家が手軽に使う身近な手法も根底には数理があります。例えば、株価の移動平均チャートは、過去何日間かの株価の平均値を算出し、それをチャートとして表現したものです。単純な方法ですが株価の全体的なトレンドを容易に把握できるためはるか昔から利用されています。 そしてこの「平均をとる」という考え方を数学の言葉で捉え、体系化・抽象化することで、実に様々な応用を生み出すことができるのです。
以下にごく一端ですが実際に株価データを使って「平均化する」ことでわかることを説明したいと思います。
1.1. 株価データを入手する#
まず株価関連のデータを金融マーケット情報を提供するWebサイトからダウンロードする方法、そして公開APIを使ったプログラムでダウンロードする方法をそれぞれ簡単に紹介します。 Yahoo financeのサイトhttps://finance.yahoo.com/にアクセスします。ページ上部の検索バーに証券コード(例えば「極洋」なら1301)を入力すると以下のように候補がプルダウンリストに表示されるので選択します。
Yahoo financeでは日本株を指定するために証券コードに'.T'を付与しています。極洋なら'1301.T'です。そのほかマーケット指標、為替には下表のように固有のシンボルが定義されています。以下サイトから検索することもできます。 yahoo finance us/ ticker lookup
| マーケット指標、為替 | シンボル名 |
|---|---|
| 日経225 | ^N225 |
| S&P 500 | ^GSPC |
| USD/JPY(米ドル円レート) | JPY=X |
| USD/EUR(米ドルユーロレート) | EURUSD=X |
遷移した先の個別株価情報のページで、'Historical Data'のメニュータブを選びます。そして表示したい期間などを設定し'Download'をクリックすればデータがcsvファイルとしてダウンロードされます。
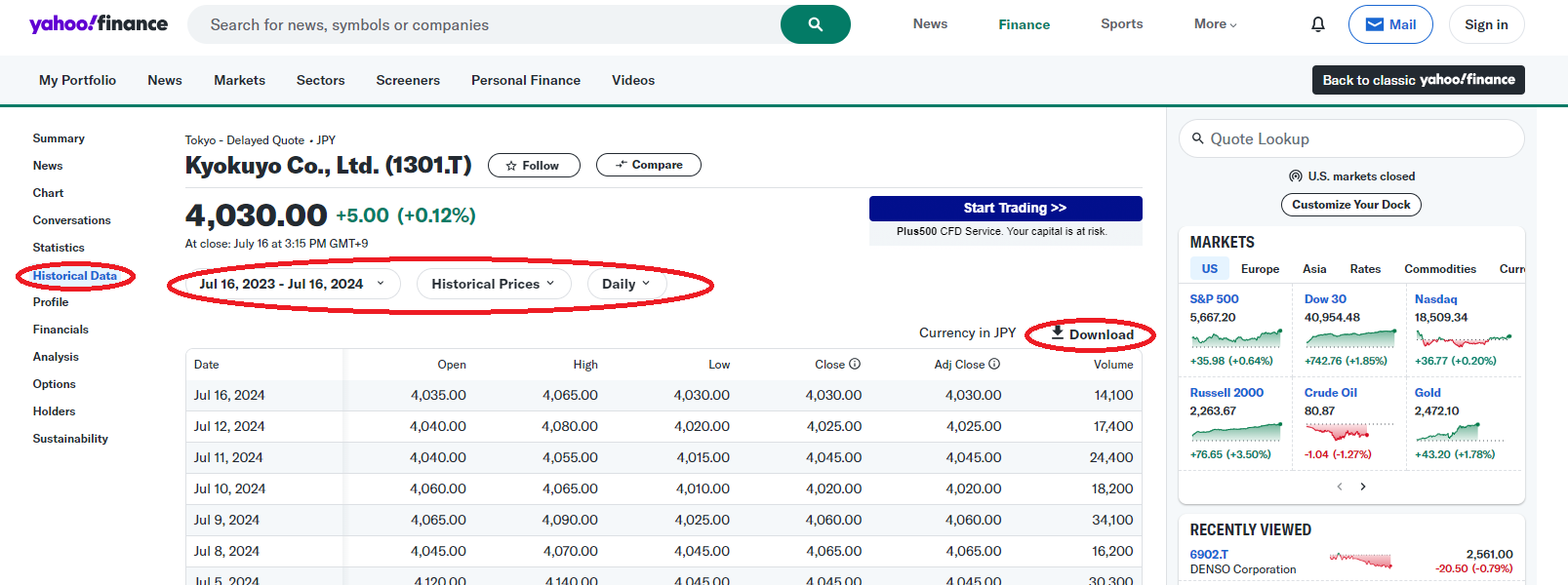
(注)2024年9月末時点で、上記のDownload機能が何らかの理由で削除されています。
サイト上に特段の説明が見当たらないため、今後復活するのかどうか不明です。
そのため別手段でダウンロードする方法を本章の補足1に記載しましたので参照ください。
1.2. 株価データを読み込む#
pandas_datareaderを使う
pandas_datareaderはPythonプログラムに直接データを取り込むためのAPIを提供するポピュラーなツールです。python環境と、2次元データを操作するための定番ツールであるpandasが必要となります。事前にpython環境を準備したうえで、以下のコマンドをコマンドプロンプトやターミナルで実行してツールをインストールします。
pip install pandas pandas_datareader
以下のpythonコードはマーケット情報プロバイダのstooqから株価データをダウンロードし、CSVファイルへの保存を行います。
import pandas_datareader.data as web
# ダウンロードするデータの情報を設定
start_date = '2023-01-01' # データの開始日を指定
end_date = '2023-05-30' # データの終了日を指定
stock_symbol = '1301.JP' # 株価データをダウンロードする企業のシンボルを指定
# データプロバイダとしてを'stook'を指定して株価データをダウンロード
stock_data = web.DataReader(stock_symbol, data_source='stooq', start=start_date, end=end_date)
# CSVファイルとして保存する。シリアル番号のインデクスを付与しない。
stock_data.to_csv('stock_data.csv',index=False)
stooqのほかにも多数のデータプロバイダが定義されており多様なデータを取得できることがdata_readerの特徴です。ツールのサイトhttps://pandas-datareader.readthedocs.io/en/latest/を参照すると定義済のプロバイダを確認できる。ただし設定するとエラーが返るプロバイダ名もあるようです(例:'yahoo')。
yahoo_fin を使う
このツールは簡単に株価をダウンロードできるapi を提供しています。ファンダメンタル情報などいろいろな機能があるのですが、コードがアップデートされておらず株価データのダウンロード以外は、動作していない可能性があるので注意が必要です。コマンドプロンプトやターミナルで次のコマンドを実行してツールをインストールします。
pip install yahoo_fin
以下のpythonコードは日経平均株価データのダウンロードとCSVファイルへの保存を行います。
- ダウンロードされるデータは以下のように pandas dataframe として返されます。
open high low close adjclose volume ticker
2002-05-23 1.156429 1.242857 1.145714 1.196429 1.196429 104790000 NFLX
2002-05-24 1.214286 1.225000 1.197143 1.210000 1.210000 11104800 NFLX
- start_date,end_date は日付を文字列で指定します。
- index_as_date を True にすると日付列をindexとするデータフレームが返ります。
- interval は、'1d','1wk','1mo' が可能でそれぞれ、日次、週次、月次のデータに対応します。
# pre_yfin.py
#
from yahoo_fin import stock_info as si
# 個別企業の場合には証券コードに.Tを付加する
code = "6227.T"
name = "AIメカテック"
start_date = "2023-12-07"
end_date = "2024-12-06"
df = si.get_data(code, index_as_date = False,start_date=start_date, end_date=end_date,interval='1d')
# csv出力。小数点以下は2桁までとする。
df.to_csv(f"{code}.temp.csv", float_format='%.2f', index = False)
2026年3月追記
yahoo_fin はメンテナンスがほとんどされておらず動作にも問題が出ているため、
本稿では代替として yfinance によるコードへの移行を行っています。詳しくは
本ページ末尾の補足2を参照ください。
1.3. 移動平均チャート#
作成した株価csvファイルはpythonのチャート作図用ライブラリmatplotlibを使うと簡単に表示することができます。 残念なことにmatplotlibは既定値では日本語表示に対応していません。日本語を表示する設定はネット情報でもいくつか探すことができるのですが、かなり環境依存性が強いので注意が必要です。ここで使用したjapanize_matplotlib は、設定ファイルを修正したりプログラムでの設定も特に必要なく日本語表示ができるので重宝しています。冗長になりますがチャートに少し修飾を追加したサンプルコードが以下です。 このコードでは株価の終値と2種類の期間の移動平均をチャートとして表示します。
pip install matplotlib japanize_matplotlib
#
# pre_plot_code.py
#
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import japanize_matplotlib
import datetime
# CSVを読み込みデータフレームを返す
code = code = '6227'
name = 'AIメカテック'
df = pd.read_csv(f'{code}.T.csv')
# 'Date'列をdatetime64型に変換する
df['Date'] = pd.to_datetime(df['Date'])
# 移動平均を計算する
df['25-Day MA'] = df['Close'].rolling(window=25).mean()
df['300-Day MA'] = df['Close'].rolling(window=300).mean()
# 表示区間のdfを切り出す
df = df[(df['Date'] >= datetime.datetime(2023,4,18)) & (df['Date'] <= datetime.datetime(2024,4,17))]
# 最安株価と最高株価の水平線をプロット
min_price = df['Close'].min()
max_price = df['Close'].max()
plt.axhline(y=min_price, color='gray', linestyle='--', label=f'最安値: {min_price}')
plt.axhline(y=max_price, color='gray', linestyle='--', label=f'最高値: {max_price}')
# 'Close'列を折れ線チャートで描画する
line1, = plt.plot(df['Date'], df['Close'], label='日足終値', color='red')
line2, = plt.plot(df['Date'], df['25-Day MA'], label='25日移動平均', color='blue')
line3, = plt.plot(df['Date'], df['300-Day MA'], label='300日移動平均', color='green')
# 最安株価と最高株価の日付にアノテーションを追加
min_date = df.loc[df['Close'].idxmin()]['Date']
max_date = df.loc[df['Close'].idxmax()]['Date']
plt.annotate('1年間最安値 ({:,.0f}円)'.format(min_price), xy=(min_date, min_price), xytext=(min_date, min_price*1.4),
arrowprops=dict(facecolor='black', arrowstyle='->'), fontsize=10)
plt.annotate('1年間最高値 ({:,.0f}円)'.format(max_price), xy=(max_date, max_price), xytext=(max_date, max_price*0.95),
arrowprops=dict(facecolor='black', arrowstyle='->'), fontsize=10)
# チャートのタイトルと軸ラベルを設定する
plt.title(f'{name}({code})')
plt.xlabel('Date')
plt.ylabel('日足終値')
# グリッド線を表示する
date_format = mdates.DateFormatter('%y-%m-%d')
plt.gca().xaxis.set_major_formatter(date_format)
#x軸ラベルの角度を変えたい場合は例えば rotation=45 のように設定する
plt.xticks(rotation=0)
# グラフにレジェンドを追加
plt.legend([line1,line2,line3],['日足終値','25日移動平均','300日移動平均'],loc="upper left")
# グリッド線を表示する
plt.grid(True)
# チャートを表示する
plt.show()
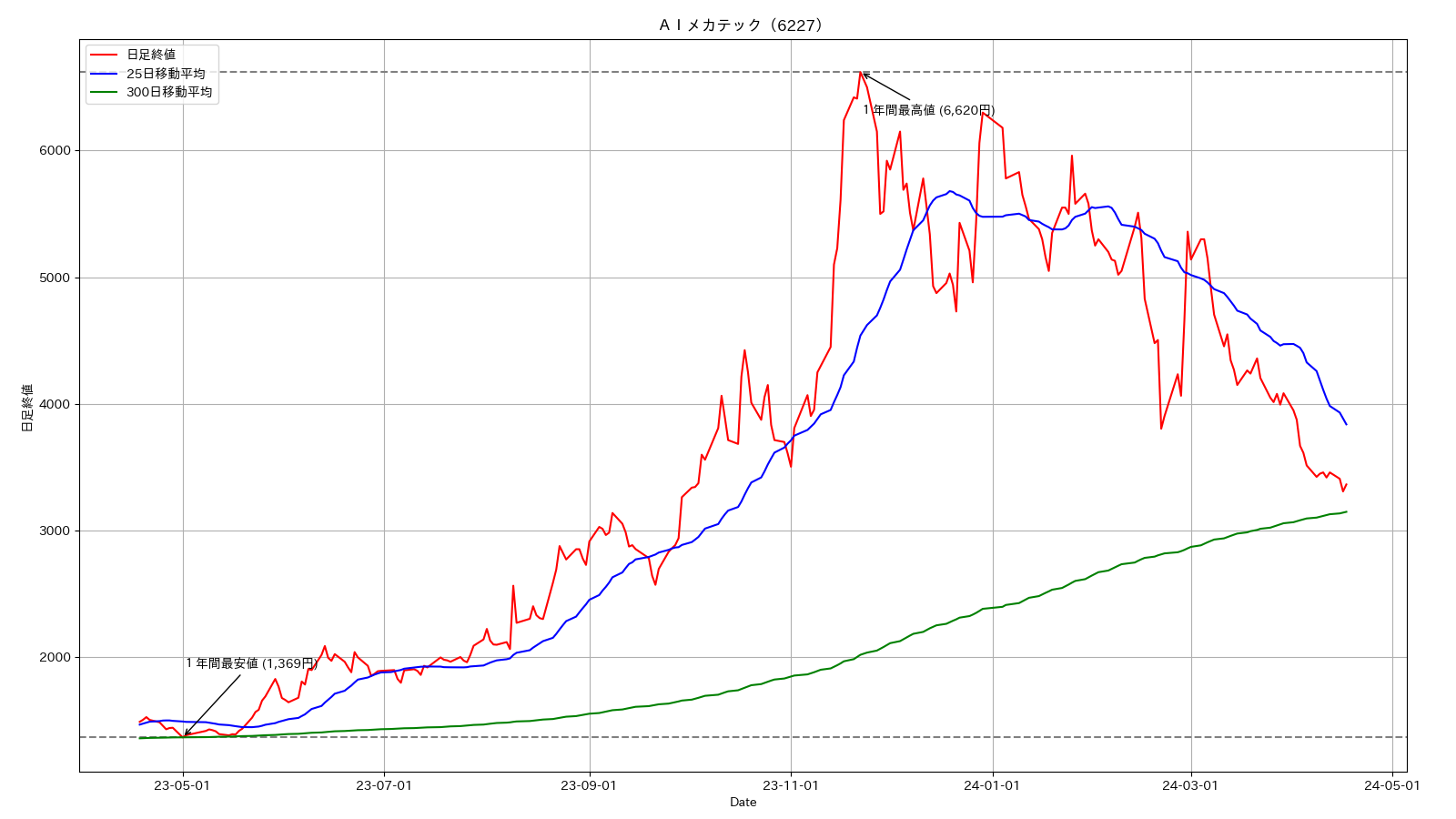
このチャートを見ると2023年は日足が25日線よりも上にある傾向が見えます。上昇トレンドが続いていると解釈できます。それに対し2024年に入ると一転して下降トレンドに入ったように見えます。このように移動平均をとることで大きなパターンを把握しやすくなるのが便利です。
この例のような株価データに対する移動平均のほかにも、実験データの統計的な性質を可視化するために「算術平均」をとる、あるいは機械学習で使われる画像データに対する畳み込み処理など、「平均をとる」という考え方はデータから傾向やパターンを把握するための代表的な数理的手法です。
2. 少し微妙なテクニカル分析#
移動平均を見ることで大きなパターンは見やすくなりました。ですが、売り買いをどうすればよいのかに関するわかりやすい情報は読み取れないので、ああそうかで終わりそうです。
一つこの答になりそうな技術があります。これは移動平均収束発散法(Moving Average Convergence Divergence,MACD)と呼ばれる可視化方法です。以下は前述と同じ銘柄をMACDにより可視化したものです。

この手法の具体的な説明は第5章に譲り、ここでは結論だけ書きます。MACDのチャートに書かれた縦線が売り買いのタイミングを示しています。「ダイバージェンス強気」が買いサイン、「ダイバージェンス弱気」が売りサイン、を示します。実は筆者はこの銘柄を、上昇トレンドの銘柄を検索していてたまたま目につき23年11月8日に3,905円で買いました。すると翌日9日には9%以上値上がりしたので4,267円で売却した経緯があります。
「もしも」筆者がMACDを売買の指標として忠実に使っていたとしたらどうなっていたでしょうか? 2023年10月はじめからチャートを運用しはじめたとします。チャート上での最初の「ダイバージェンス強気」線は11月9日に発生しています(10月3日の線は計算精度の不足により出た線のため除外)ので11月10日の始値4110円で100株購入します。そしてそのあとは株価が上昇しても下降してもジッとしています。すると11月30日「ダイバージェンス弱気」線が出たのその日の終値5920円で売却して取引をクローズさせます。損益は取引課税(20%)を考慮すると (5920-4110)×100×0.8 =144800円となります。
まさに捕らぬ狸の皮算用、に違いありませんがどこかで同じような境遇でこのやり方により、大きな利益を得た人もいることでしょう。 このようにMACDは株価のトレンドから売り買い判断サインを抽出してくれる有能なツールとして普及しています。
さて、筆者が言いたかったことはもう一つあります。 同じ銘柄のMACDチャートをさらに先(24年4月まで)伸ばしてみました。
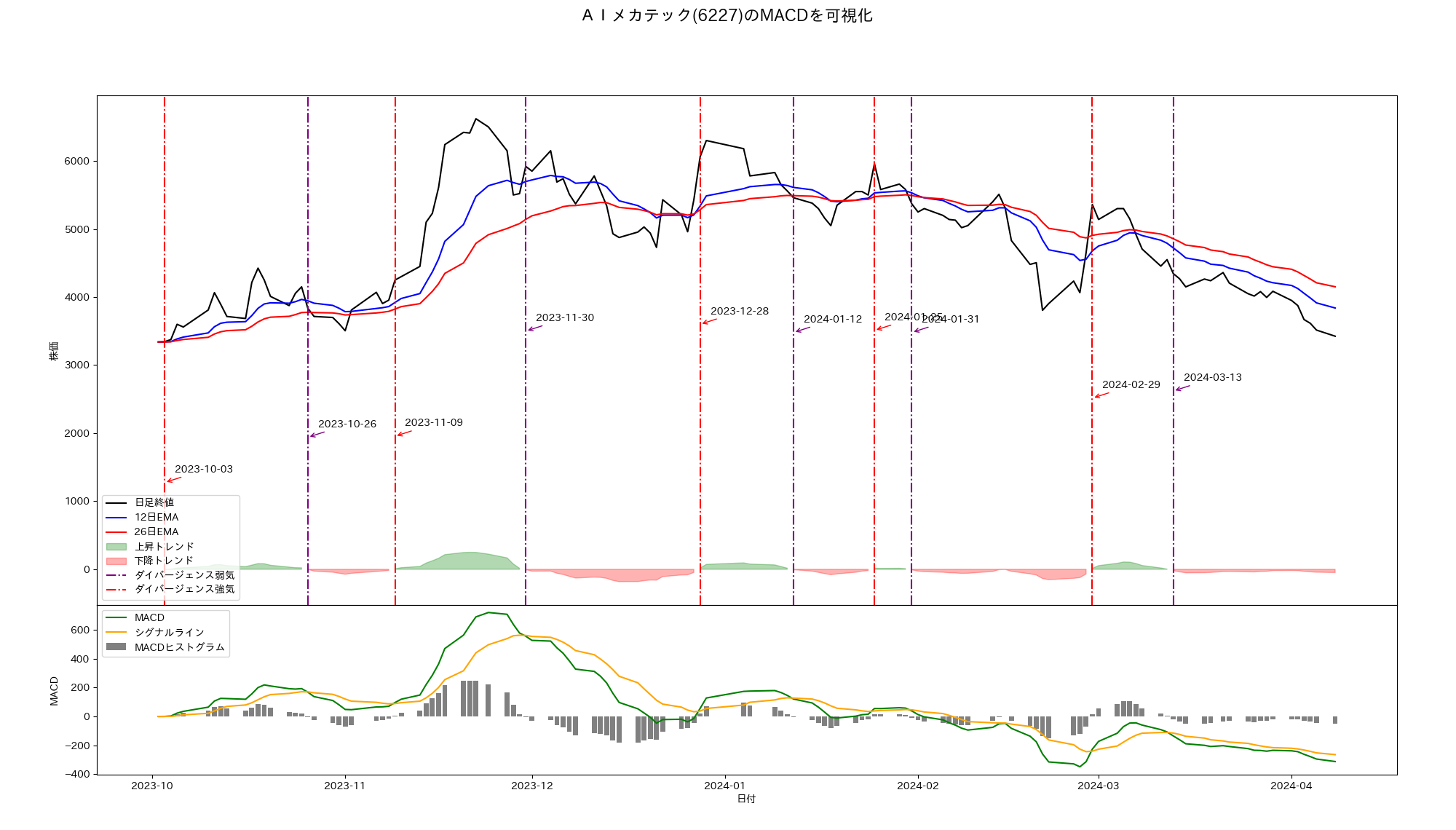
今度は筆者がこの銘柄を見つけて購入したのが1月初めであったとしましょう。話を簡単にするためにMACDをもとに同じ銘柄を3か月程度繰り返し売買するシミュレーションを行ってみると以下のようになります。強気シグナルで100株購入、弱気シグナルで全株売却を繰り返した結果を表示しています。

MACDに忠実にトレードした場合、大きく損失するというシミュレーション結果でした。やはりな、という感じもします。そもそも株価下降局面ではMACDのシグナルに頼るべきではなかったとも思いますが、現物の売り買いだけをする前提では株価の下降局面で利益を出すのは簡単ではないという感覚を強化する例になる結果です。仮の話ついでに、「この銘柄は下降局面に入った」と信じた投資家は、信用売りと買い決済を繰り返せば逆に利益を獲得できたでしょう。ただしその場合信用取引特有の別のリスクを背負いこむことになります。
このMACDのように株価の数値変動からパターンを抽出して分析する手法を一般にテクニカル分析、そこで使われる指標をテクニカル指標といいます。株価変動をいくら分析しても有効な予測は不可能であるという主張があります。その一方で何らかの予測可能性があるのではないかと考える人も多いです。投資家はそのために、さまざま存在するテクニカル指標をうまく取捨選択し活用することで取引を成功させる確率を大きくしていけるのではないか、という期待を持つわけです。
第5章ではMACDのほか代表的なテクニカル指標を紹介し、サンプルコードを使って指標の特徴を可視化していきます。その過程で数理的な手法がどのような視点で用いられているのか合わせて調べていこうと思います。
3. 時代を変えた数理#
金融商品取引を数理的な手法で高度化する研究領域は「数理ファイナンス」とか「金融工学」などと呼ばれています。この分野の歴史はけっこう古く、19世紀末あたりにはすでに先駆的な研究がなされていたようです。それが1950年代に入り確率論や統計学、計算機科学など周辺分野と交流しながら大きく発展したと言われています。
オプション取引という金融商品の取引手法があります。 前節で言及した取引の形態は現物売買あるいは信用取引に基づいています。すなわち現在株価で株式を購入(あるいは信用売り)し将来株価が上がった(下がった)とき株式を売却(買い戻し)することで利益を得ます。 これに対して金融派生商品(デリバティブ)の一種で、将来の資産価格を想定しその価格で指定期日になったら資産を購入(売却)できる権利を売り買いする手法をオプション取引と呼びます。これはいわゆる「先物取引」と似ていますが、先物取引では購入した権利は必ず実行するのに対してオプション取引では、権利を途中で放棄することが可能となっています。
前節では株価には予測可能性があるのではないか、と書きましたが、オプション取引商品(株式、為替、商品等)の理論的な資産価格を予測する手法を発見し実際のマーケットでその有効性を実証した人たちが1970年代に現れました。このとき開発された、確率過程論に基づくモデルは発案者の名前をとってブラック・ショールズモデルと呼ばれています。このエポックメイキングな手法の出現が金融商品取引に対して高度な数理を活用する流れを大きく加速させることになりました。 なお、オプション取引は個人投資家向けにもサービス提供されています。関心お持ちの方は、典型的なハイリスク商品であることをご理解のうえで証券会社サービスを調べてみるとよいです。
本書では数理が実務に大きな影響を与えたもうひとつの例として裁定取引の発展に焦点を当てようと思います。
3.1. 裁定取引とは#
商品取引市場では、一物一価である商品の価格が一時的に通常と乖離するタイミングが発生することがあります。これを「裁定機会」と呼びます。裁定機会が発生した時点で安く入手できる場所で商品を購入し、高く売れる場所で売却することで利潤を得る手法を「裁定取引」といいます。日本では鞘取り(さやとり)とも呼ばれています。
興味深いことに、先物取引ができる市場では現物取引と先物取引を組み合わせることで裁定取引により無リスクで利益を稼ぐことができる場合があります。この仕組みを説明しておきましょう。
先物取引では、先物価格として提示された価格で商品を将来時点(満期日)までに売り買いする権利が取引されます。例えば原材料を仕入れて加工商品化する事業者にとっては、原材料価格の予期しない価格変動リスクを避けるために、先物取引により原材料を想定価格で入手できる「リスク回避効果」があります。また投機家にとっては現在の先物価格と比べ将来の商品価格が上昇するはず、と信じて先物取引により権利を買い、見込み通り価格が上昇した時点で権利を売却することにより利益を得る「投機的利益効果」があります。
先物商品の例として、日本取引所グループが提供する「日経225先物」を取り上げましょう。この商品の理論価格は以下の式で与えられます。

実際に何か異常なことが起きない限りこの理論価格通りに先物売買が行われると言われています。しかしながら、先物は市場で取引される商品であるため需要と供給の突発的な変動により理論価格の乖離が発生することがあります。
大口取引の突然の発生等、何らかの理由で理論式とくらべ先物価格が高く乖離することがおきたとしましょう。するとこの事象を発見したトレーダーは、先物を売り建てすると同時に現物を購入します。そして先物の満期日が到来すると上記の理論価格通りに裁定機会は解消されます。このタイミングで先物を買い戻すと同時に保有現物を売却します。この結果以下の図にように満期日の現物価格がどのような値になっていても当初の裁定機会で発生したギャップ分を利益として確定させることができます。
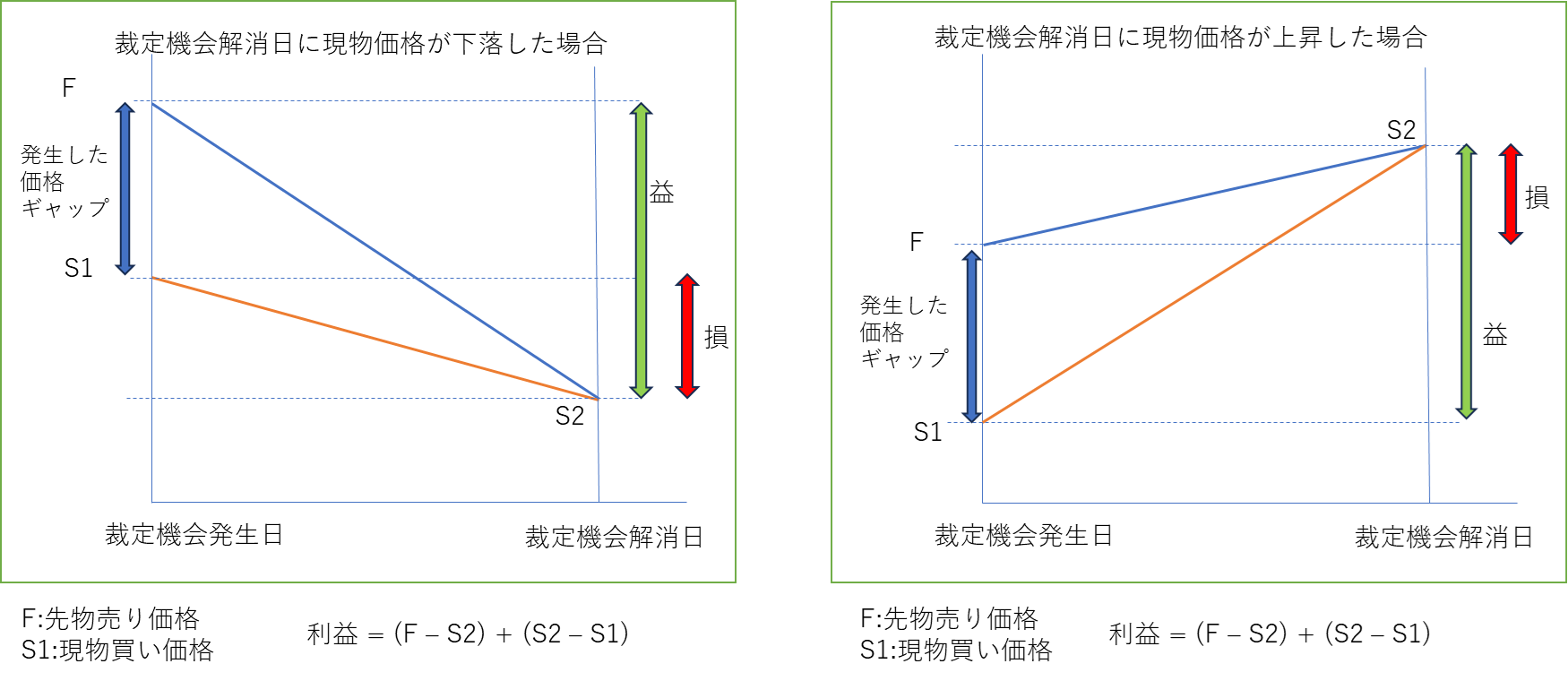
日経225先物による裁定取引は、常に裁定機会の発生を見張り発見次第瞬時に行動する必要と、ペアにする現物の取引を行うために日経225の構成株を同じ比率で購入する資金の必要がありますので、証券会社内の裁定取引部門のトレーダーがすぐさま対応することが通例のようです。そのため個人投資家には裁定機会の活用は困難であると思われます。
3.2. ペアトレーディングを試す#
日経225先物においては取引に満期日が設定され満期日には理論価格と現物価格が一致する仕組みのおかげで裁定取引が成立することがわかりました。一方、通常の株式取引においても似たような考え方で利益を出すペアトレーディングとよばれる手法があります。
ペアトレーディングでは似たような価格変動パターンを示すふたつの銘柄を市場から探し出します。「似たような」は、数学的に定義することができ、「共和分(cointegration)」といいます。定義は第3章で行うとしてここではまず共和分性をもった銘柄ペアの例をあげてみます。同じ業種に属する銘柄が探しやすいようで海運業を調べてみると日本郵船と商船三井が見つかりました。両者は相似形といってよいほど似た値動きをしていることがわかると思います。
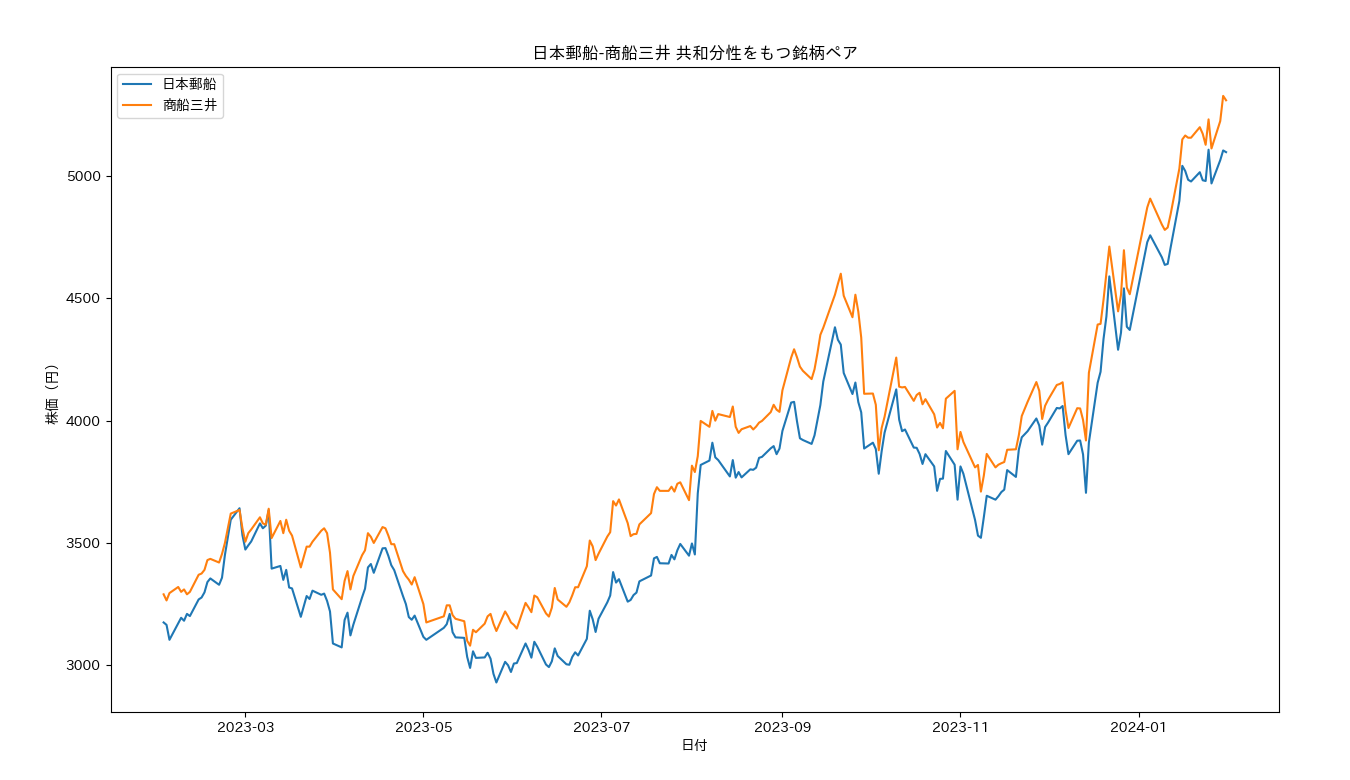
Xを日本郵船の株価、Yを商船三井の株価としたとき、両者の株価のスプレッドを以下のように定義します。mean(X-Y)を株価の差異の平均値として、 \begin{align} spread = Y - X - mean(Y-X) \end{align} スプレッドは以下のプロットに見るようにランダムに変動しているのですが、共和分性をもつ銘柄ペアにおいては、スプレッドの値が平均からはずれたところ(例えば以下プロットの2*sigmaの線)に変位したとしてもいづれ平均値に戻る、いわゆる「平均回帰性」を示すことが数学的に証明されています。この「平均から外れたところ」を裁定機会とし、平均に回帰したところが裁定機会の解消ととらえ、売りと買いを組み合わせるのがペアトレーディングの考え方です。
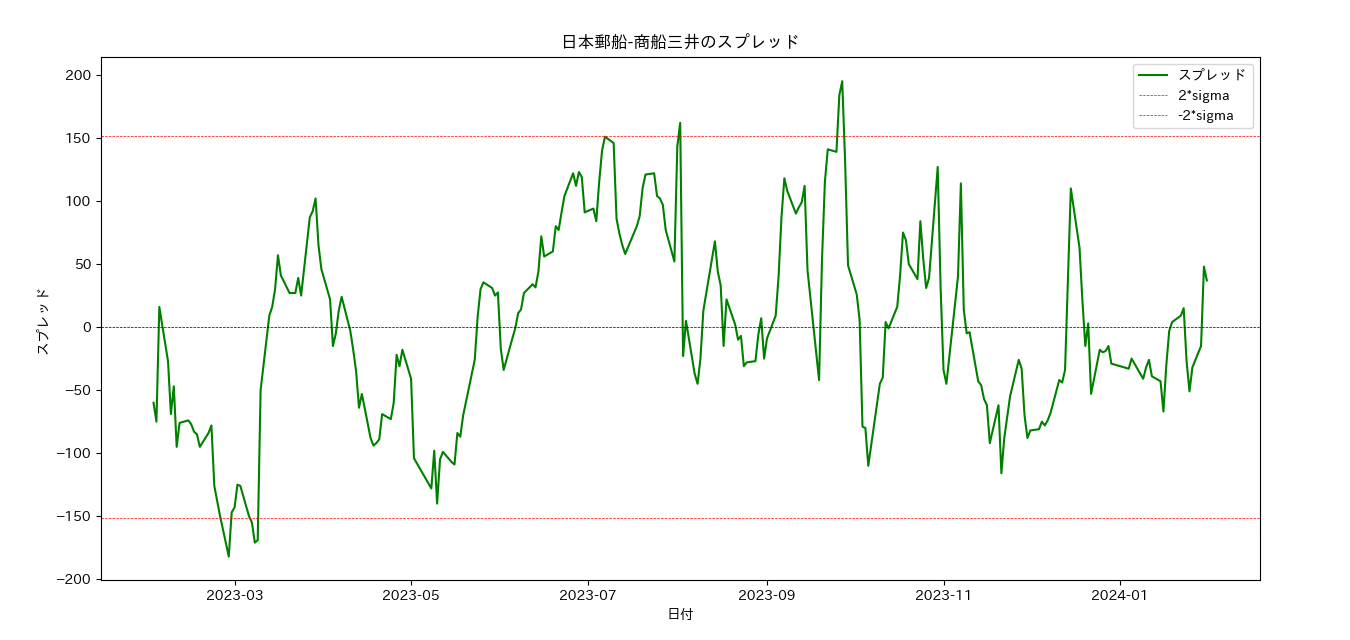
具体的な方法は以下の通りです。
- スプレッドが平均よりも上に大きく変位したとき Y を売り建て、X を現物買いします。
- スプレッドが平均に回帰したとき Y を買い決済し、X を現物売りし取引をクローズします。
スプレッドが平均よりも下に大きく変位した場合はXとYを入れ替えて同じように取引を行います。この取引で得られる利益は以下となります。

裁定取引のところで説明したことと同じ構図により、取引開始時点から終了時点へかけてスプレッドが縮小すれば必ず利益を得ることができます。この形の取引を次々と繰り返すシミュレーションを行った結果を見てみましょう。以下のプロットで赤い縦線が取引の開始、緑の縦線が取引の終了を示しています。
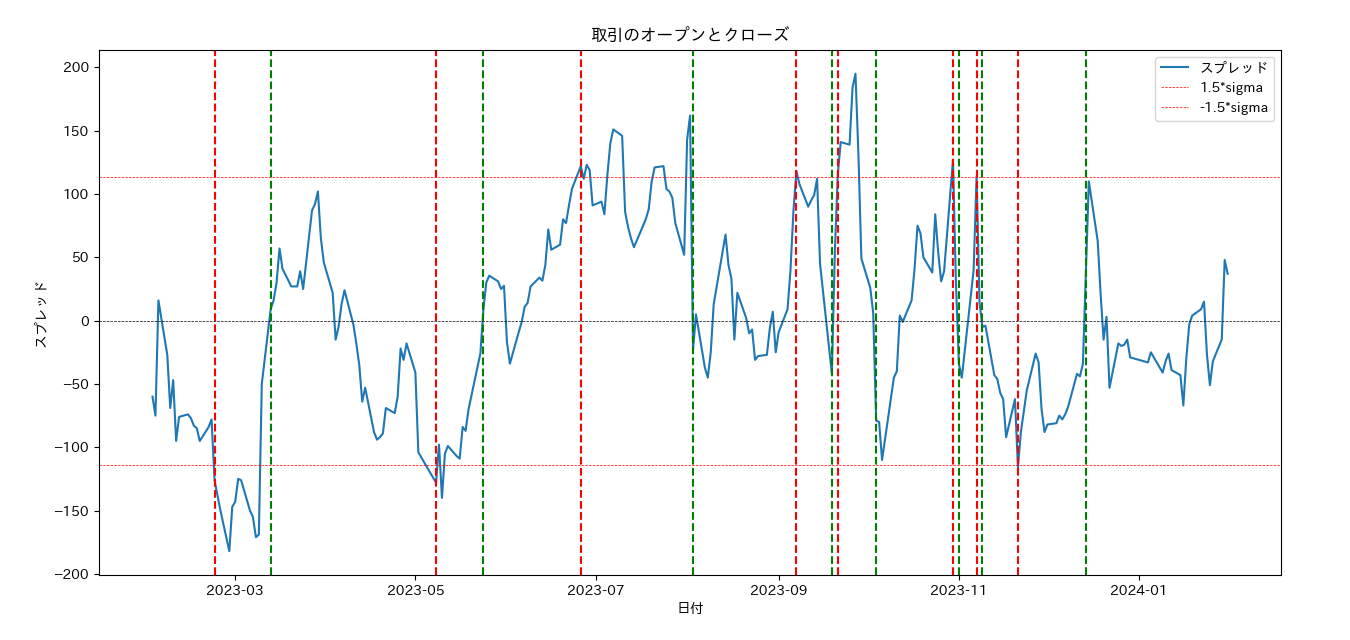
以下は各取引の履歴です。

ペアトレーディングを行う場合、売りは信用取引となるため証券会社の口座に一定の保証金を積む必要があります。この例ではそれを33%としています。さらに買い決済のときに取引手数料が発生します。これは1000円とおきました。また取引利益に課される税が20%発生するのでこれらを含め取引コストとして利益を算定しています。
4000円程度の株価のペアの場合、現物購入資金と信用取引保証金をあわせて53万円程度の原資が必要となります。その場合得られた利回りは15%を超えるのでよい結果といえるのではないでしょうか。
さて、このペアトレーディングですが、個人として試してみる場合以下がハードルになりそうです。
- 選択したペアが共和分性を示していたとして、明日以降も共和分であり続ける保証はどこにもないこと。実際ここで例とした日本郵船と商船三井は時間軸を2024年4月まで進めてみたところ共和分性を示しませんでした。
- 共和分性をもつ銘柄ペアを探索する手間がかかること。手探りで見つけるのは時間の無駄と思われます。ただし探索プログラムを自動化するコードは割と容易につくることはできるのでマシンパワーを保有する人は対処可能なハードルではあります。
ペアトレーディングは、先物の裁定取引とは異なり裁定機会を見つけてトレードを開始した時点で利益が確定できるようにはなっていません。 しかしながら統計的推論や時系列分析を利用することで取引候補となる銘柄を発見し、裁定機会の発生と解消を定量的に把握することができます。これは数理的手法の大きなメリットであると思われます。本書の第2章以降で数学的な道具立てを準備し、第6章で、ここで扱った手法の数学的な肉付けをコードをまじえフォローすることで数理的手法の価値を体感していきましょう。
補足1#
Yahoo Finance US から株価データをダウンロードする#
ここで記載する対策の出典として、以下サイトを参照しています。
Reddit - Dive into anything ( https://www.reddit.com/r/sheets/comments/1farvxr/broken_yahoo_finance_url/ )
例えばダウンロードしたいデータが極洋(1301.T)であり、期間が2024年1月4日~3月31日、日足データであるとします。
開始日時と終了日時をUNIX時間で表現します。このためには日時の変換サイト(例:keisan.casio.jp )を利用すると簡単です。
2024年1月4日0時0分 → 1704294000
2024年3月31日0時0分 → 1711810800
次のようにURLを構成し、ブラウザでアクセスします。
https://query2.finance.yahoo.com/v8/finance/chart/1301.T?period1=1704294000&period2=1711810800&interval=1d&events=history
ブラウザ画面に付加情報がいろいろついたjsonフォーマットのデータが表示されます。このデータを、Windowsであればマウス右クリックして表示されるコンテキストメニューから、「名前を付けて保存..」を選択して適当なディレクトリへ保存します。ファイル名は例えば「1301.json」しておきます。
以下のコンバートプログラムを書き、Macのターミナルや、Windowsのコマンドプロンプト画面で実行すると、扱いやすいcsvファイルにすることができます。
#
# convert_json.py
#
import pandas as pd
import json
def conv_df(j):
data = [j['chart']['result'][0]['timestamp']] + list(j['chart']['result'][0]['indicators']['quote'][0].values())
df = pd.DataFrame(
{'timestamp': data[0], 'Close': data[1], 'Open': data[2], 'High': data[3], 'Low': data[4], 'Volume': data[5]})
df['Time'] = pd.to_datetime(df['timestamp'], unit='s')
df['Date'] = df['Time'].apply(lambda x: x.strftime('%Y-%m-%d'))
return df
f = open('1301.json', 'r', encoding="utf-8")
data = json.load(f)
f.close()
df = conv_df(data)
# 必要なカラムを選び、順序を指定
df_reordered = df[['Date', 'Open', 'High', 'Low', 'Close', 'Volume']]
# CSV出力 (indexを無しに設定)
df_reordered.to_csv('1301.csv', index=False)
補足2 yahoo_fin から yfinance へ移行するために#
yahoo_fin と yfinance はデータダウンロード関数の呼び出し、戻り値に違いがあります。本稿ではyahoo_fin をごくシンプルな使い方をしているため、以下第2項に示す移行用の関数へ置き換えることでコードは正常に動作します。
1 基本的な違い#
yahoo_fin
from yahoo_fin import stock_info as si
df = si.get_data(
code,
start_date="2023-12-07",
end_date="2024-12-06",
interval="1d",
index_as_date=False
)
特徴
- ダウンロード関数は
get_data()
yfinance
import yfinance as yf
df = yf.download(
code,
start="2023-12-07",
end="2024-12-06",
interval="1d"
)
特徴
- ダウンロード関数は
download()
戻り値の違い
yahoo_fin
date, open, high, low, close, adjclose, volume, ticker
date は日付が入ったカラムです。
yfinance
Date, Open, High, Low, Close, Adj Close, Volume
Dateはカラムではなく、index(DatetimeIndex)です。
2. 置き換え関数を利用した移行#
依存関係で問題が起きないよう、yahoo_finは事前にアンストールします。
pip uninstall yahoo_fin
yfinanceをインストールします。
pip install yfinance
置き換え用関数です。
#
# yahoo_fin -> yfinance 移行用関数
#
import pandas as pd
import yfinance as yf
def get_data(code, index_as_date=True, start_date=None, end_date=None, interval="1d"):
df = yf.download(code, start=start_date, end=end_date, interval=interval)
# MultiIndex対策
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
df.index = pd.to_datetime(df.index)
df = df.rename(columns={
"Open": "open",
"High": "high",
"Low": "low",
"Close": "close",
"Adj Close": "adjclose",
"Volume": "volume",
})
if not index_as_date:
df = df.reset_index().rename(columns={"Date": "date"})
df["ticker"] = code
return df
ダウンロード関数を実行している個所を移行用関数で置き換えます。
移行前
# pre_yfin_before.py
#
# 個別企業の場合には証券コードに.Tを付加する
code = "6227.T"
name = "AIメカテック"
start_date = "2023-12-07"
end_date = "2024-12-06"
df = si.get_data(code, index_as_date = False,start_date=start_date, end_date=end_date,interval='1d')
# csv出力。小数点以下は2桁までとする。
df.to_csv(f"{code}.csv", float_format='%.2f', index = False)
移行後
# pre_yfin_after.py
#
import pandas as pd
import yfinance as yf
def get_data(code, index_as_date=True, start_date=None, end_date=None, interval="1d"):
df = yf.download(code, start=start_date, end=end_date, interval=interval)
# MultiIndex対策
if isinstance(df.columns, pd.MultiIndex):
df.columns = df.columns.get_level_values(0)
df.index = pd.to_datetime(df.index)
df = df.rename(columns={
"Open": "open",
"High": "high",
"Low": "low",
"Close": "close",
"Adj Close": "adjclose",
"Volume": "volume",
})
if not index_as_date:
df = df.reset_index().rename(columns={"Date": "date"})
df["ticker"] = code
return df
# 個別企業の場合には証券コードに.Tを付加する
code = "6227.T"
name = "AIメカテック"
start_date = "2023-12-07"
end_date = "2024-12-06"
df = get_data(code, index_as_date = False,start_date=start_date, end_date=end_date,interval='1d')
# csv出力。小数点以下は2桁までとする。
df.to_csv(f"{code}.csv", float_format='%.2f', index = False)